Details
-
Task
-
Resolution: Fixed
-
 Major
Major
-
6.0.0
Description
Build 6.0.0-1693
As discussed in high bucket density sync-up meeting, logging this issue for investigation.
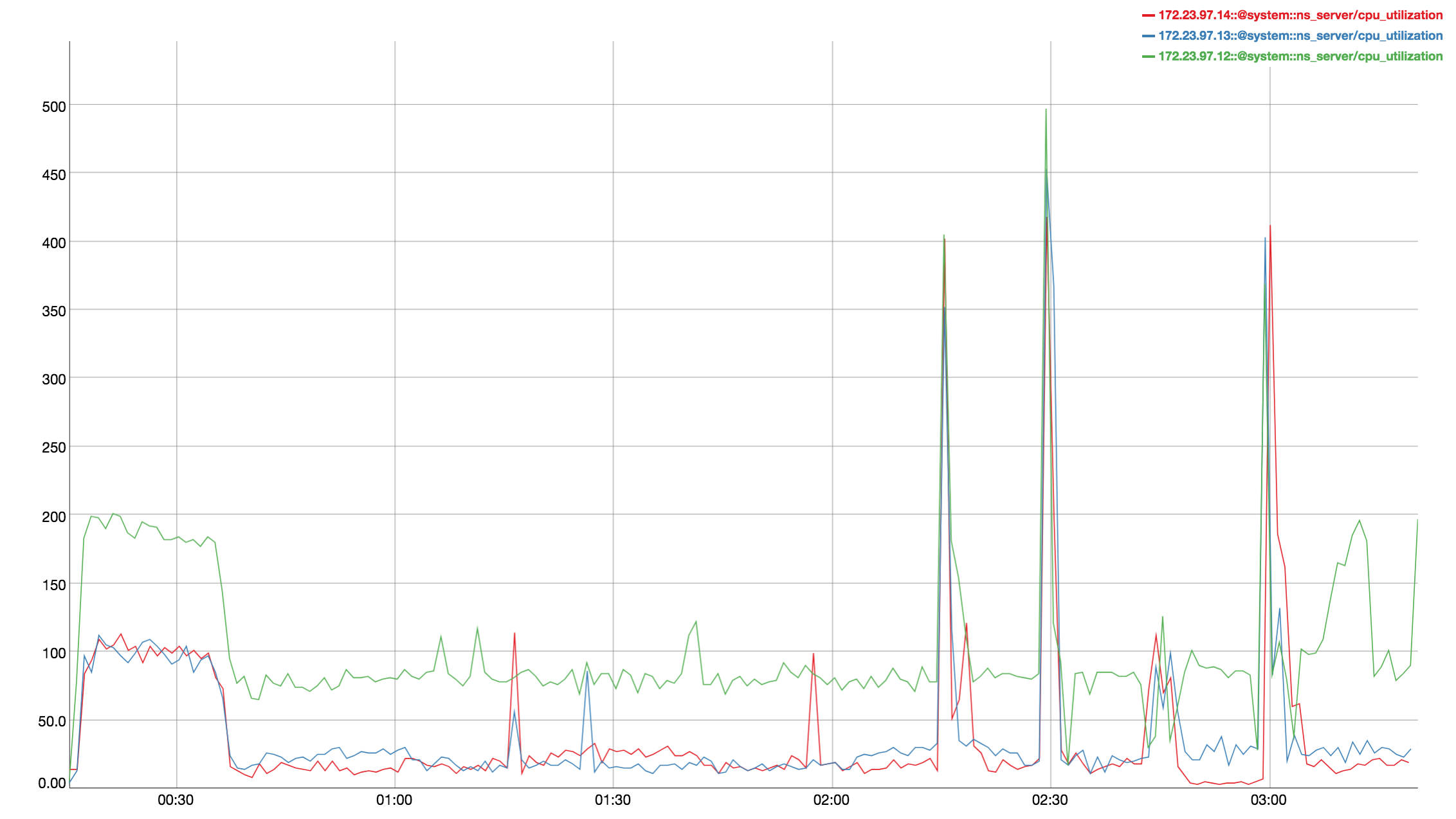
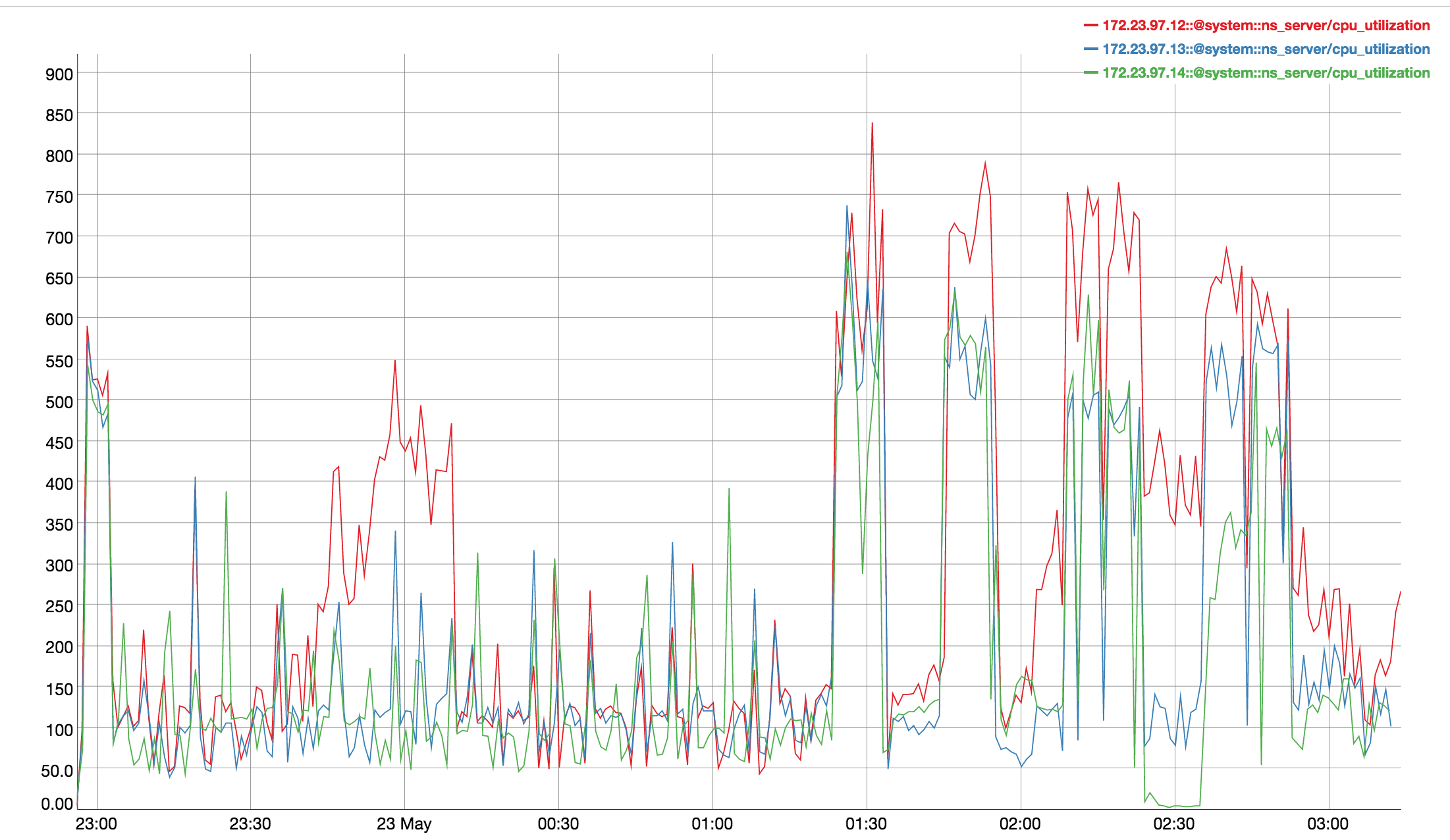
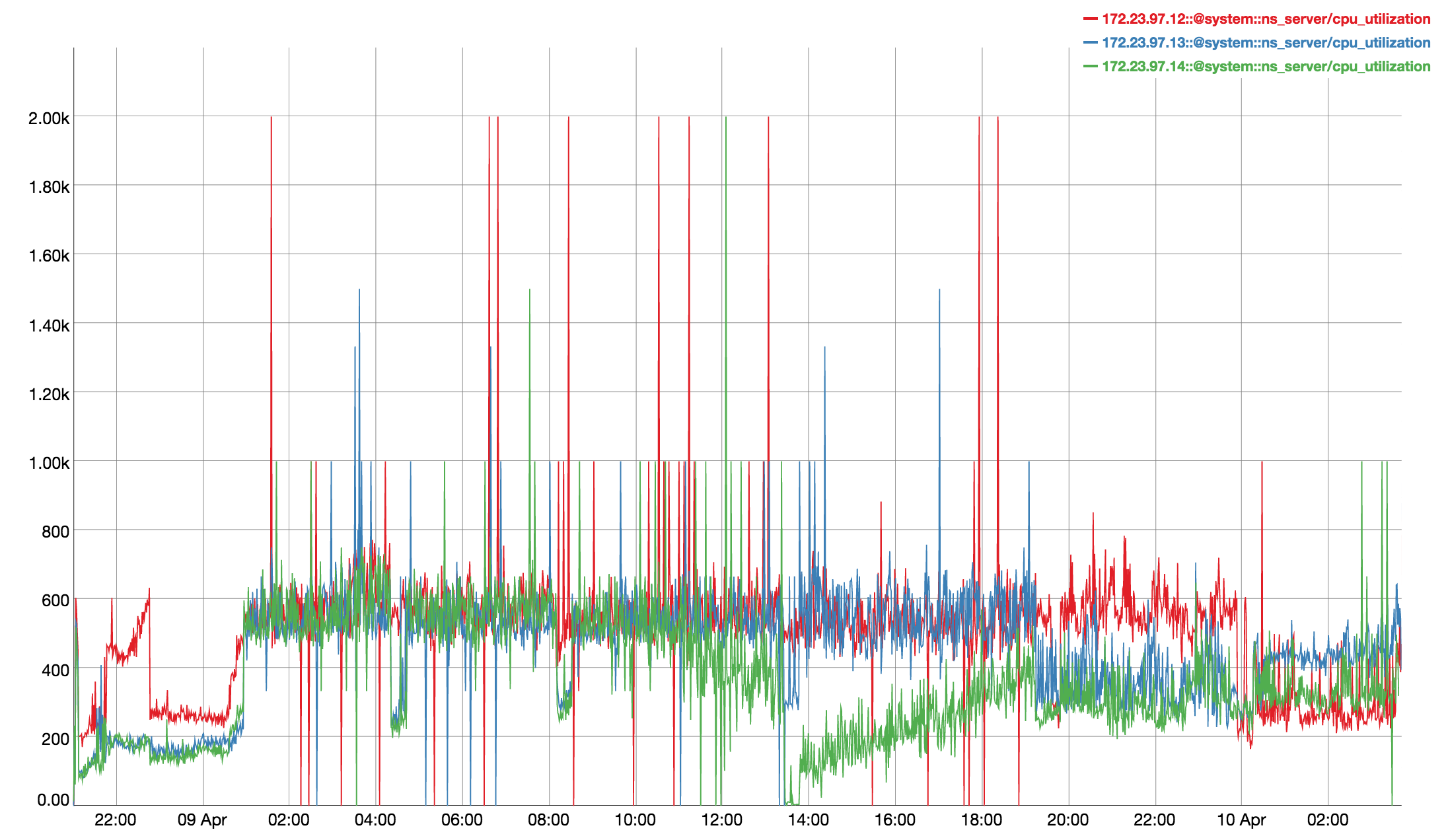
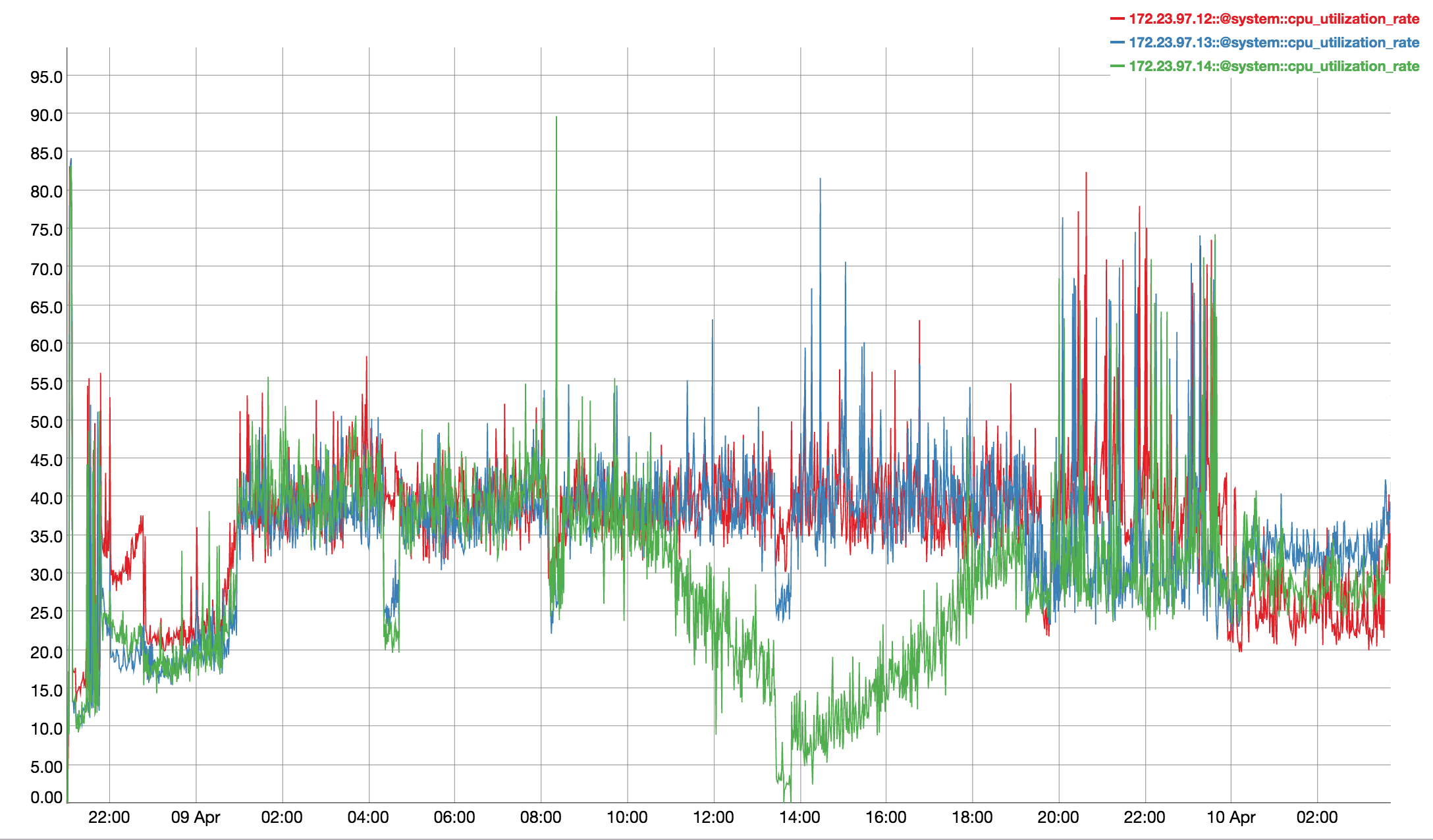
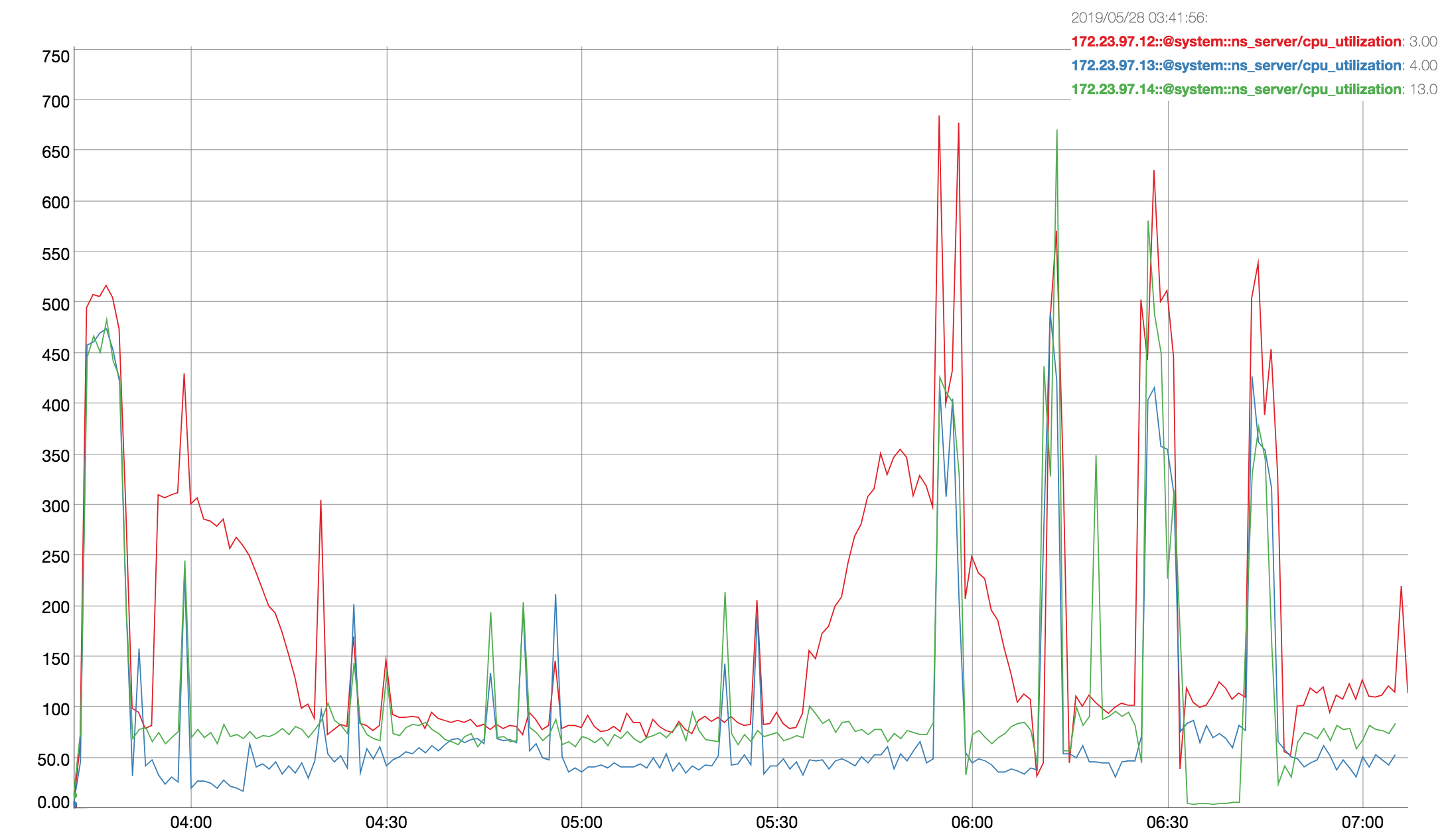
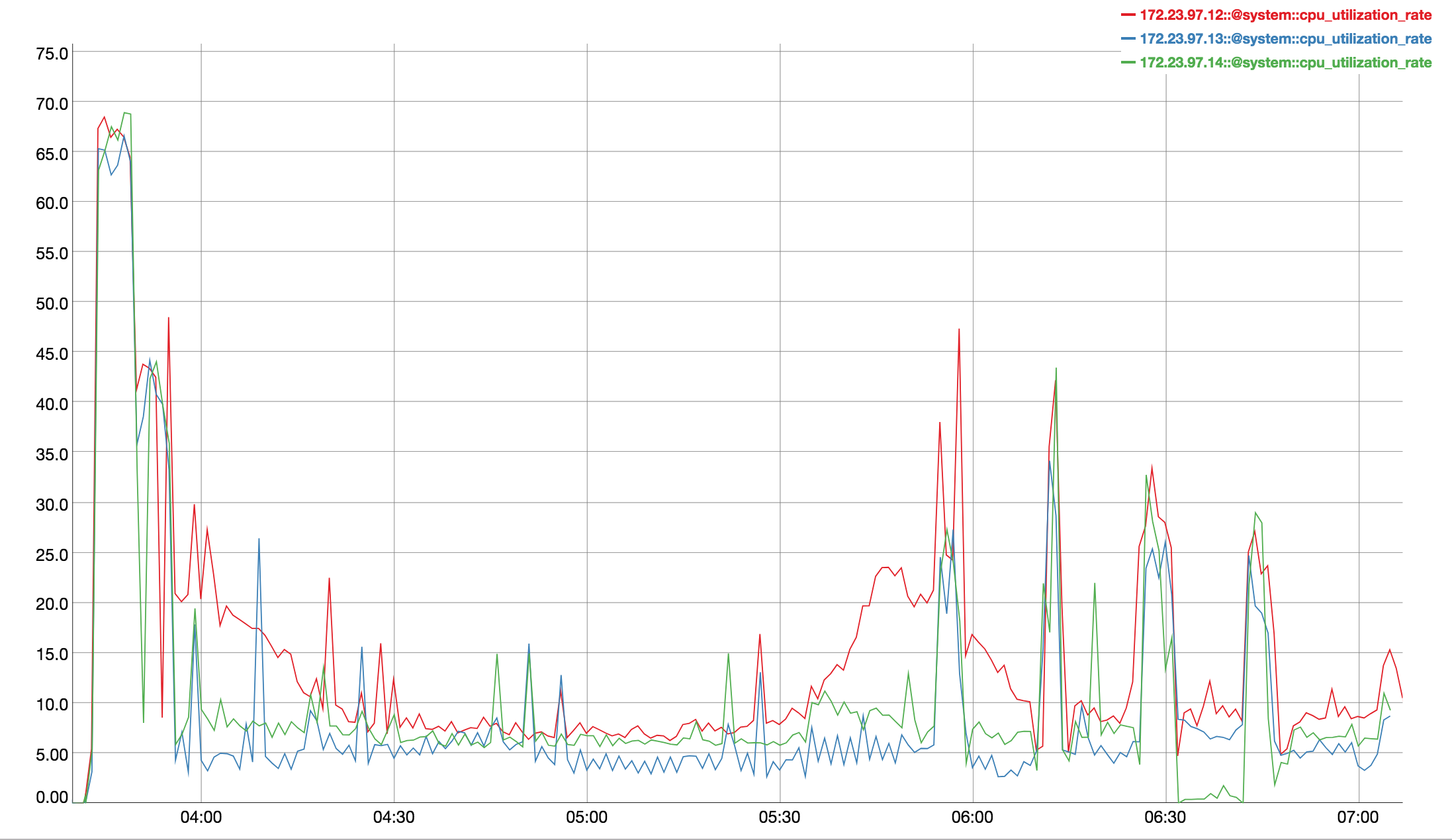
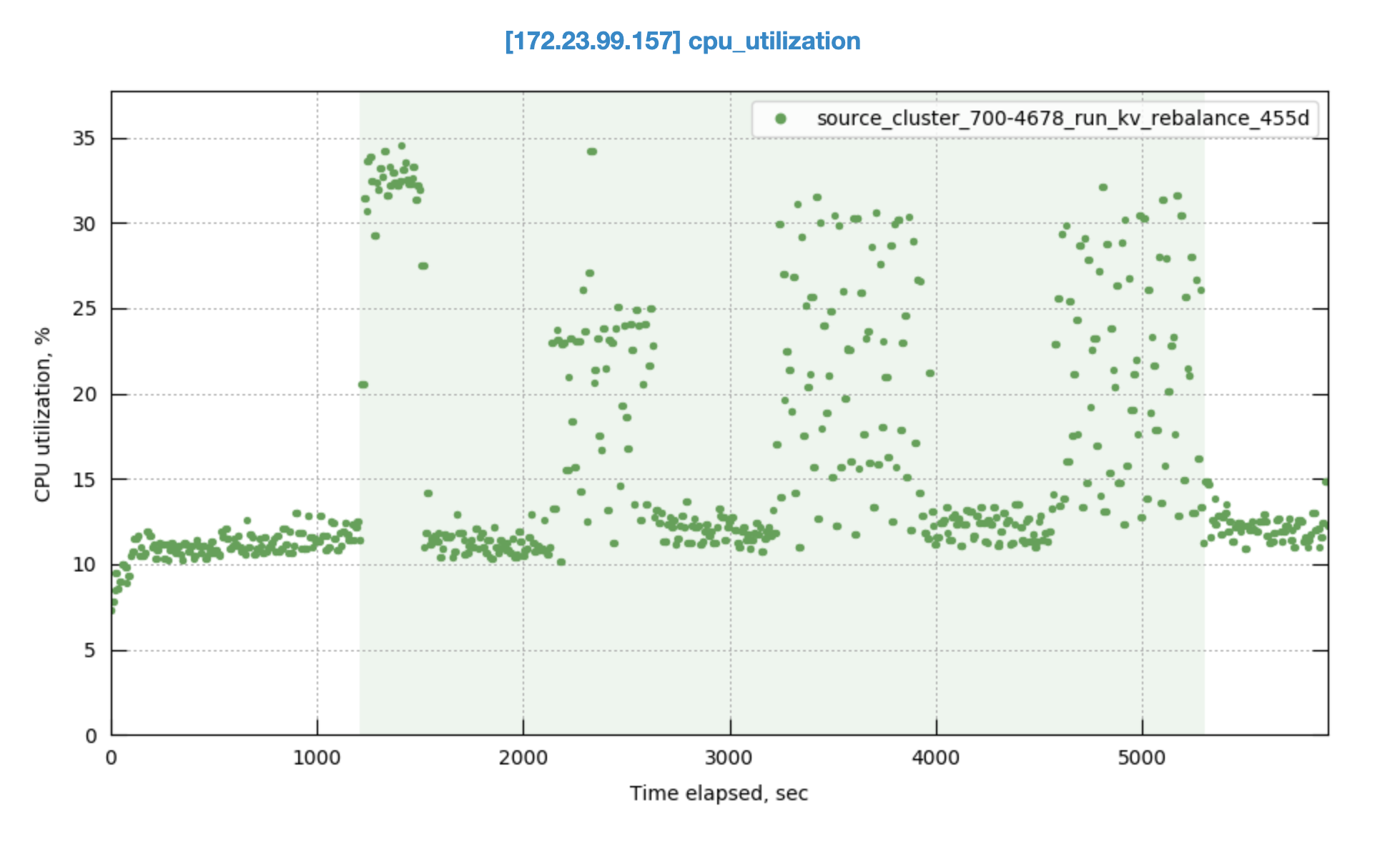
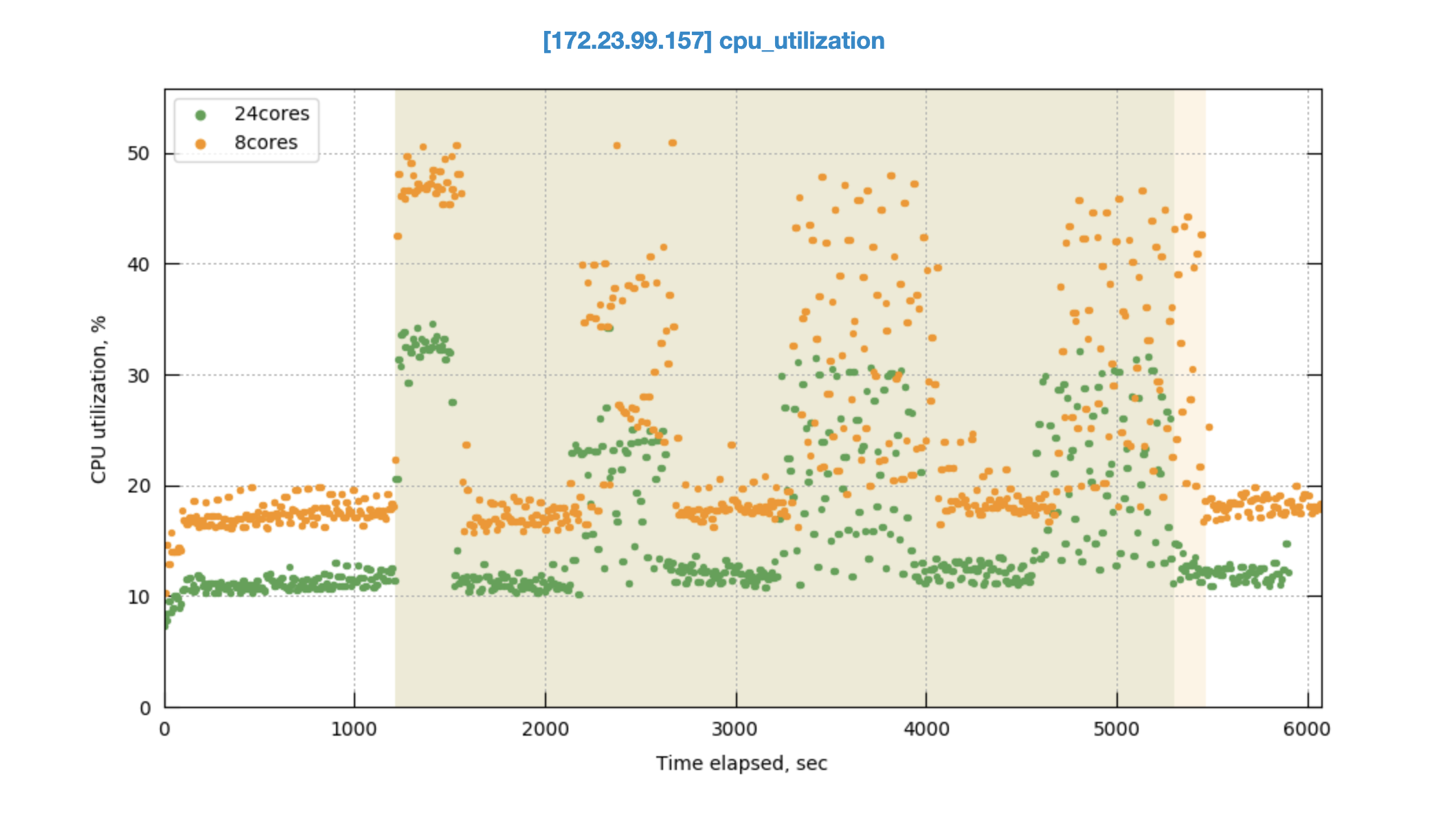
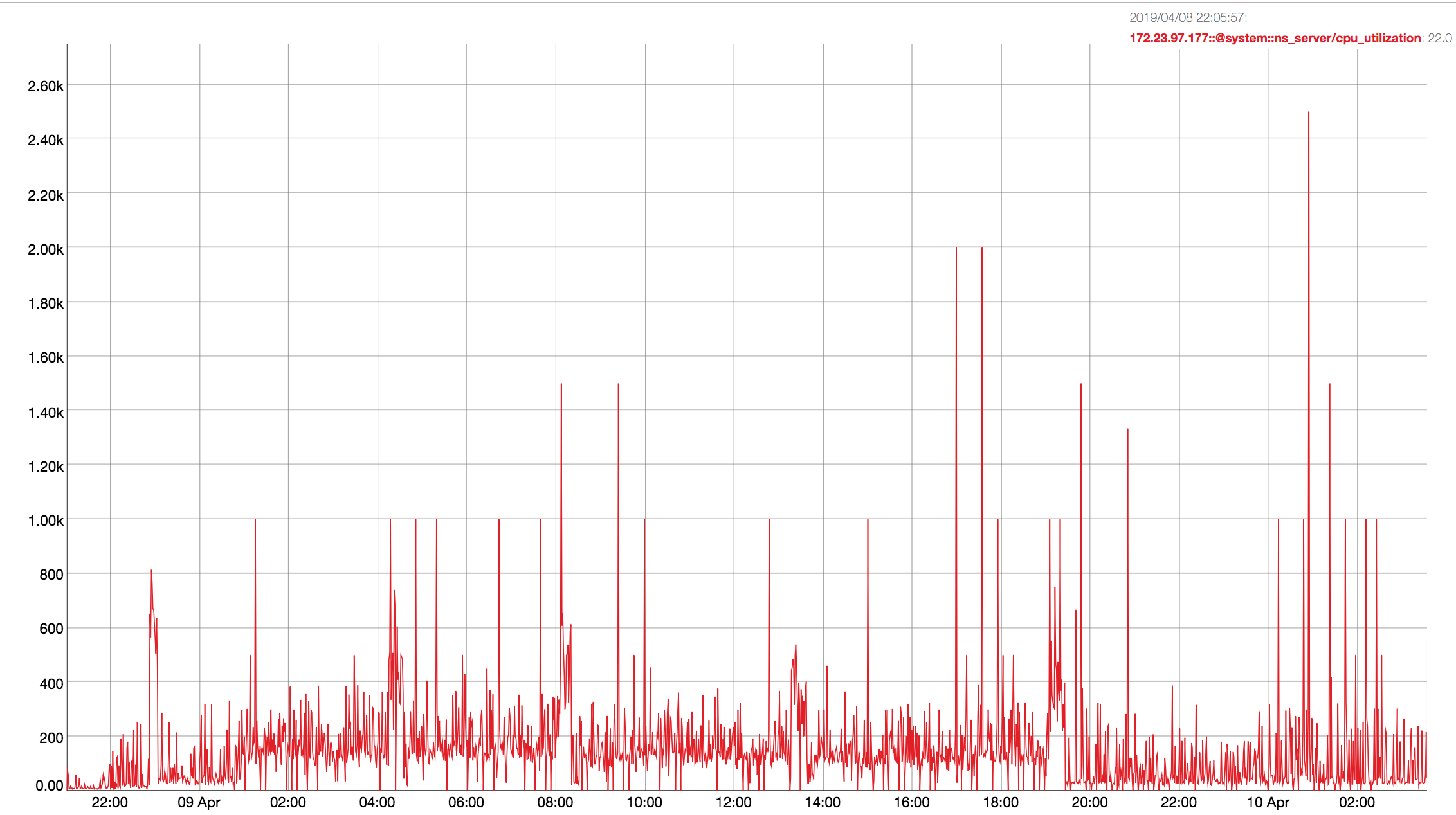
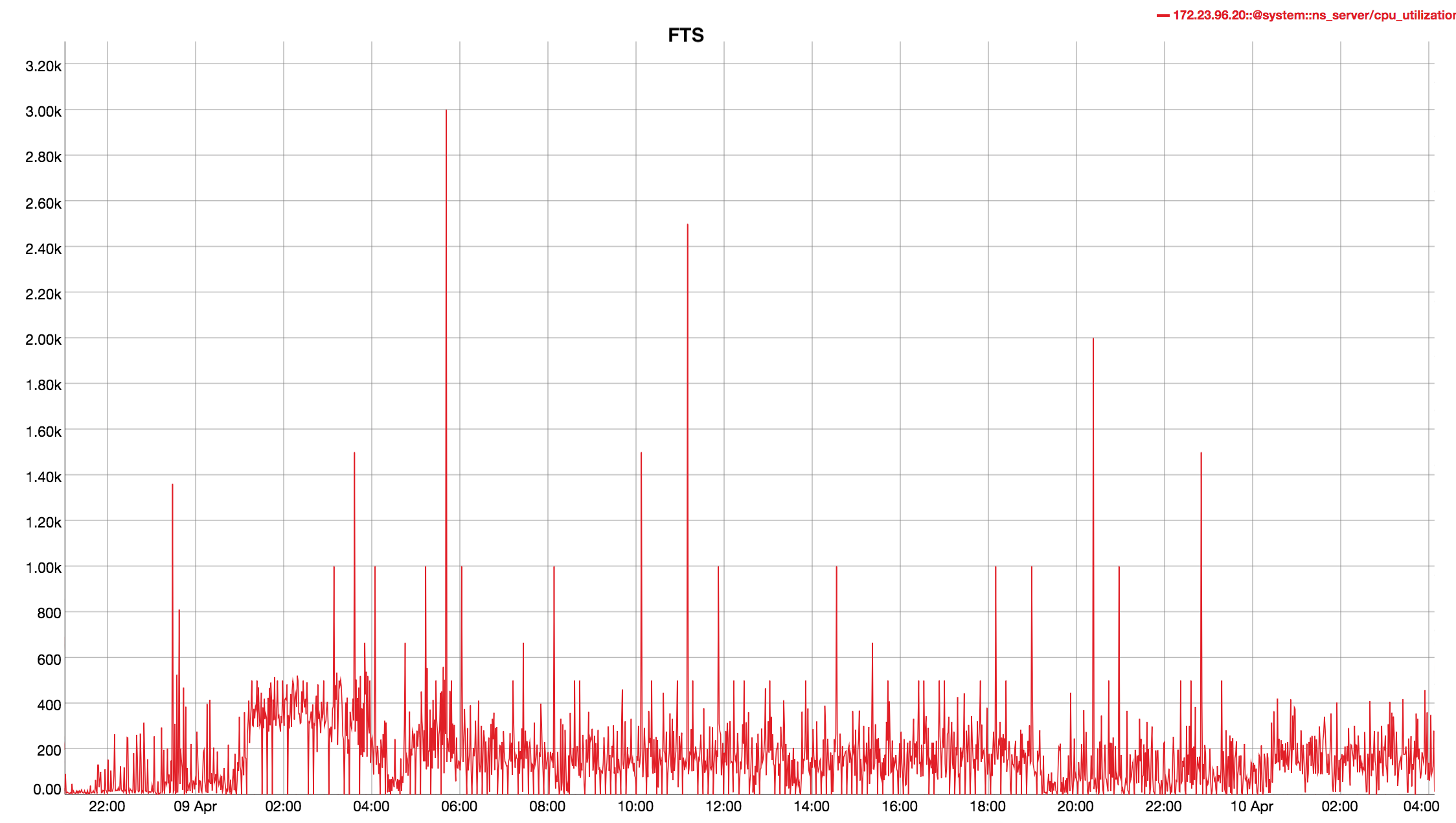
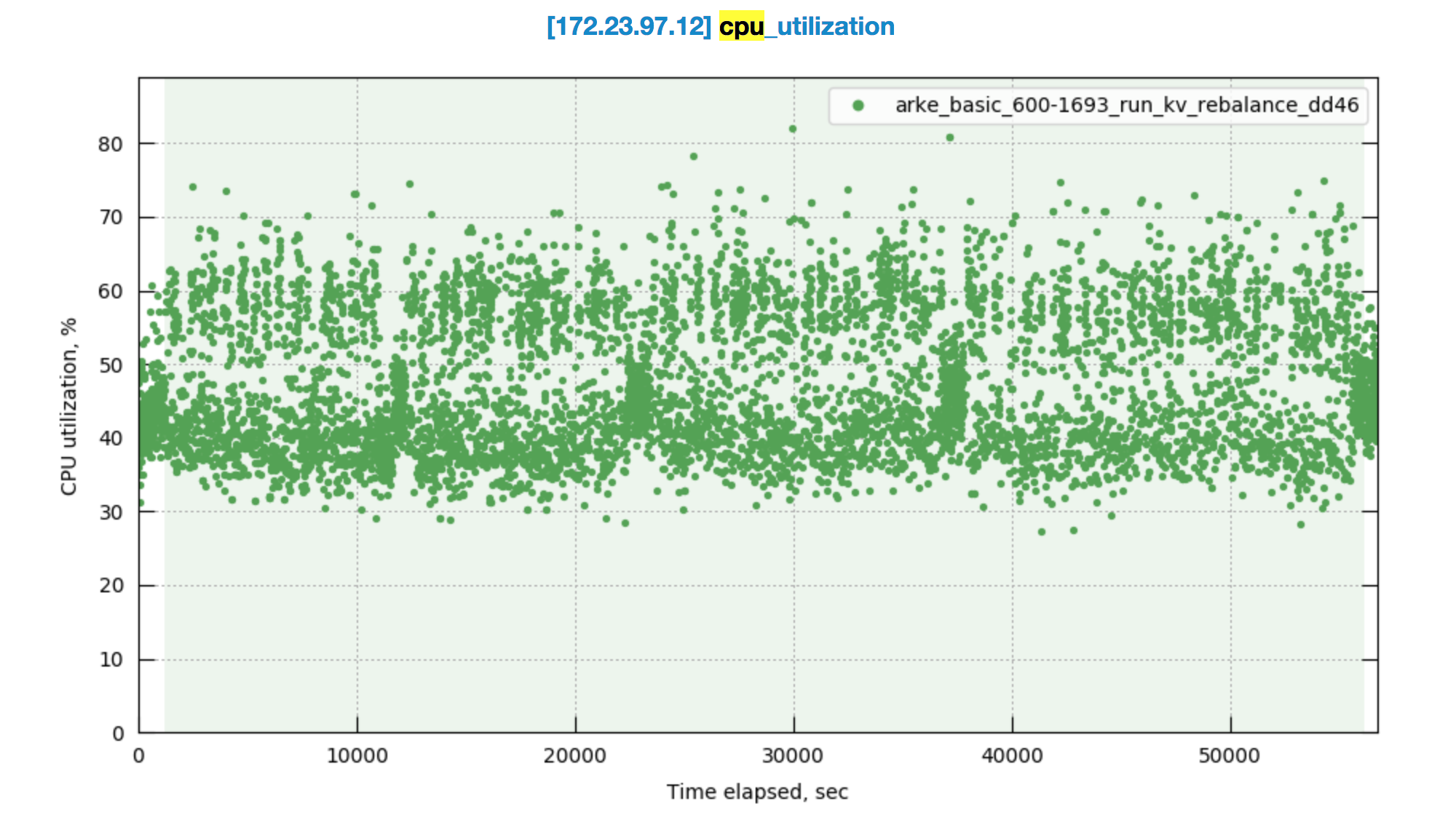
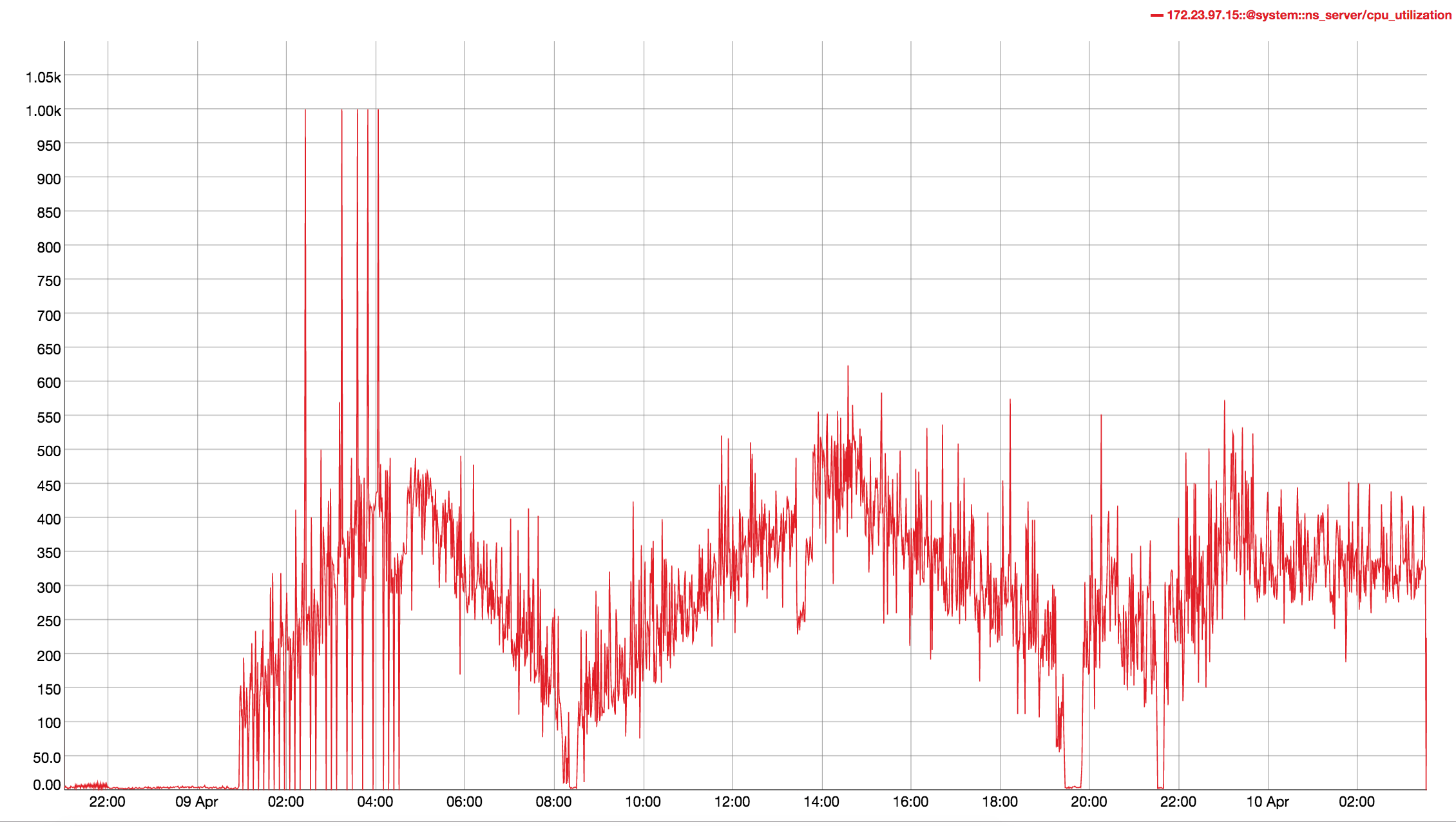
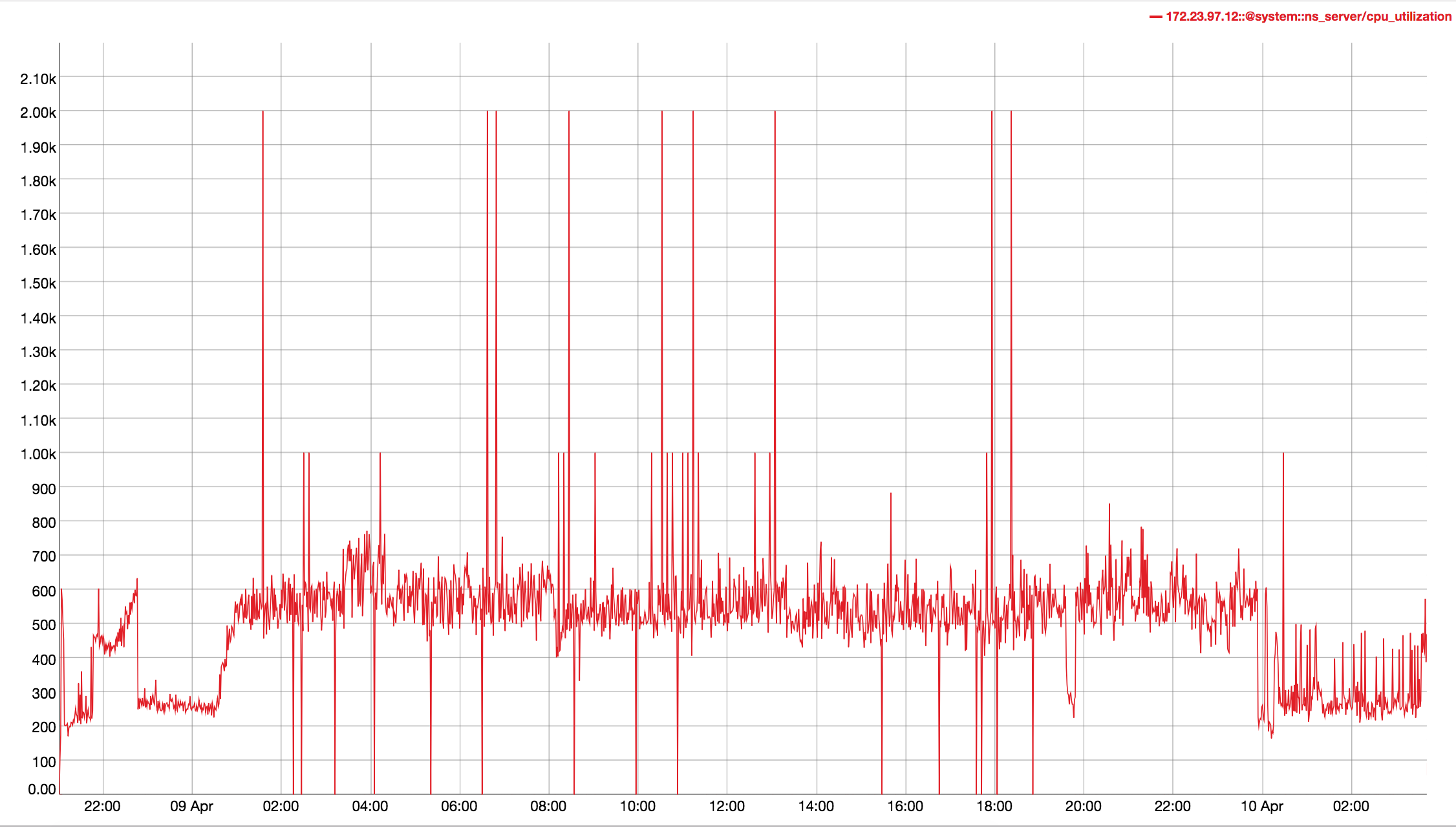
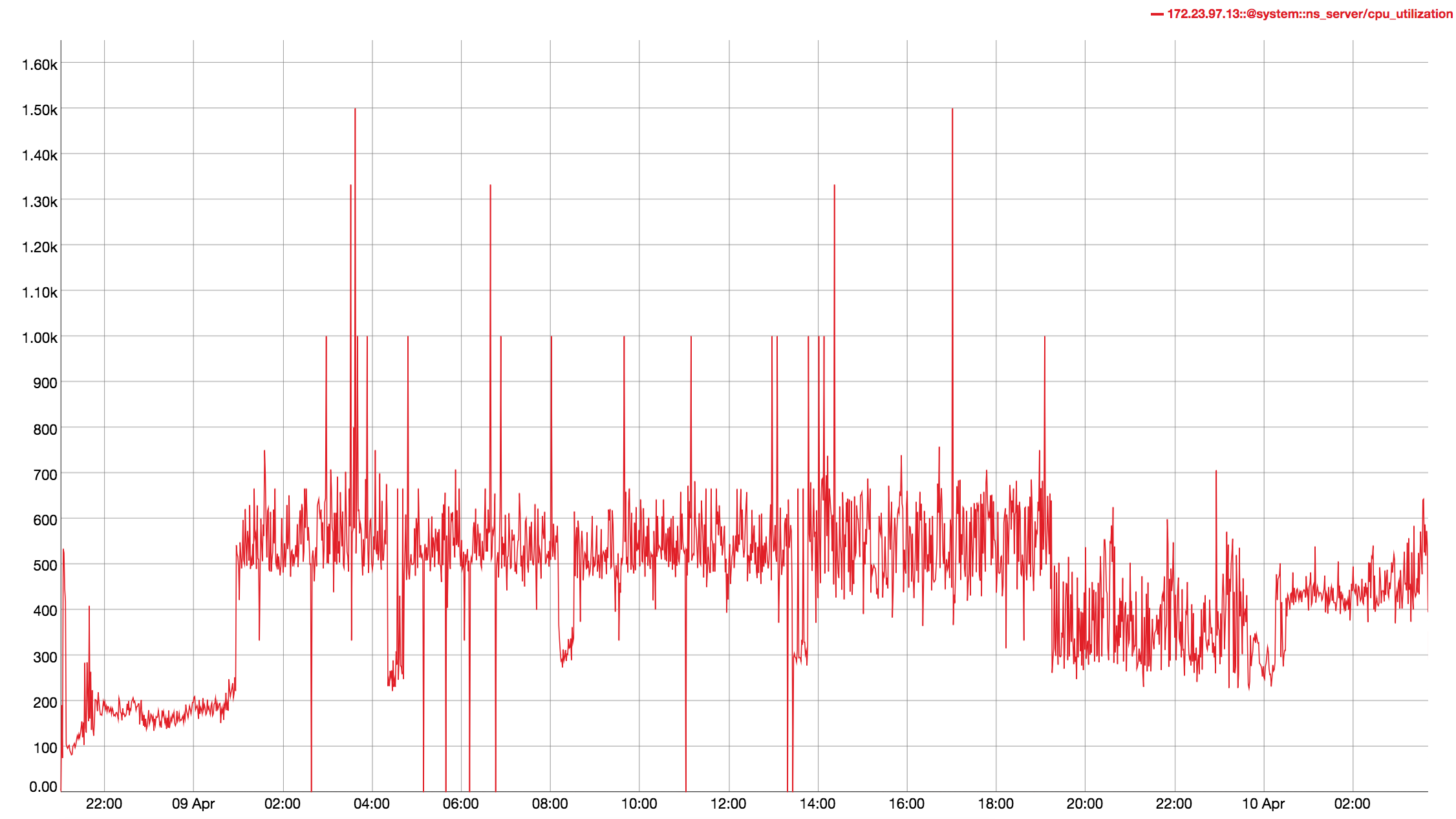
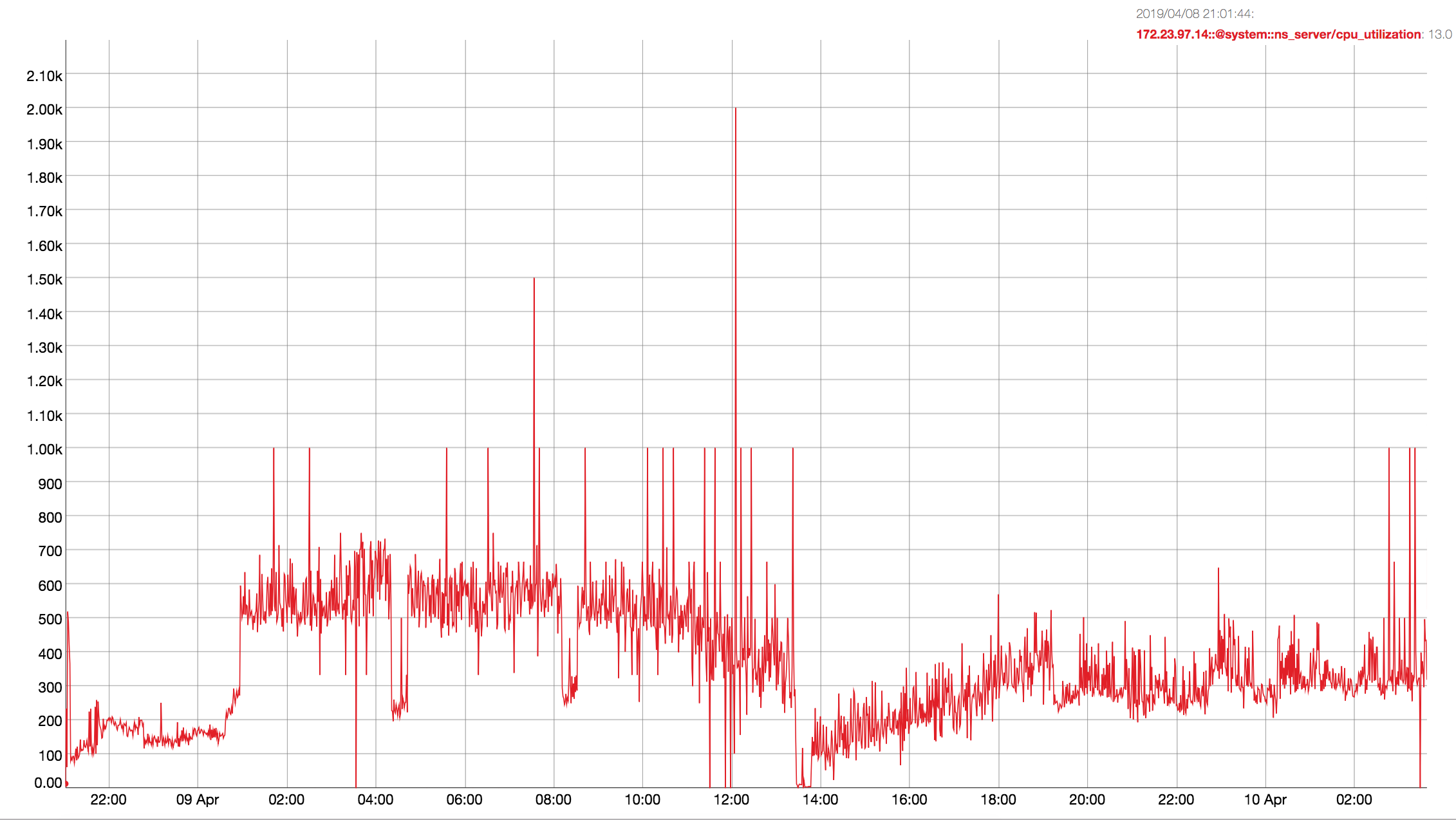
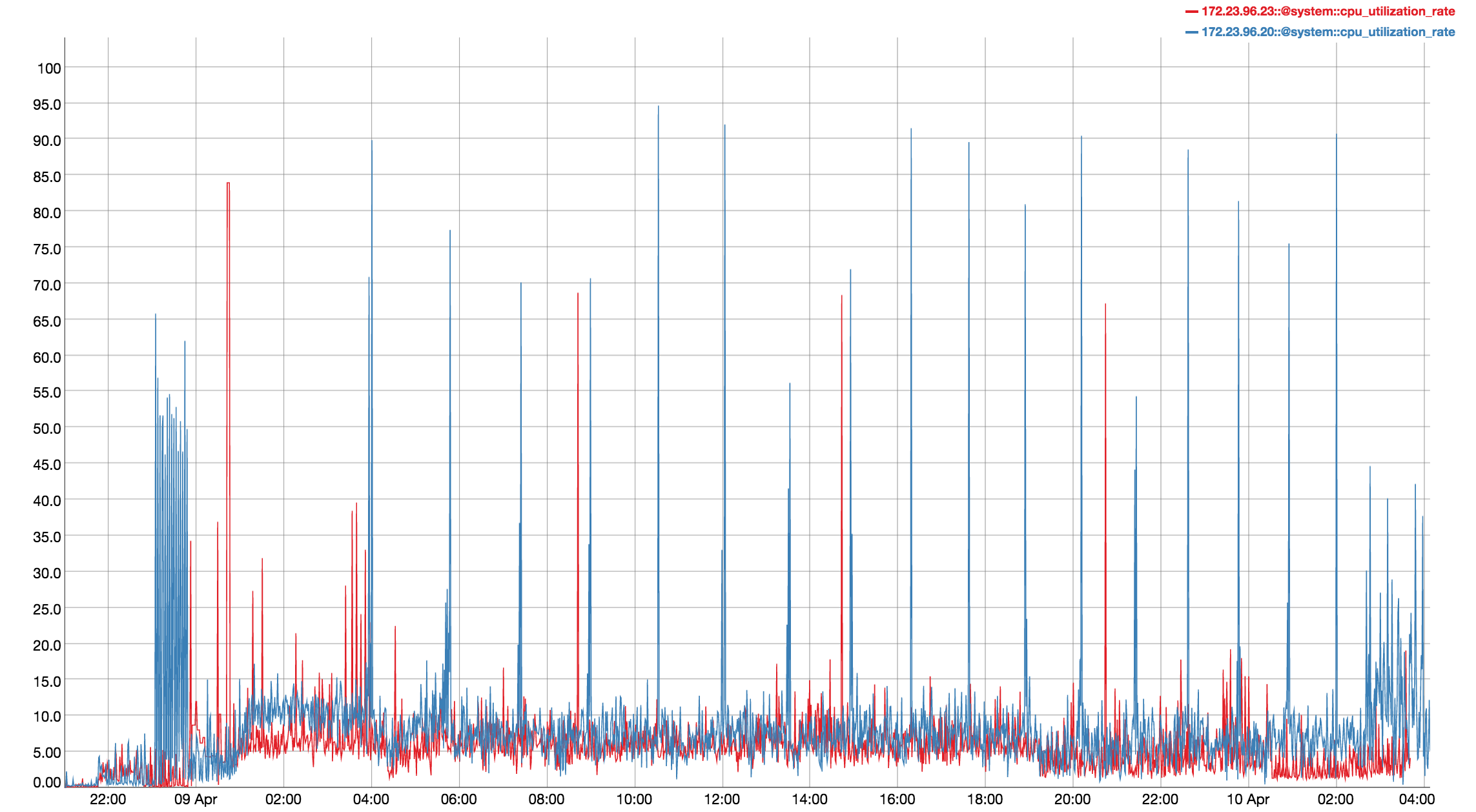
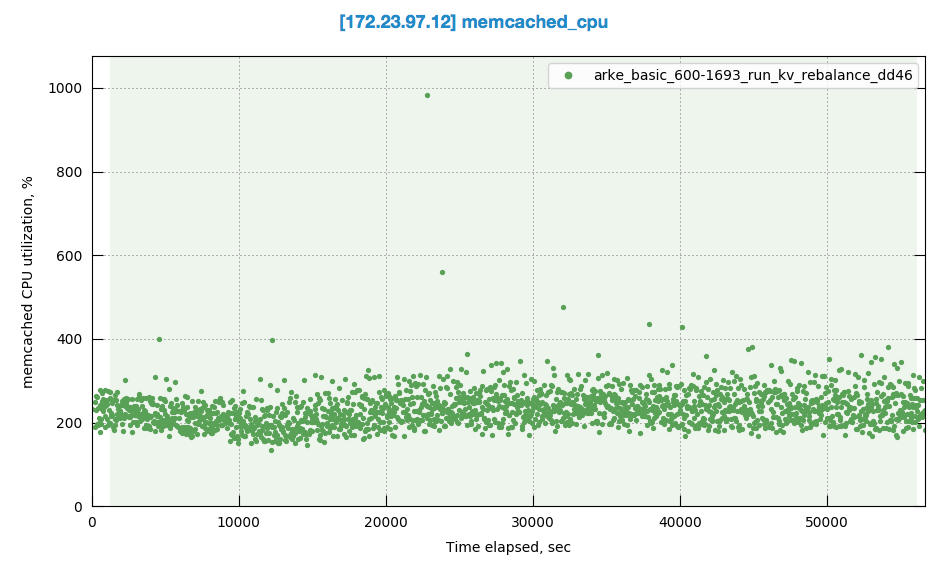
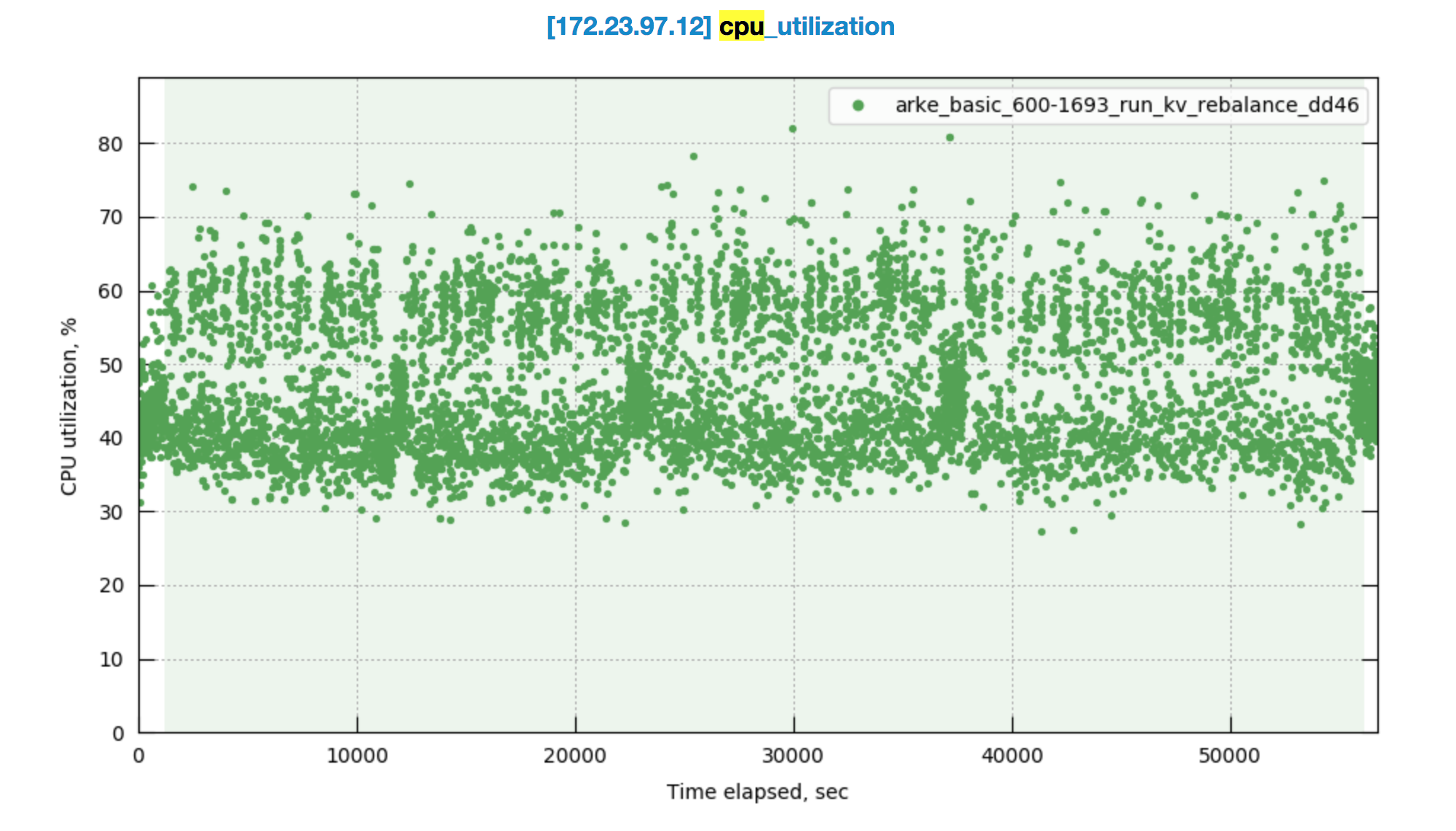
Observed CPU utilisation spikes upto 80% on 24 core orchestrator machine during KV rebalance going on with 30 buckets present in cluster.
CPU utilisation graph during rebalance-
cbmonitor link- http://cbmonitor.sc.couchbase.com/reports/html/?snapshot=arke_basic_600-1693_run_kv_rebalance_dd46
Logs:
KV node- https://s3.amazonaws.com/bugdb/jira/index_reb_multibucket/collectinfo-2019-01-08T151840-ns_1%40172.23.97.12.zip
KV node- https://s3.amazonaws.com/bugdb/jira/index_reb_multibucket/collectinfo-2019-01-08T151840-ns_1%40172.23.97.13.zip
KV node- https://s3.amazonaws.com/bugdb/jira/index_reb_multibucket/collectinfo-2019-01-08T151840-ns_1%40172.23.97.14.zip