Description
Two clusters each with 2 nodes with unidirectional XDCR.
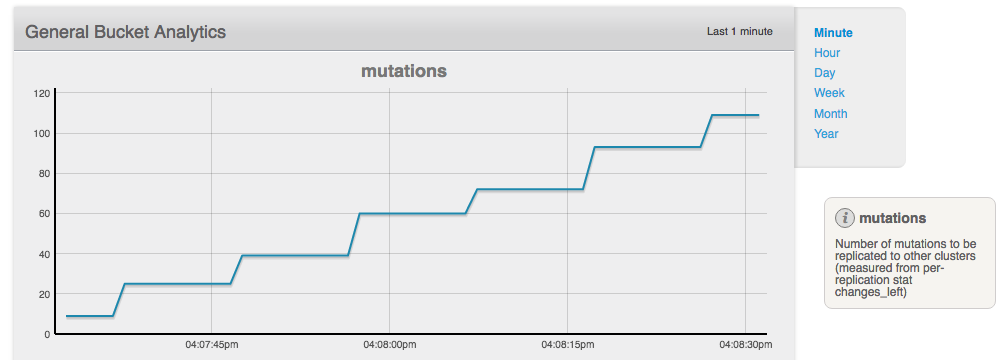
When the target cluster is being rebalanced the mutations do not get sent:
chanages_left_during_rebalance.png![]()
Three to four minutes after the rebalance finishes there is massive spike in XDCR operations where it seems to start working again:
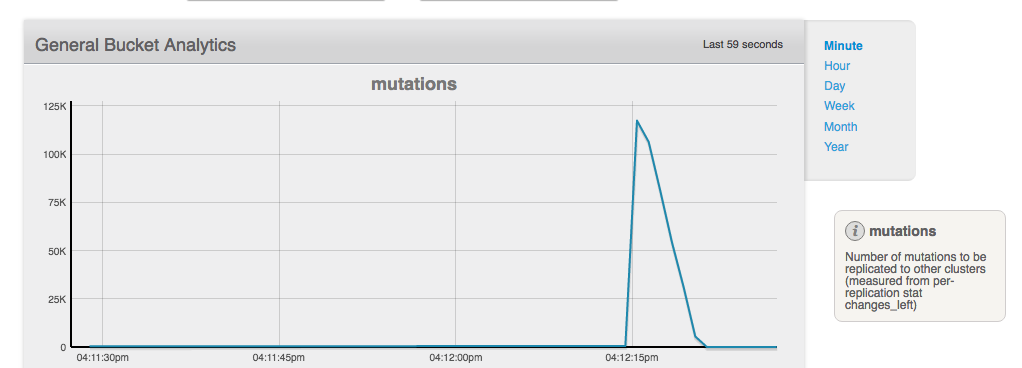
The bucket has roughly 200K items and during the rebalance a small number of operations is being sent to the cluster:
| cbc-pillowfight -U couchbase://10.111.151.101/default -I 2000 -m 1024 -m 1024 -p xdcr --rate-limit 10 |