Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
6.5.0
-
ubuntu1604
-
Untriaged
-
-
Yes
-
KV Sprint 2019-12
Description
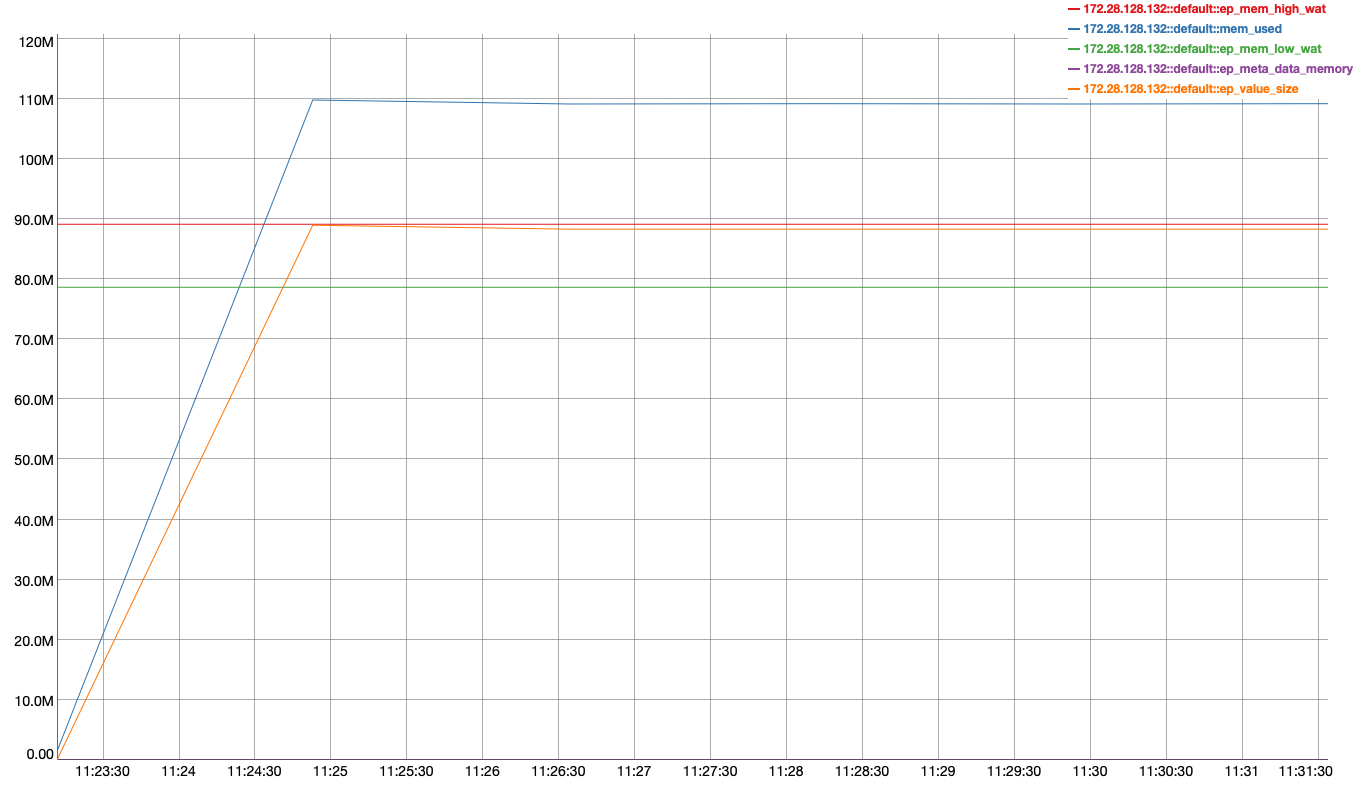
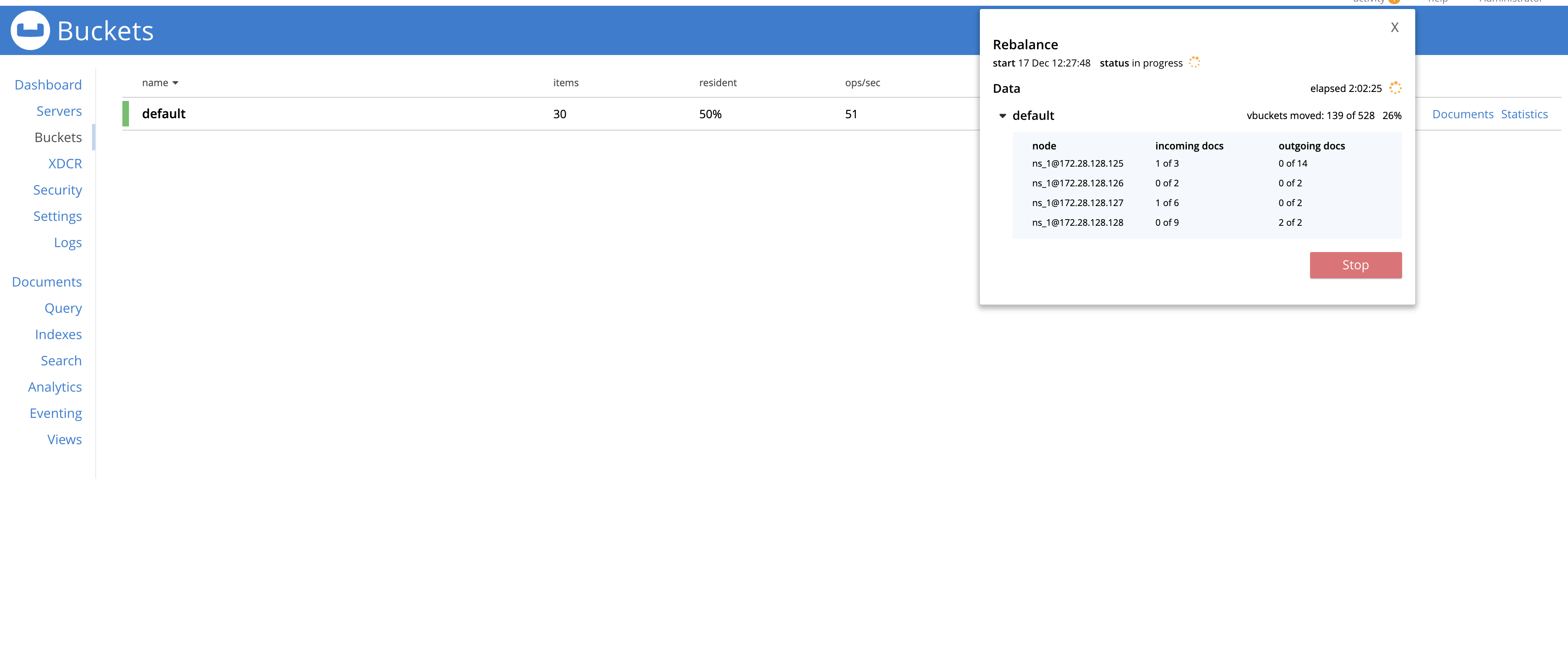
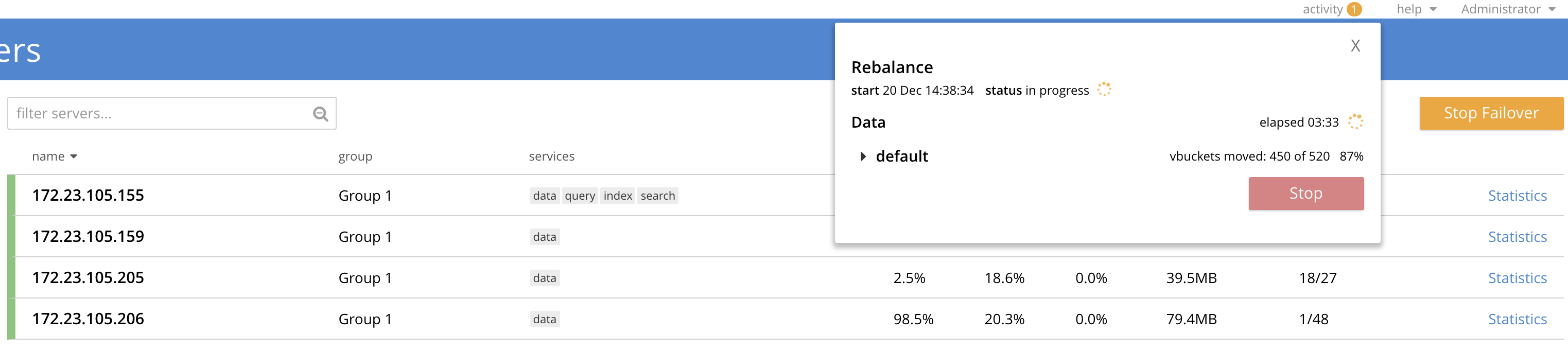
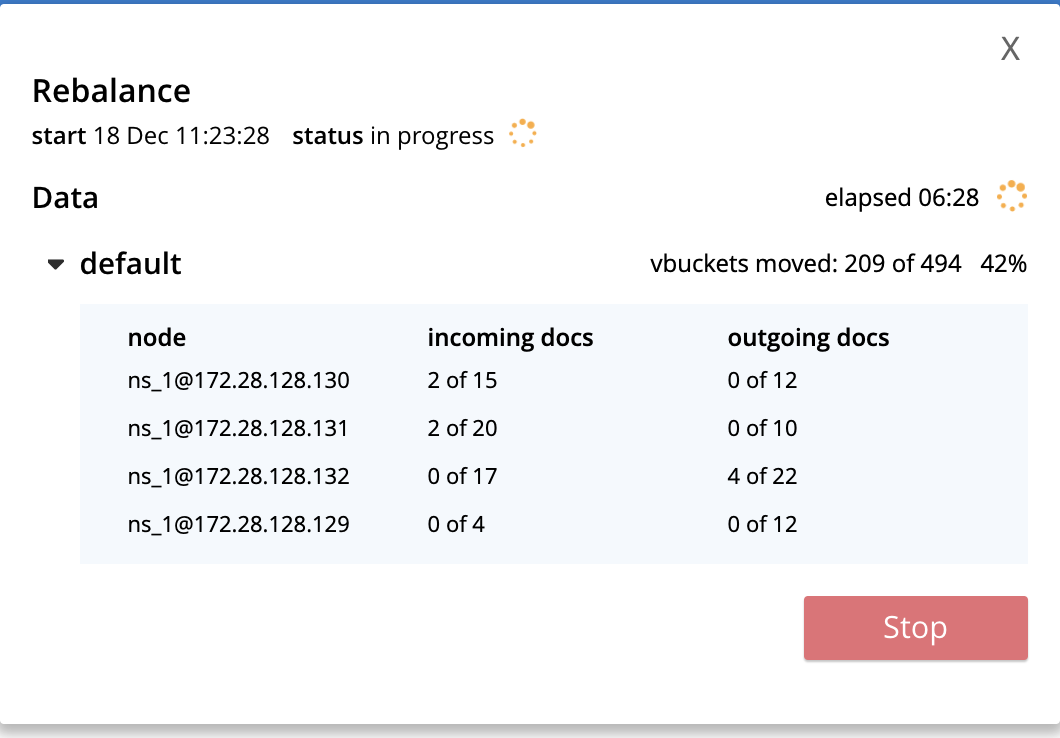
While running the following Jepsen test that performs a graceful failover of a node and then re-adds it into the cluster using delta node recovery. We observed a rebalance hang during the failover stage of the test.
lein trampoline run test --nodes-file ./nodes --username vagrant --ssh-private-key ./resources/vagrantkey --package /home/couchbase/jenkins/workspace/kv-engine-jepsen-post-commit/install --workload=failover --failover-type=graceful --recovery-type=delta --replicas=2 --no-autofailover --disrupt-count=1 --rate=0 --durability=0:100:0:0 --eviction-policy=value --cas --use-json-docs --doc-padding-size=3072 --hashdump --enable-memcached-debug-log-level --enable-tcp-capture
Points to note about the test:
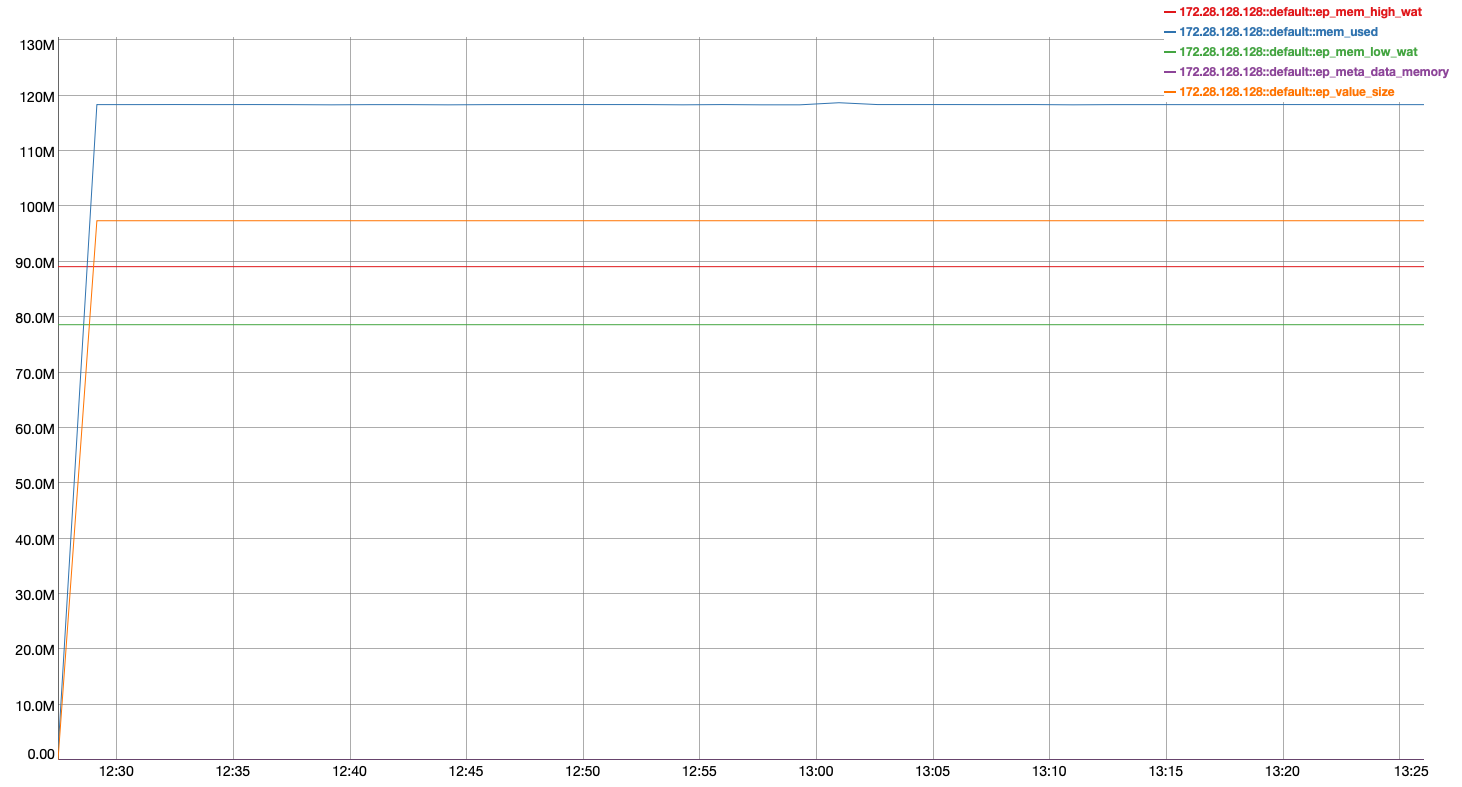
- We in DGM less than 50% resident
- We have two replicas
- Each document is about 3MB
- We're performing Duriabilty Majority writes
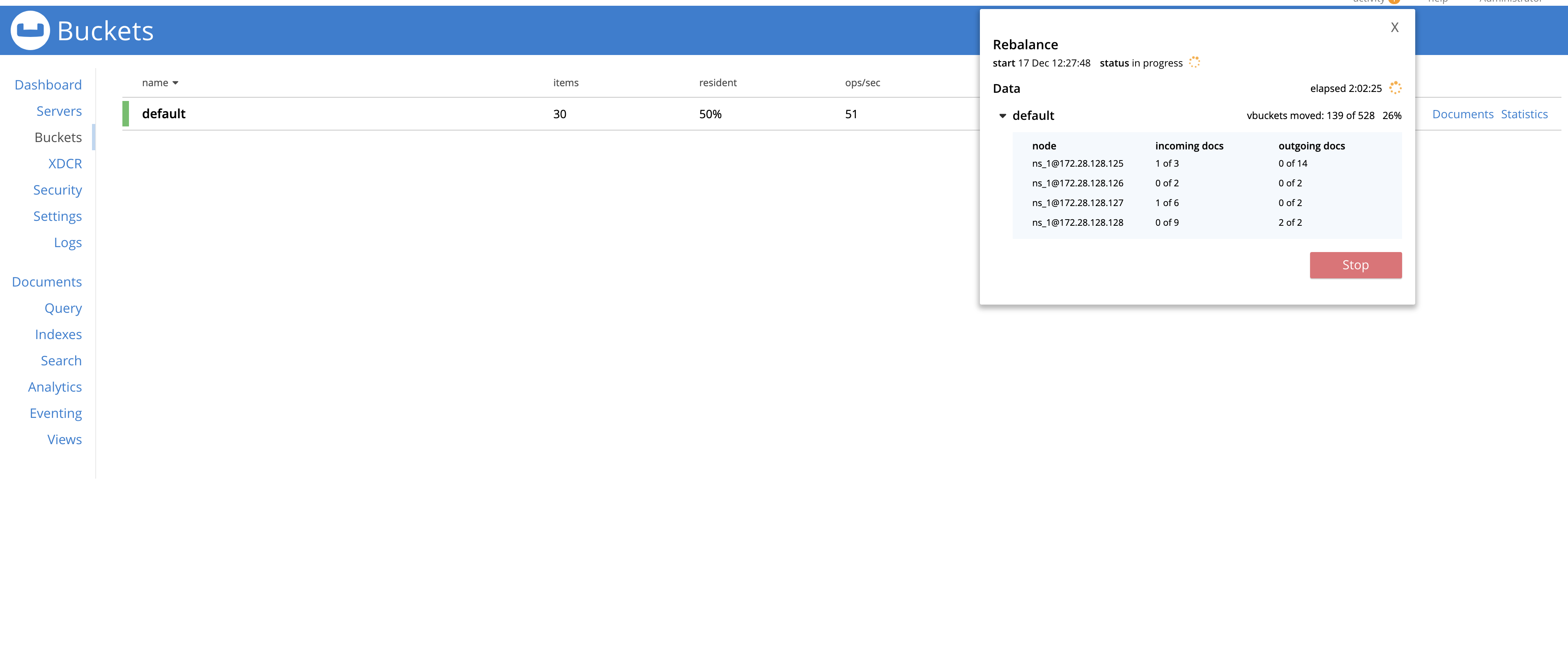
I've also managed to collect core dumps of memcached on each node:
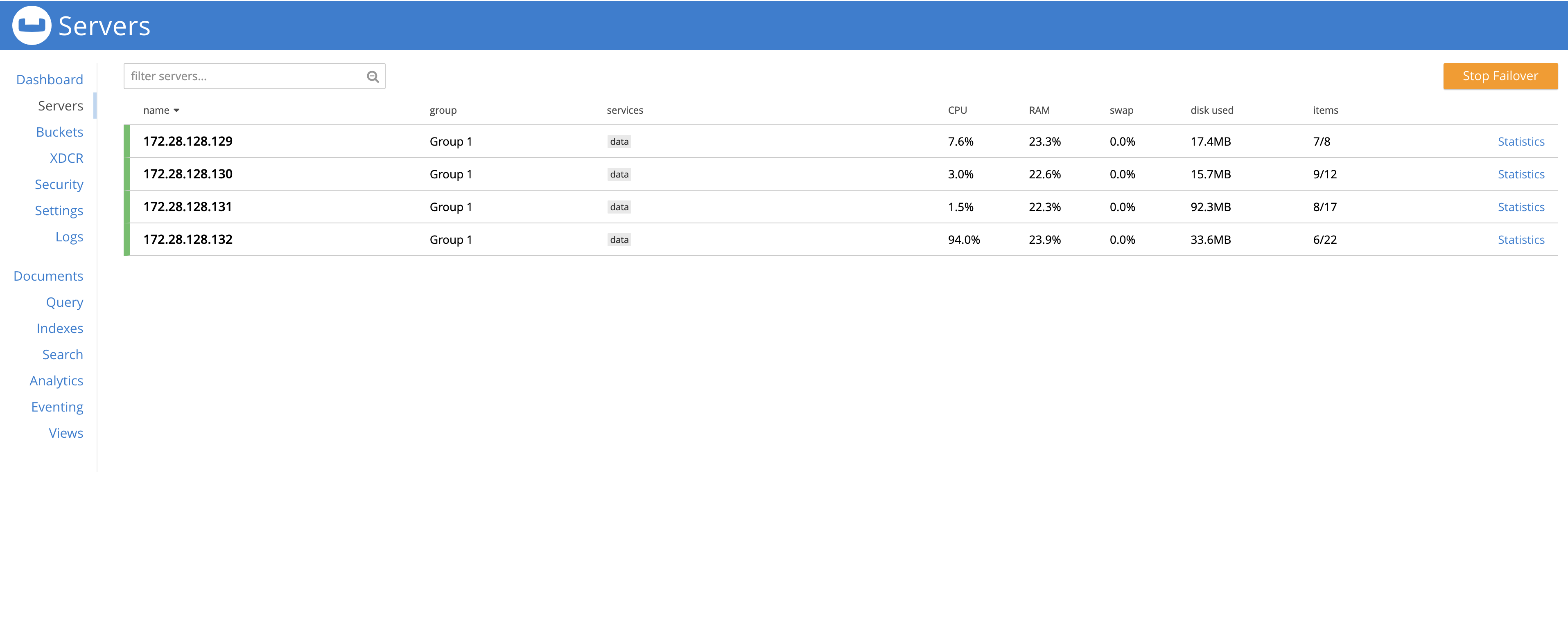
172.28.128.125=node1
172.28.128.126=node2
172.28.128.127=node3
172.28.128.128=node4
Build: couchbase-server-enterprise_6.5.1-6007-ubuntu16.04