Details
-
Bug
-
Resolution: Done
-
 Critical
Critical
-
master
-
Untriaged
-
Yes
Description
As reported by http://showfast.sc.couchbase.com/daily/#/history/KV%7CPillowfight,%2020/80%20R/W,%20256B%20binary%20items%7CMax%20Throughput%20(ops/sec) :
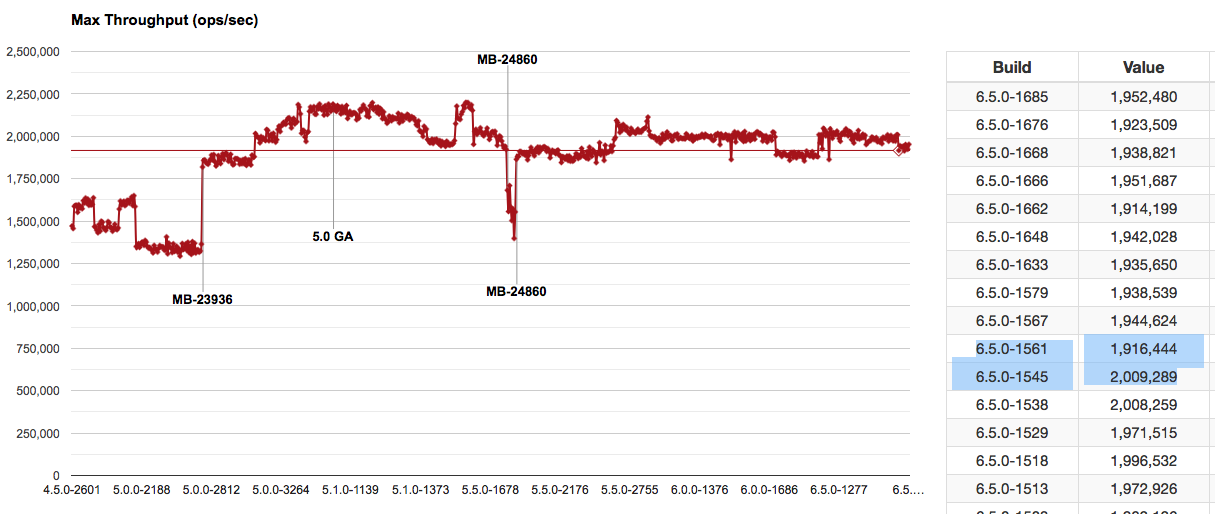
Appears to have occurred between builds 6.5.0-1545 and 6.5.0-1561
| Build | Throughput |
|---|---|
| 6.5.0-1561 | 1,916,444 |
| 6.5.0-1545 | 2,009,289 |
Attachments
Issue Links
- relates to
-
-
- Closed
-