Details
-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
3.1.6
-
Untriaged
-
Yes
Description
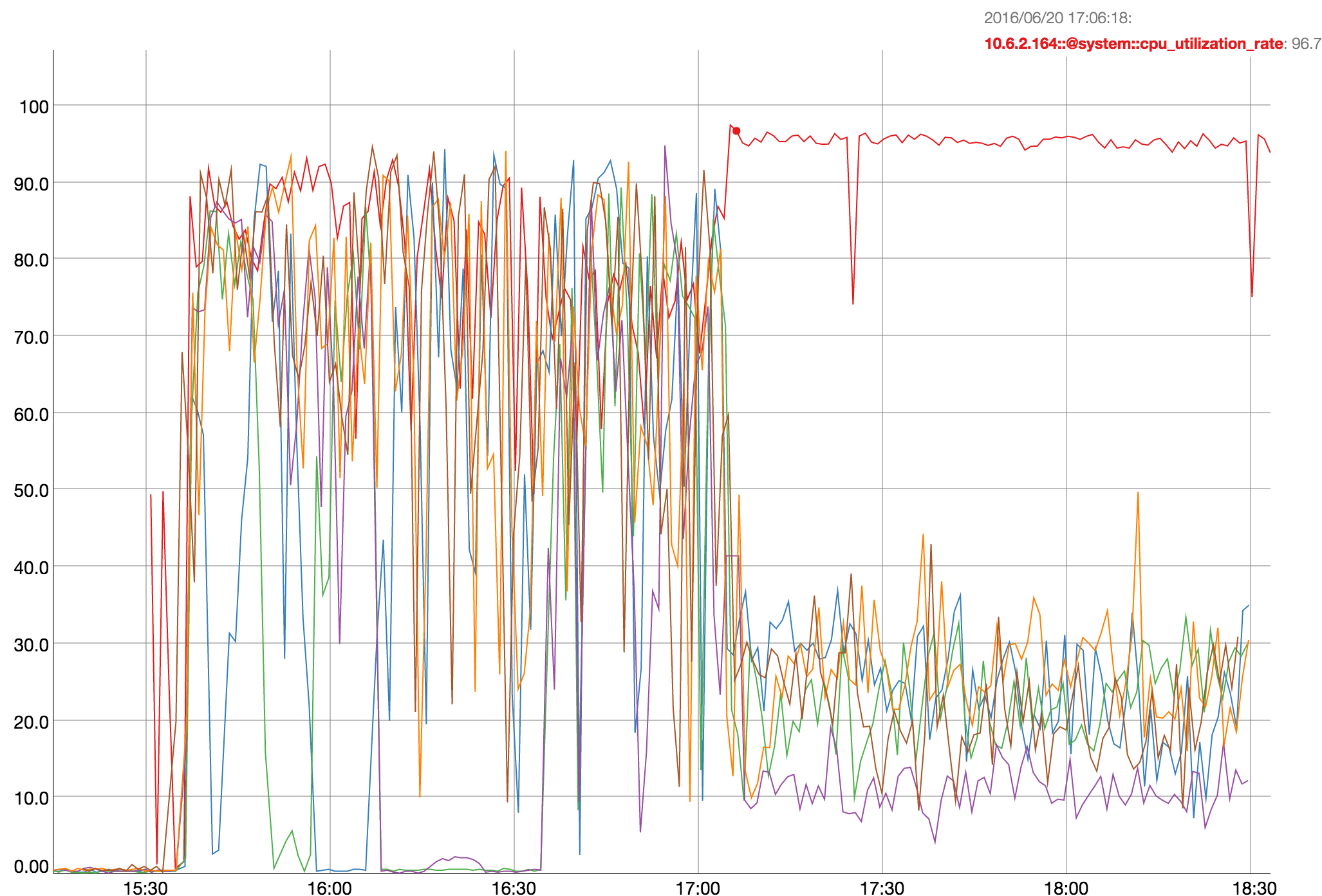
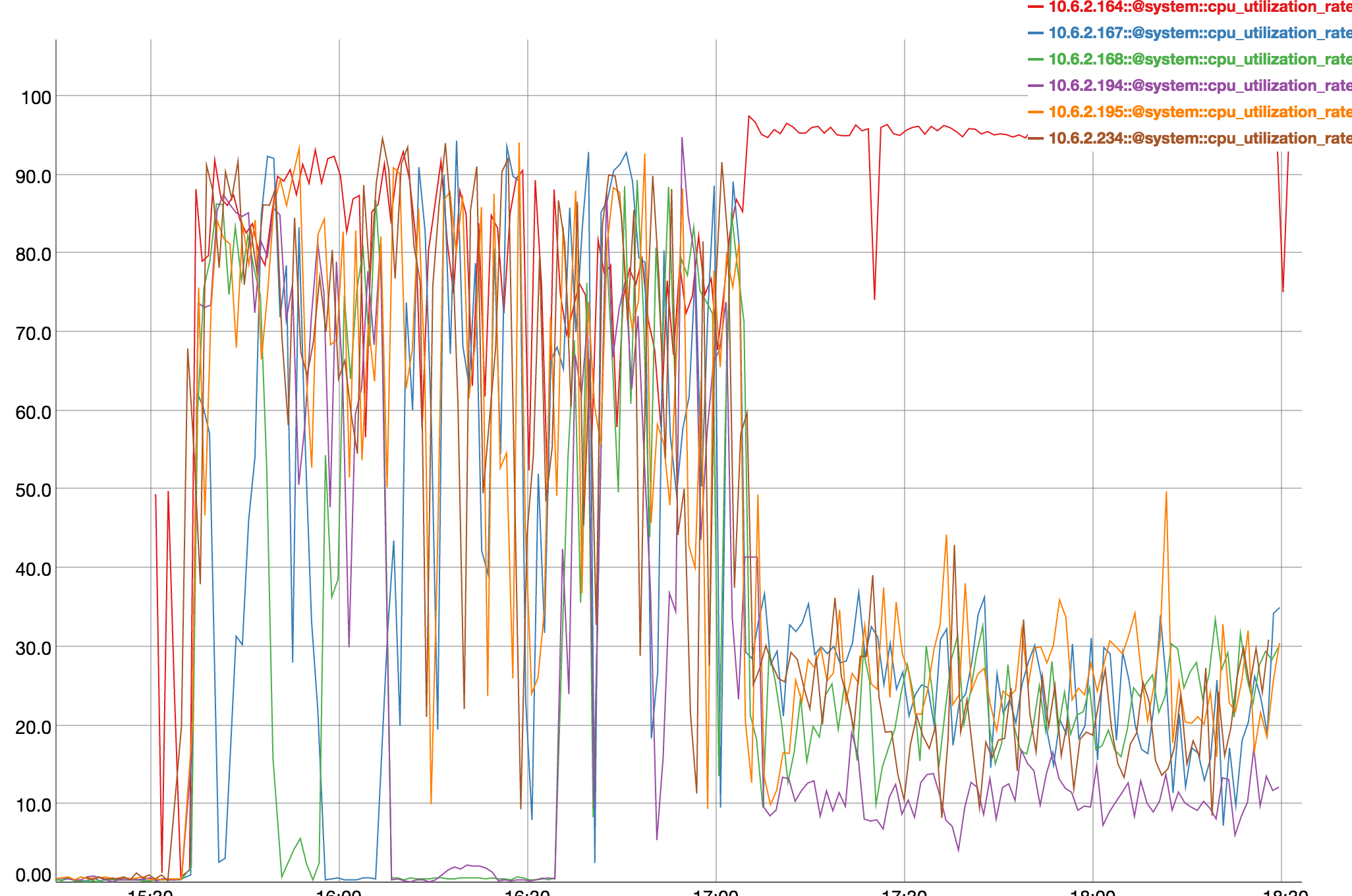
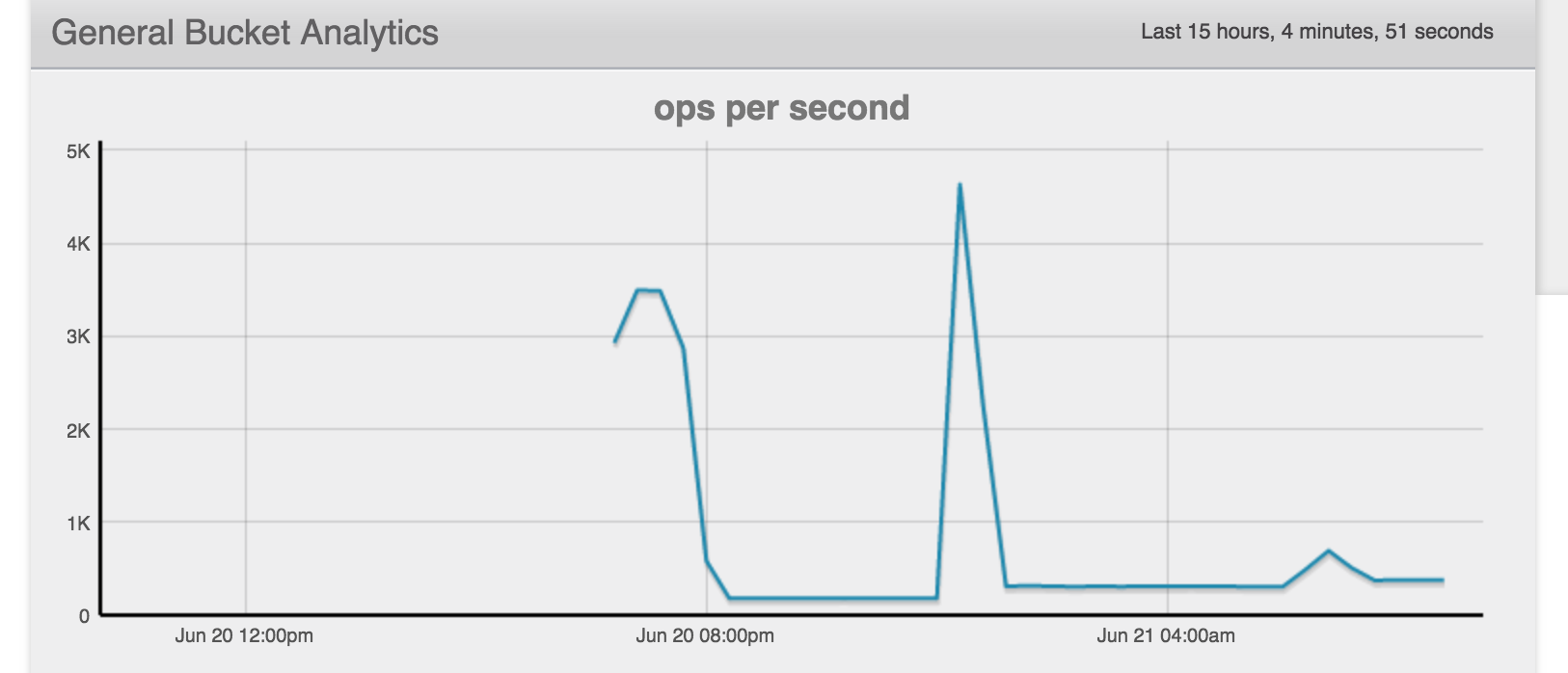
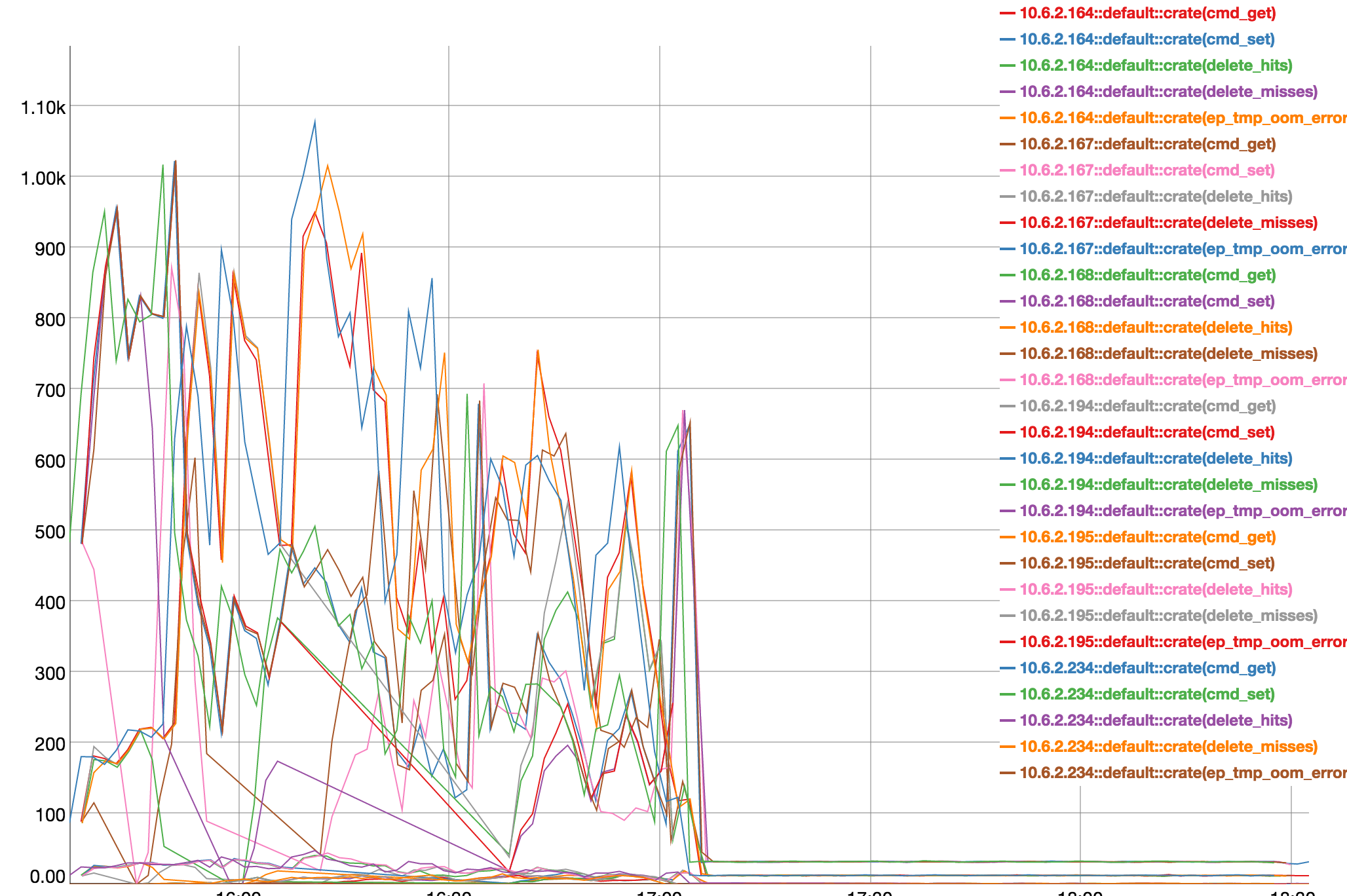
Connection was lost to memcached 3 hours into test. From the mortimer chart, ops were low (1k per node) as I wanted to make sure cluster wasn't being overcommitted.
at 17:04:27 - Mon Jun 20, 2016
Control connection to memcached on 'ns_1@10.6.2.194' disconnected: {badmatch,
|
{error,
|
timeout}}
|
At this time on node 194 there where timeouts attempting to persist seqno's
Mon Jun 20 17:04:12.414905 PDT 3: 150: Slow CMD_SEQNO_PERSISTENCE operation on connection: 31001 ms
|
Mon Jun 20 17:04:23.736957 PDT 3: (other) Notified the timeout on seqno persistence for vbucket 271, Check for: 2867, Persisted upto: 2866, cookie 0x5a71200
|
Mon Jun 20 17:04:23.737494 PDT 3: 144: Slow CMD_SEQNO_PERSISTENCE operation on connection: 31005 ms
|
Mon Jun 20 17:04:34.358839 PDT 3: (other) Notified the timeout on seqno persistence for vbucket 270, Check for: 2808, Persisted upto: 2807, cookie 0x5a27c00
|
Mon Jun 20 17:04:37.207809 PDT 3: (other) Notified the timeout on seqno persistence for vbucket 259, Check for: 3071, Persisted upto: 3045, cookie 0x5a25e00
|
Mon Jun 20 17:04:43.416048 PDT 3: (other) Notified the timeout on seqno persistence for vbucket 269, Check for: 3038, Persisted upto: 3037, cookie 0x5a26d00
|
Mon Jun 20 18:17:05.323387 PDT 3: Failed to notify thread: Resource temporarily unavailable
|
Mon Jun 20 18:17:07.828676 PDT 3: Failed to notify thread: Resource temporarily unavailable
|
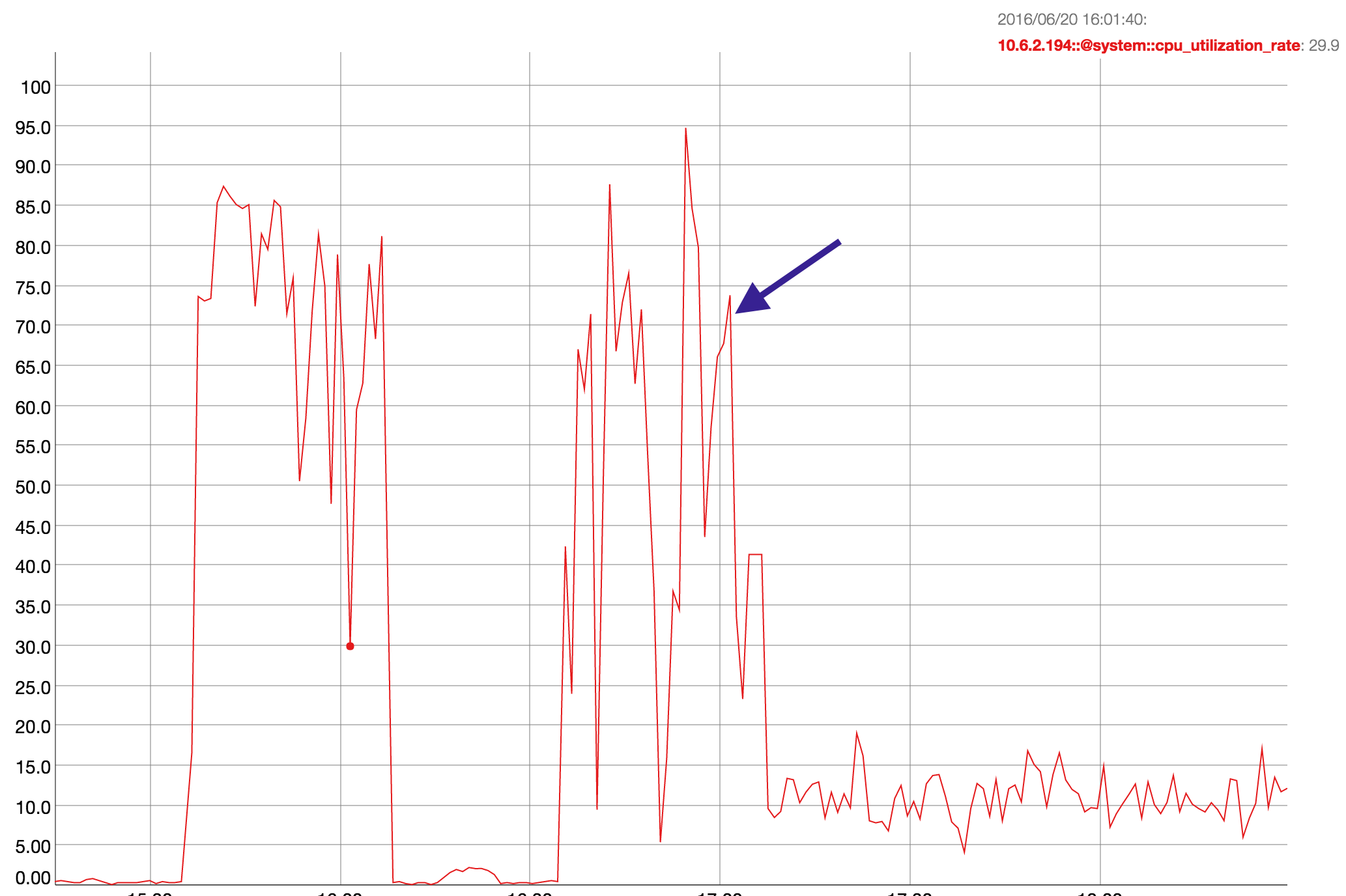
I plotted cpu with mortimer and this node was around 70% and dropping at this time (see attached) There was also a spike on orchestrator at time of rebalance start.
As I recall this behavior did not occur in 3.1.5, am verifying
Attachments
Issue Links
- blocks
-
MB-19323 3.1.6 release
-

- Closed
-