Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
6.5.0
-
Untriaged
-
Yes
Description
Build: 6.5.0-4926 , not seen on 6.5.0-4908
Test: MH longevity
Day: 2nd
Cycle: 2nd
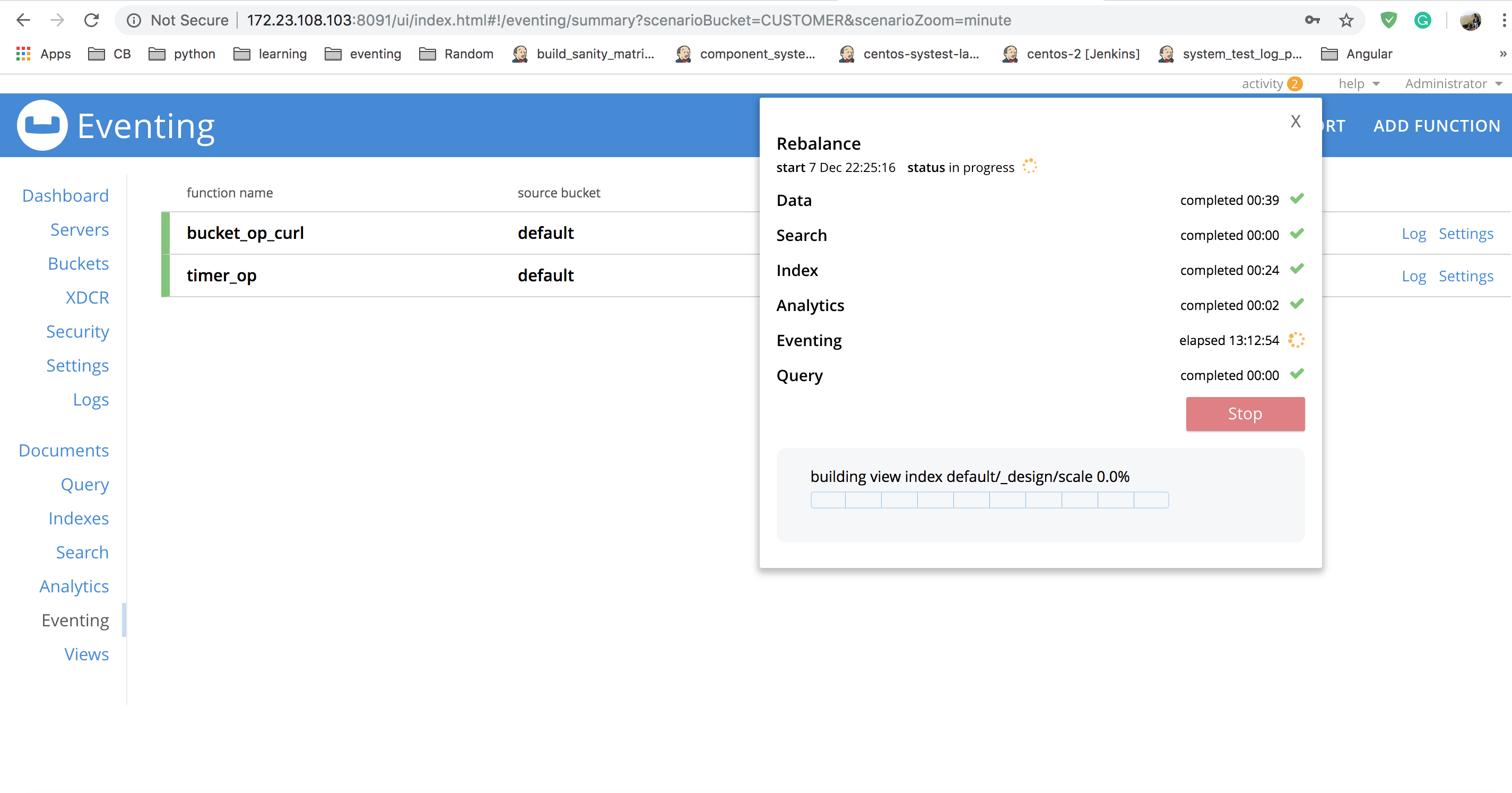
Rebalance out eventing node
[2019-12-07T08:55:15-08:00, sequoiatools/couchbase-cli:6.5:699790] rebalance -c 172.23.108.103:8091 --server-remove 172.23.96.148 -u Administrator -p password
|
Attachments
| For Gerrit Dashboard: MB-37199 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 119059,3 | MB-37199 : Stop generating oScanTimer internal events in c++ on an out going eventing node and during pause. Separate out Add/Remove Timer Partitions | unstable | eventing | Status: MERGED | +2 | +1 |
| 119123,3 | MB-37199 : Stop generating oScanTimer internal events in c++ on an out going eventing node and during pause. Separate out Add/Remove Timer Partitions | mad-hatter | eventing | Status: MERGED | +2 | +1 |