Details
-
Improvement
-
Resolution: Fixed
-
 Critical
Critical
-
5.0.0
Description
- Create a cluster with few nodes and buckets in it.
- Start a rebalance on the cluster after either adding a server or removing a server from the cluster
- While the rebalance is in progress, inject failure into one of the node (Failure like network failure i.e. stopping network on a node, enabling firewall on the node, stopping memcached on the node).
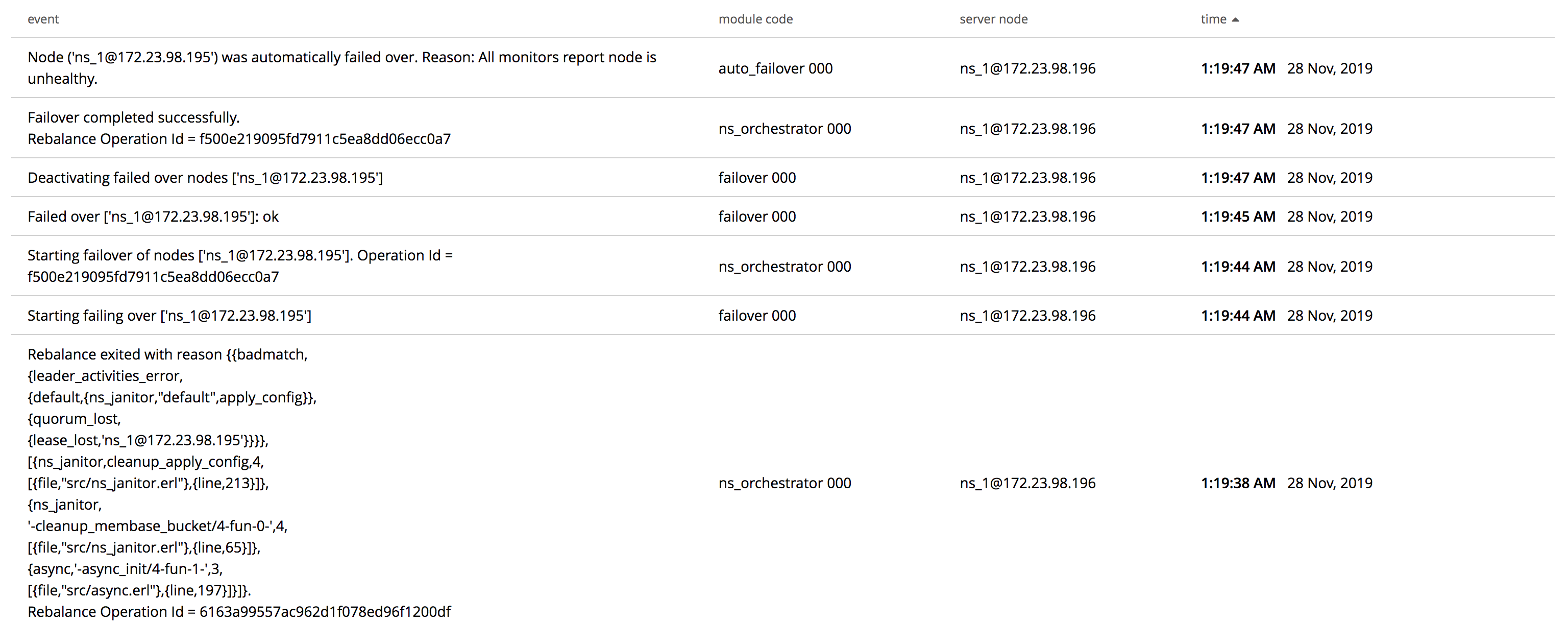
We detect the failure on the node immediately. But the rebalance of node does not stop even when there are failures on node(s) and is shown to be struck at whatever percentage it had completed before the node failure. Since we detect a node failure fast, we should stop the rebalance immediately or after a certain amount of time. Since we do not stop the rebalance immediately, the autofailover of a failed node is delayed till rebalance has exited or has been stopped. This causes more down time than users would want.
Note that we stop rebalance immediately in node failures like stopping the couchbase server, killing nsserver etc but when the failures are related to network, the rebalance is failed only after long wait period.
Attachments
Issue Links
| For Gerrit Dashboard: MB-24242 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 79530,4 | MB-24242: Stop rebalance when auto-failover... | master | ns_server | Status: MERGED | +2 | +1 |
| 80877,1 | MB-24242: Stop rebalance when auto-failover... | master | analytics_ns_server | Status: ABANDONED | 0 | 0 |
| 80966,2 | Revert "MB-24242: Stop rebalance when auto-failover..." | master | ns_server | Status: MERGED | +2 | +1 |
| 95597,6 | MB-24242: Don't consider the node down from ... | master | ns_server | Status: MERGED | +2 | +1 |
| 95598,6 | MB-24242: auto-failover should stop ... | master | ns_server | Status: MERGED | +2 | +1 |
| 95599,6 | MB-24242: User setting to permit ... | master | ns_server | Status: MERGED | +2 | +1 |
| 96700,2 | MB-24242: Feature for auto-failover aborting ... | master | ns_server | Status: MERGED | +2 | +1 |
| 99045,10 | MB-24242, MB-31366: Set relevant vBuckets to ... | master | ns_server | Status: MERGED | +2 | +1 |