Details
-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
4.0.0
-
Security Level: Public
-
centOS 6.x, 4 cores, 15Gb RAM - each node
-
Untriaged
-
-
Unknown
Description
Build
4.0.0-1767
Clusters
-----------
C1 : http://172.23.105.44:8091/
C2: http://172.23.105.54:8091/
The clusters are available for investigation.
What we do in XDCR System test
------------------------------
1. Load on both C1[8 nodes], C2[8 nodes] till vb_active_resident_items_ratio < 50 on standardbucket, <70 on standardbucket1.
2. Create xdcr:
C1.standardbucket <--> C2.standardbucket , no filter
C1.standardbucket1 --> C1.standardbucket1 , no filter
no replication on sasl bucket.
2. Access phase with 98% gets, 2%sets runs for 3 hours
3. Rebalance-out 1 node at cluster1 with workload
4. Rebalance-in the same node with workload
5. Failover one node with workload. Rebalance failed here, but I will file a different bug for the same. This run of system test stopped here.
Ideally system test does not end here. We do the same set of operations on C2 with workload, followed by warmup of both clusters. Please note, compaction is not disabled and given the high workload, keeps running often.
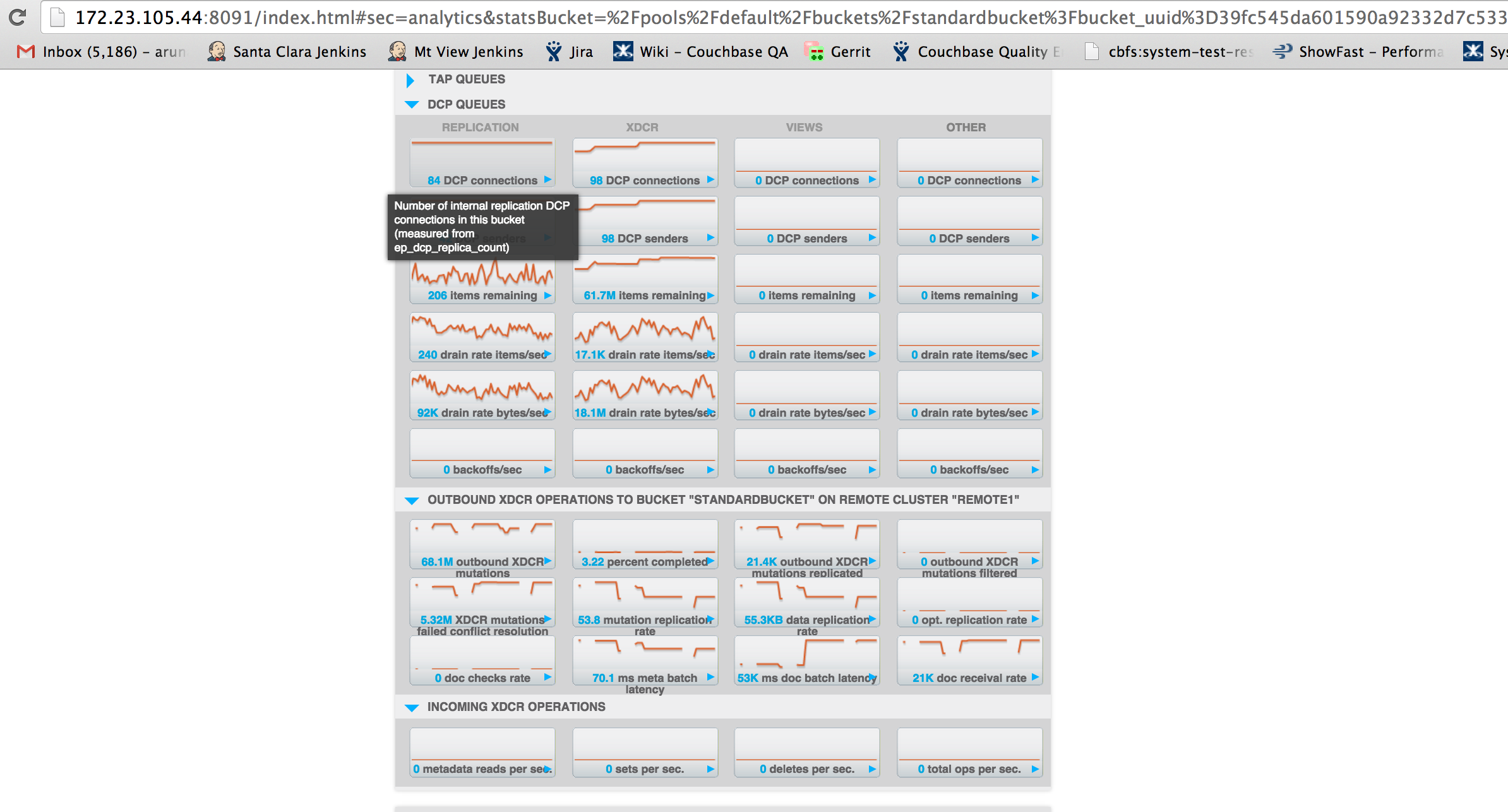
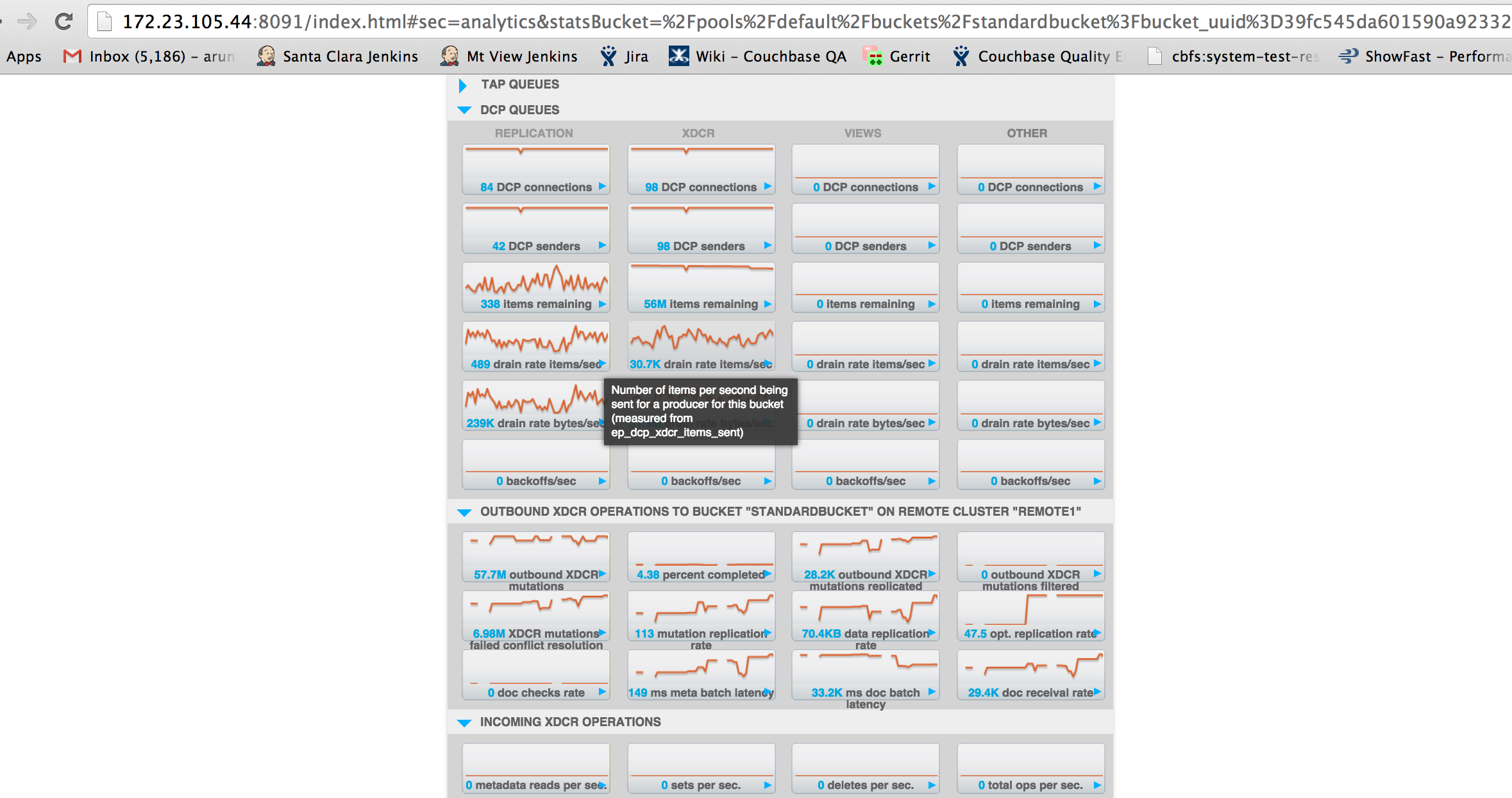
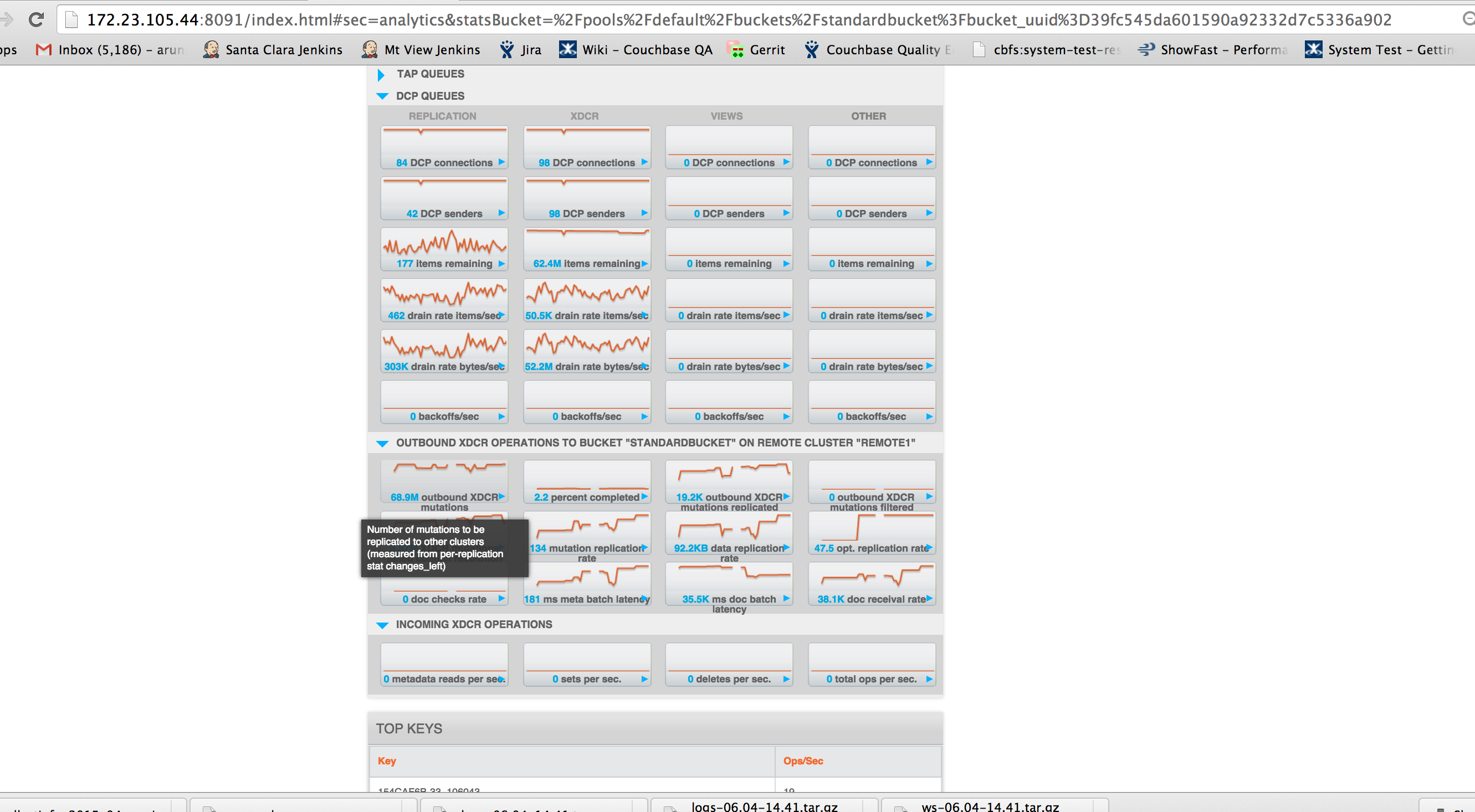
The problem here is that replication is extremely slow.
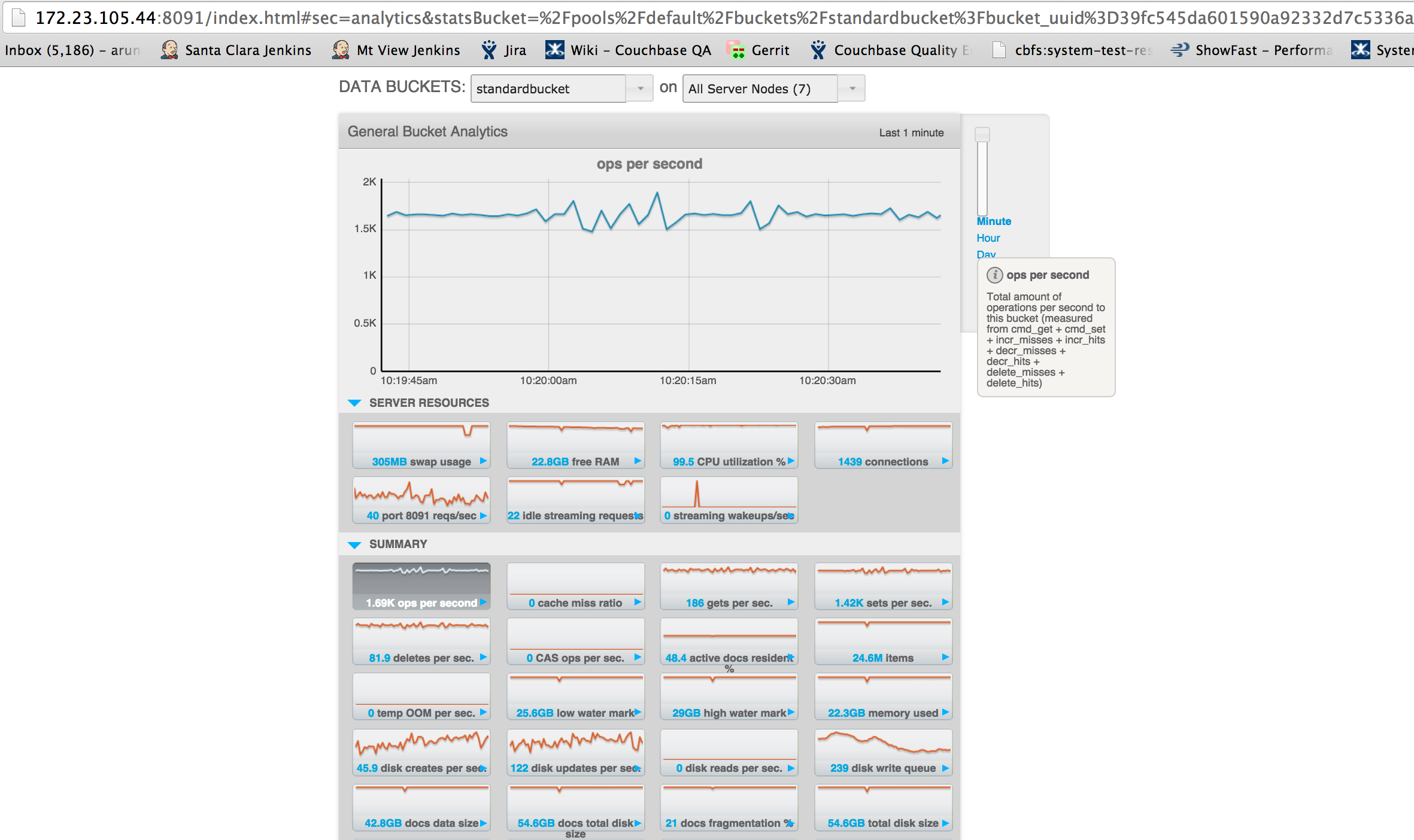
See bucket: standardbucket
eviction_policy : value only
active_resident_ratio : 48.4%
memory allotted : 5GB per node,currently 7 nodes so ~35GB, high watermark not reached.
current mem usage: 22.3GB
doc receival rate : 21K
mutation replication rate : 38.1
Attached 3 different set of screenshots of slow replication and one for bucket memory usage.
Attaching logs from C1 and C2. I also see multiple repeated goxdcr crashes. Will create a separate issue for the same. Also see 98 dcp connections for xdcr. Will log another MB for it. Thanks.
Attachments
Issue Links
- duplicates
-
-
- Closed
-