Details
-
Bug
-
Resolution: Cannot Reproduce
-
 Critical
Critical
-
5.0.0
-
Untriaged
-
-
Unknown
Description
Build
4.5.0-0888
Testcase (new)
./testrunner -i INI_FILE.ini -p get-cbcollect-info=True,get-coredumps=True,get-logs=False,stop-on-failure=False,cluster=D:F:F,GROUP=DGM -t fts.stable_topology_fts.StableTopFTS.create_simple_default_index,cluster=D,F,D+F,dgm_run=1,active_resident_ratio=10,eviction_policy=fullEviction,moss_compact_threshold=20,GROUP=DGM
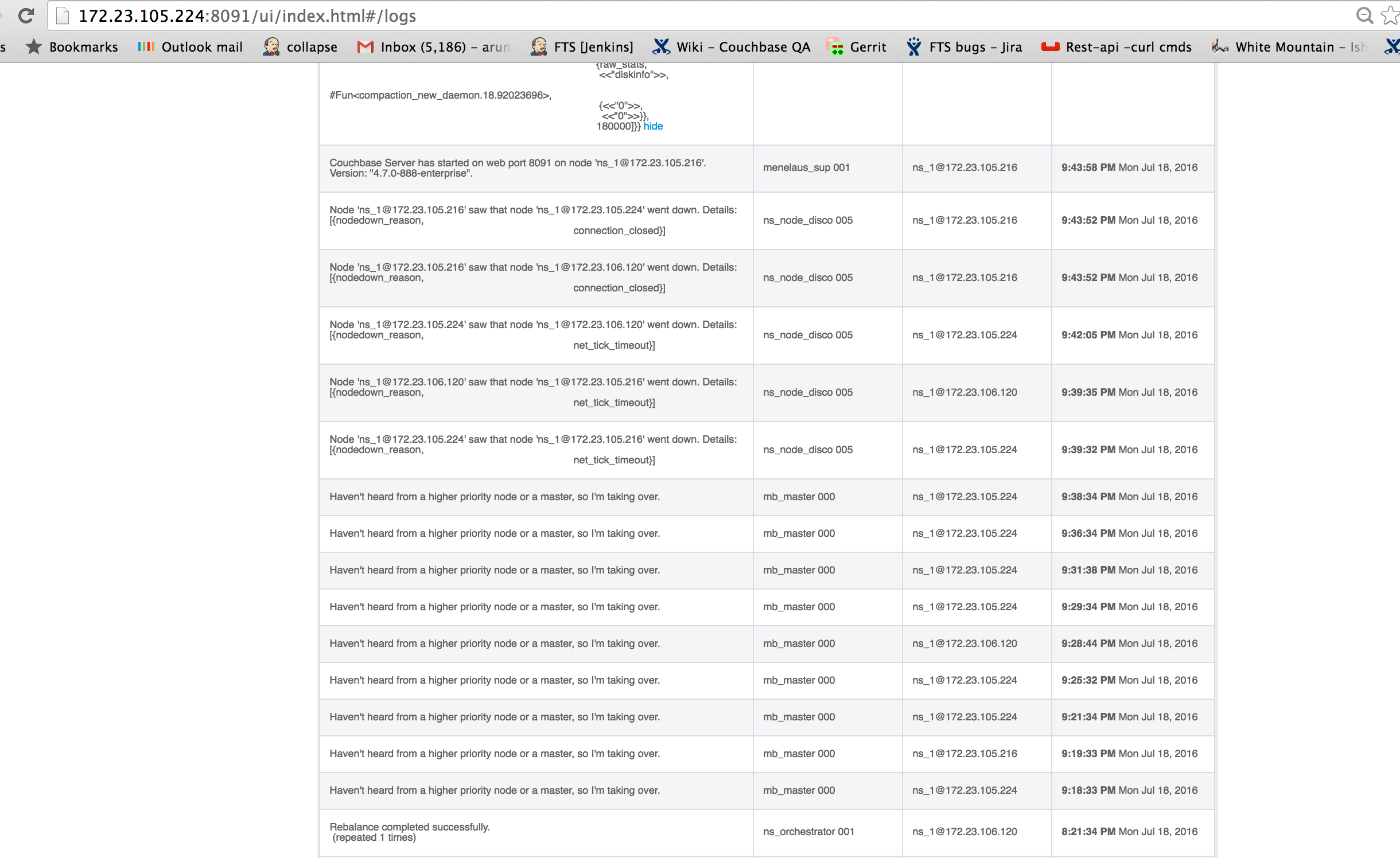
Everything goes wrong after 9:18:33PM when each of the nodes encounter tick_timeouts, and one by one, all nodes repeatedly take over as master until all of them go down and memc and compactor crash on .120. Couchbase restarts repeatedly on .120 and then goes into a kernel panic. I had to have IT bring up the node. Attaching cbcollect from all nodes.
.120 had kv + fts
.224 and .216 - only fts.
In descending order of events -
Control connection to memcached on 'ns_1@172.23.106.120' disconnected: {{badmatch,
|
{error,
|
timeout}},
|
[{mc_client_binary,
|
cmd_vocal_recv,
|
5,
|
[{file,
|
"src/mc_client_binary.erl"},
|
{line,
|
156}]},
|
{mc_client_binary,
|
... show ns_memcached 000 ns_1@172.23.106.120 9:45:10 PM Mon Jul 18, 2016
|
Compactor for database `default` (pid [{type,database},
|
{important,true},
|
{name,<<"default">>},
|
{fa,
|
{#Fun<compaction_new_daemon.4.92023696>,
|
[<<"default">>,
|
{config,
|
{30,18446744073709551616},
|
{30,18446744073709551616},
|
undefined,false,false,
|
{daemon_config,30,131072,20971520}},
|
false,
|
{[{type,bucket}]}]}}]) terminated unexpectedly: {timeout,
|
{gen_server,
|
call,
|
[{'ns_memcached-default',
|
'ns_1@172.23.106.120'},
|
{raw_stats,
|
<<"diskinfo">>,
|
#Fun<compaction_new_daemon.18.92023696>,
|
{<<"0">>,
|
<<"0">>}},
|
180000]}} hide compaction_new_daemon 000 ns_1@172.23.106.120 9:45:10 PM Mon Jul 18, 2016
|
Couchbase Server has started on web port 8091 on node 'ns_1@172.23.105.216'. Version: "4.7.0-888-enterprise". menelaus_sup 001 ns_1@172.23.105.216 9:43:58 PM Mon Jul 18, 2016
|
Node 'ns_1@172.23.105.216' saw that node 'ns_1@172.23.105.224' went down. Details: [{nodedown_reason,
|
connection_closed}] ns_node_disco 005 ns_1@172.23.105.216 9:43:52 PM Mon Jul 18, 2016
|
Node 'ns_1@172.23.105.216' saw that node 'ns_1@172.23.106.120' went down. Details: [{nodedown_reason,
|
connection_closed}] ns_node_disco 005 ns_1@172.23.105.216 9:43:52 PM Mon Jul 18, 2016
|
Node 'ns_1@172.23.105.224' saw that node 'ns_1@172.23.106.120' went down. Details: [{nodedown_reason,
|
net_tick_timeout}] ns_node_disco 005 ns_1@172.23.105.224 9:42:05 PM Mon Jul 18, 2016
|
Node 'ns_1@172.23.106.120' saw that node 'ns_1@172.23.105.216' went down. Details: [{nodedown_reason,
|
net_tick_timeout}] ns_node_disco 005 ns_1@172.23.106.120 9:39:35 PM Mon Jul 18, 2016
|
Node 'ns_1@172.23.105.224' saw that node 'ns_1@172.23.105.216' went down. Details: [{nodedown_reason,
|
net_tick_timeout}] ns_node_disco 005 ns_1@172.23.105.224 9:39:32 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:38:34 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:36:34 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:31:38 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:29:34 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.106.120 9:28:44 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:25:32 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:21:34 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.216 9:19:33 PM Mon Jul 18, 2016
|
Haven't heard from a higher priority node or a master, so I'm taking over. mb_master 000 ns_1@172.23.105.224 9:18:33 PM Mon Jul 18, 2016
|
|