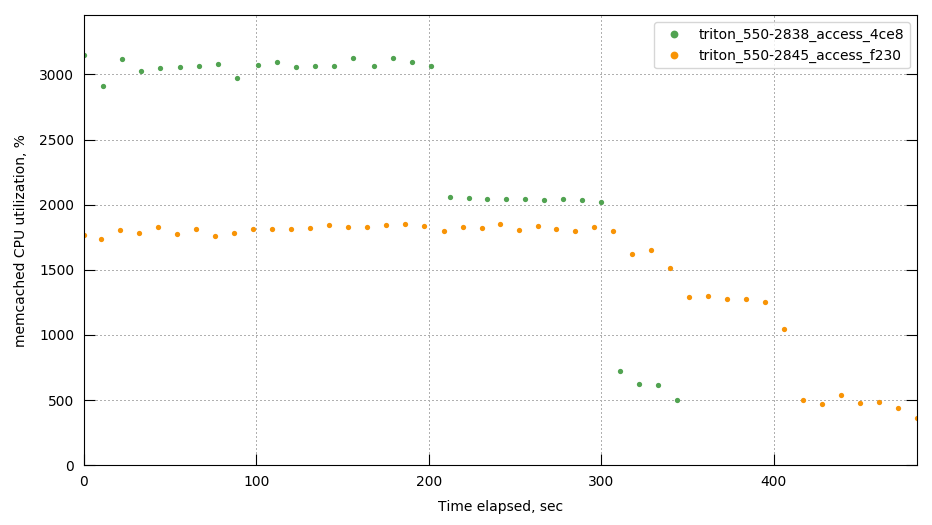
MB-28941 Session tracing has too high an impact on pillowfight 80/20 throughput
MB-29932 get and set latencies regression seen during perf rebalance tests
CCBC-1064 12% drop in pillowfight throughput (80/20 scenario) in libouchbase 3.0.0-beta.2 version
Bug
 Major
Major

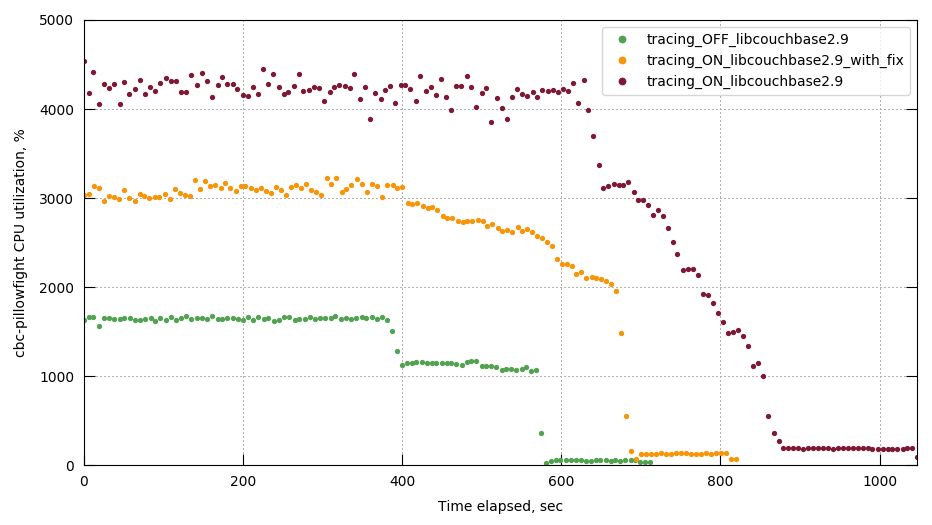
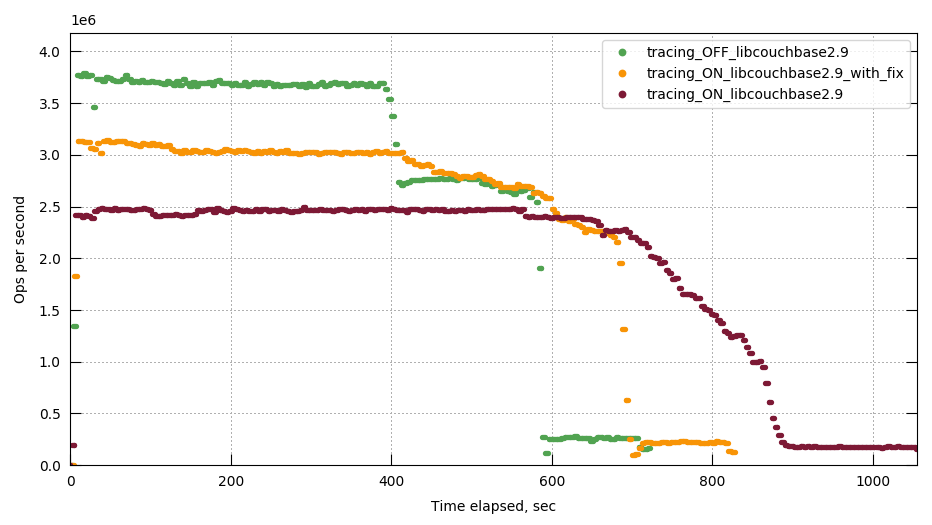
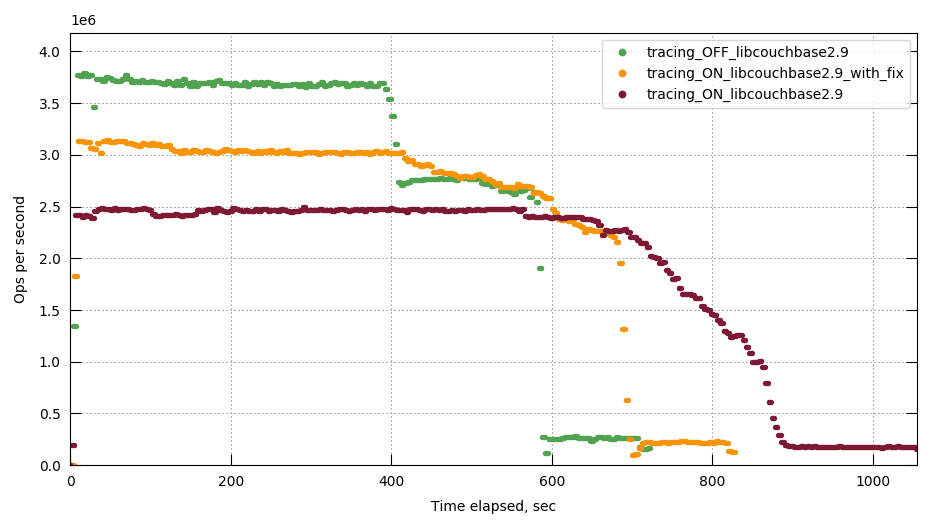
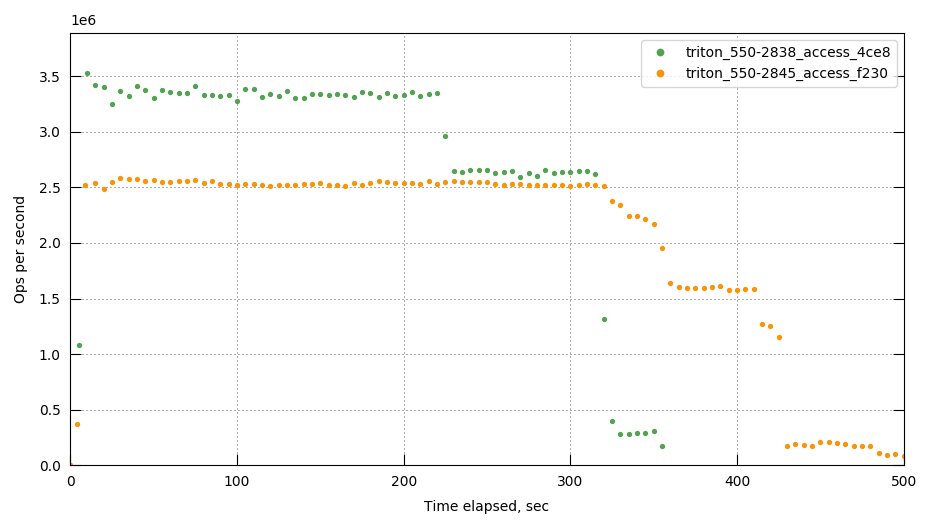

{kind=link}
{kind=link}
{kind=link}