Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
6.5.0
-
Untriaged
-
Yes
Description
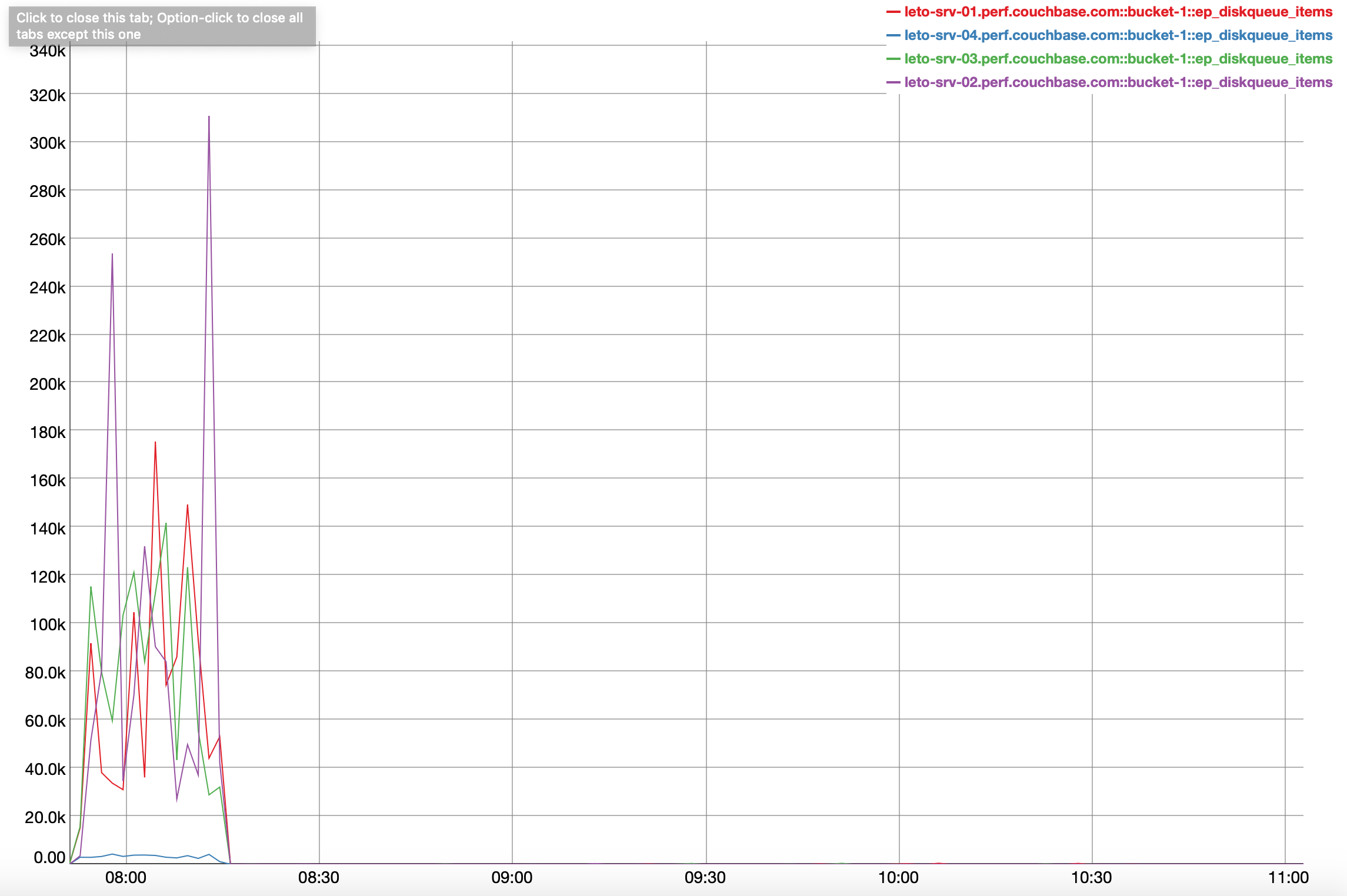
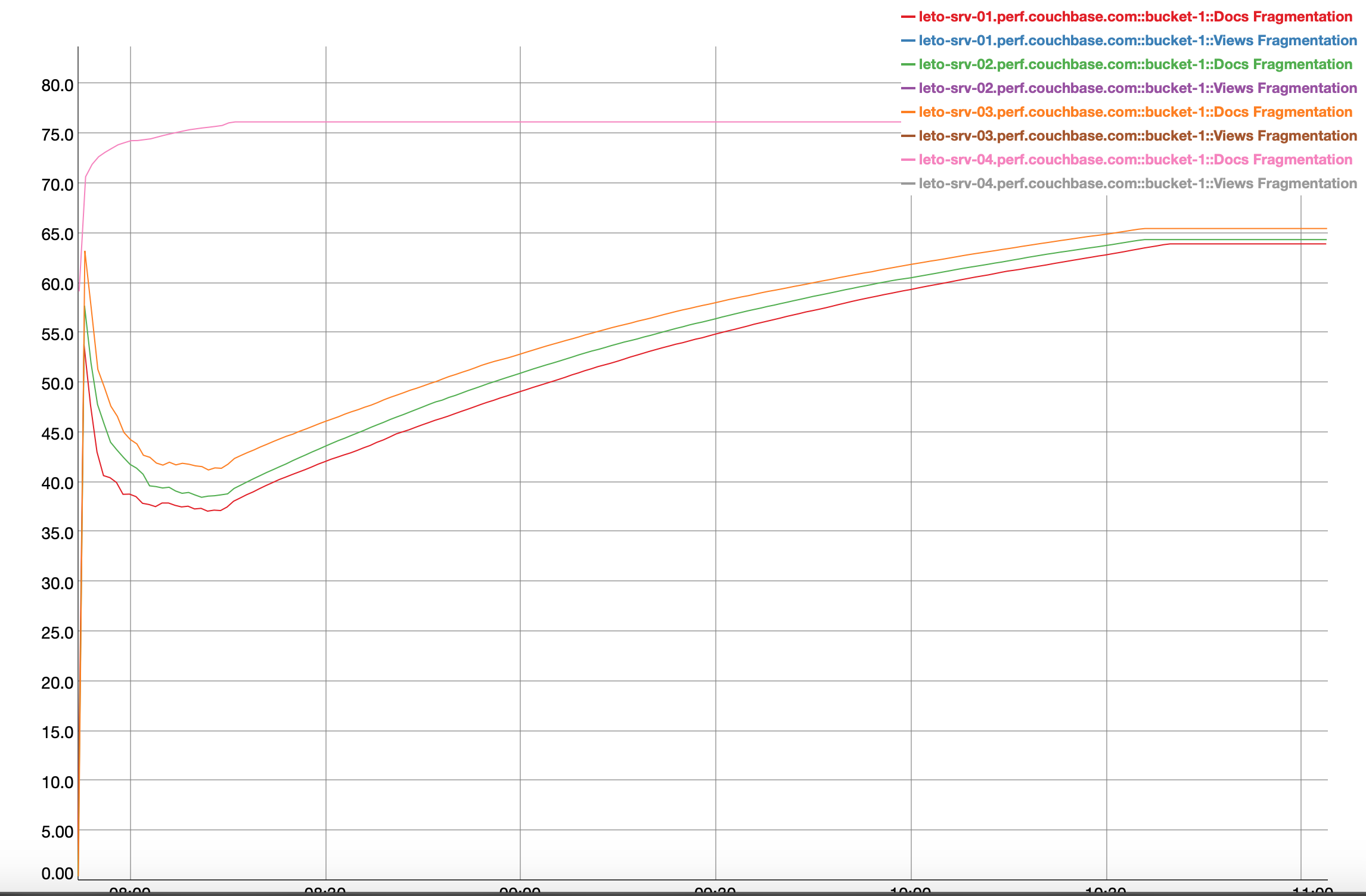
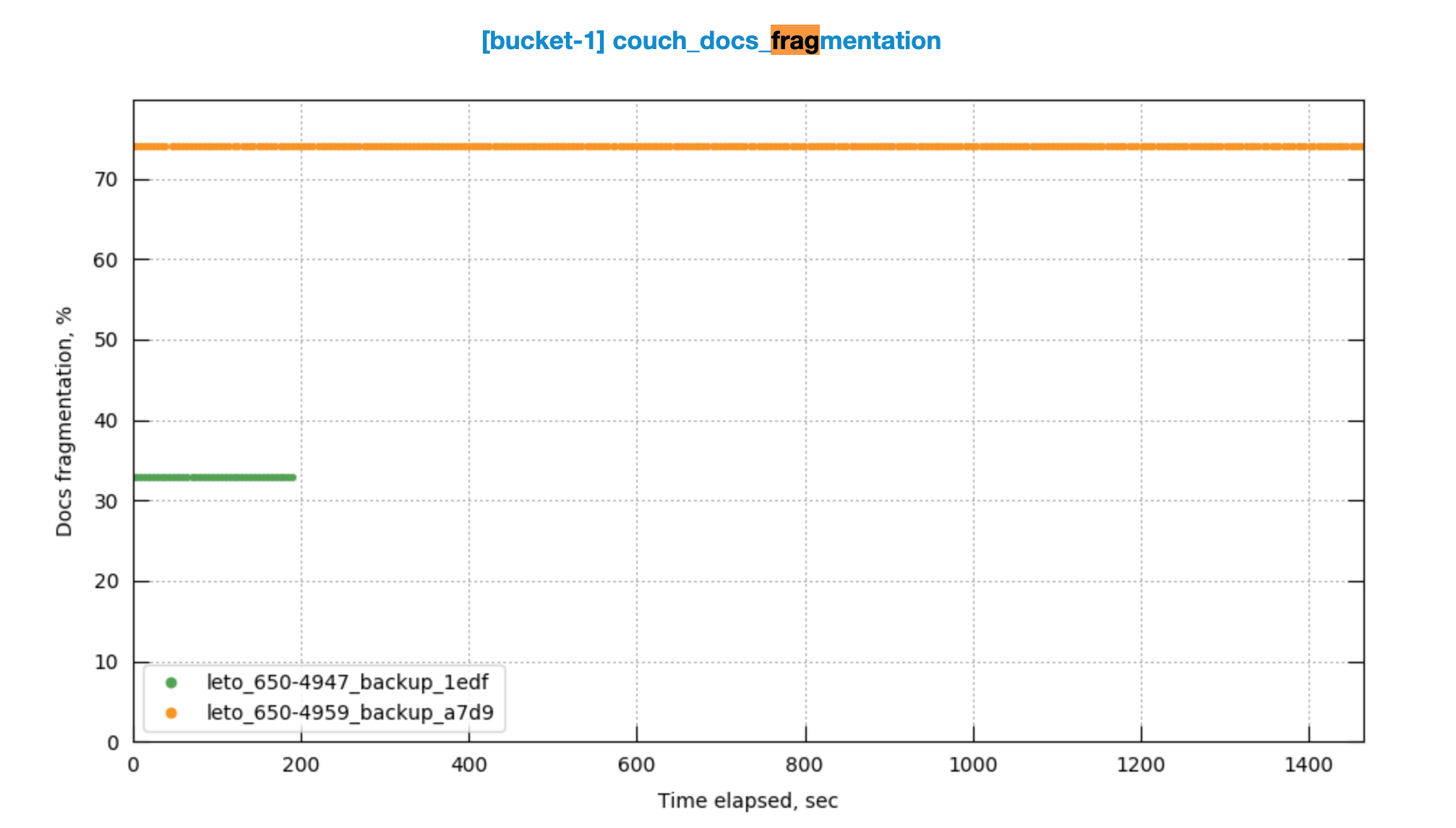
Observing ~90% drop in cbbackupmgr backup throughput in RC4 build .
Observing ~90% drop in cbbackupmgr backup throughput in RC4 build .