Details
-
Improvement
-
Resolution: Fixed
-
 Test Blocker
Test Blocker
-
4.0.0
-
Security Level: Public
Description
The mapping phase of the mapreduce takes a lot of memory if there are a lot of emits per document
are happening.
Here's how to see this behaviour.
1. Run a single node ./cluster_run cluster with 8 vBuckets:
COUCHBASE_NUM_VBUCKETS=8 ./cluster_run -n 1
./cluster_connect -n 1
2. Load 100000 items with cbworkloadgen (feel free to increase that number if the indexing finishes too fast):
./cbworkloadgen -n localhost:9000 -i 100000 --size=10
3. Create a dev view which emits a lot of KV pairs (in this case 100 per document):
curl -X PUT "http://emil:9500/default/_design/dev_foo" -H 'Content-Type: application/json' -d '{"views":{"bar":{"map":"function (doc, meta) {\n for(var i=0; i<100; i++)
{\n emit([meta.id, i], null);\n }\n}"}}}'
4. Query the full set:
curl -X GET 'http://emil:9500/default/_design/dev_foo/_view/bar?stale=false&inclusive_end=true&connection_timeout=60000&limit=10&skip=0&full_set=true
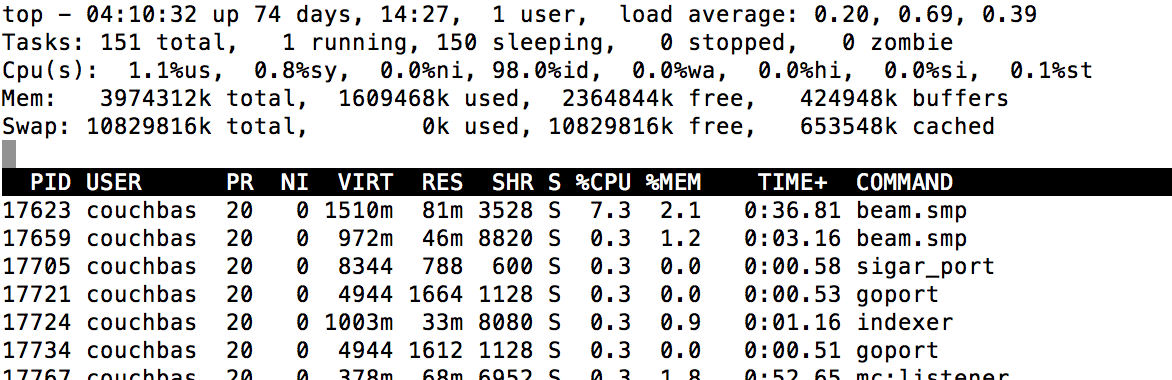
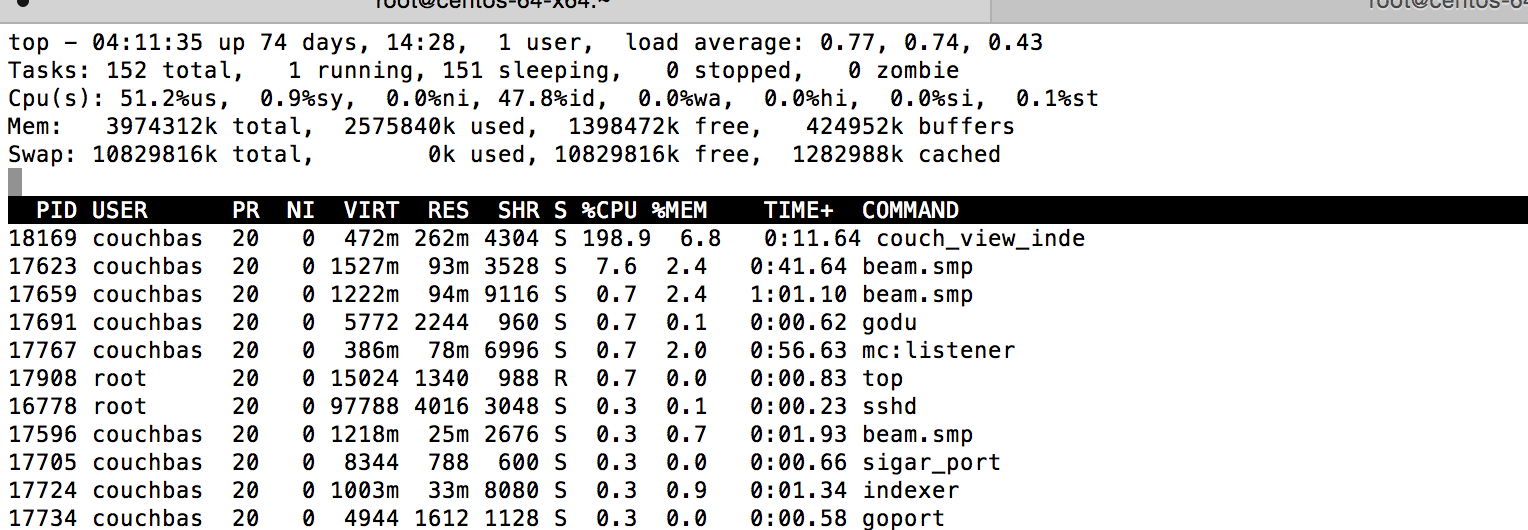
5. Watch the memory usage:
pidstat -r -p `pgrep -f '/beam.smp -P 327680'` 1
Depending on how much KVs you emit (you can e.g. also try 10 or 1000 in the for loop), it will take more or less memory. When the indexer is finished, the memory usage goes back to a sane amount.
Within the view engine we have maximum queue sizes. In this case the one that matters is the `MAP_QUEUE_SIZE` in `couch_set_view_updater.erl` [1]. It's currently set to 256KB. When it's increased, the memory consumption will increase, if you decrease it, also the memory consumption will get lower.
Something during the mapping takes a lot of memory. This should be reduced (if possible) to a minimum.
Attachments
Issue Links
- blocks
-
MB-16413 3.1.2 Minor Release
-

- Closed
-