Description
Steps to reproduce this bug is as follows:
- Create a 4 node cluster (10.112.194.101, 10.112.194.102, 10.112.194.103, 10.112.194.104, with 10.112.194.101 being the node that initiates the cluster creation)
- Isolate two nodes 10.112.194.101 and 10.112.194.102 from each other. So this introduces a network partition such that these two nodes cannot communicate with
each other, but are able to communicate with all other nodes.
This can be done by executing the following commands inside each of the two nodes above
Execute in node 1 and node 2 respectively,
iptables -A INPUT -s 10.112.194.102 -j DROP |
iptables -A INPUT -s 10.112.194.101 -j DROP |
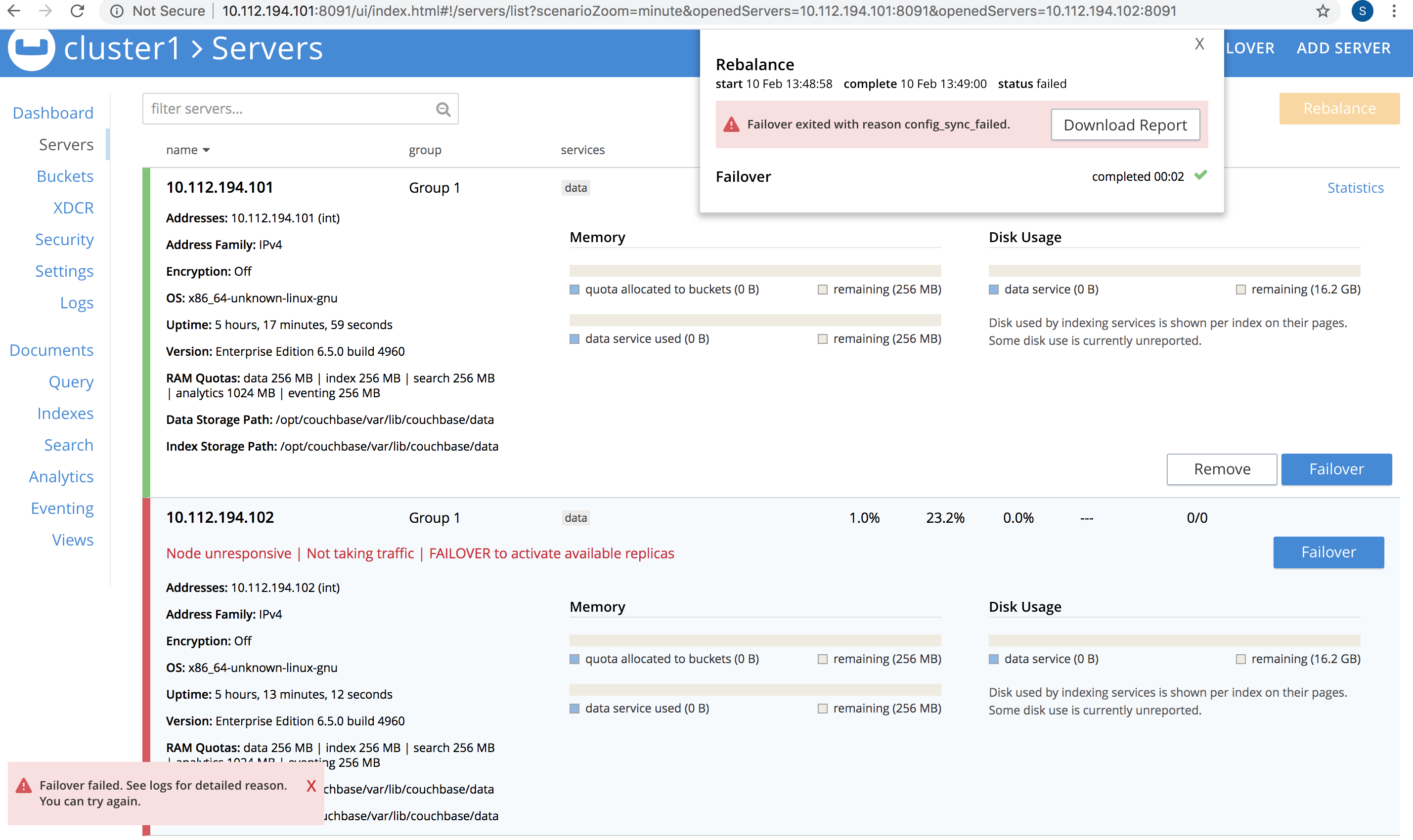
3. Hard failover the first node with a rest call to third node. So in node 1 execute:
curl -v -X POST -u Administrator:password http://10.112.194.103:8091/controller/failOver -d 'otpNode=ns_1@10.112.194.101' |
Failover fails with the above mentioned error. Screenshots are attached.
I found this intermittent bug originally when we run jepsen-durability-misc-daily-new tests (http://qa.sc.couchbase.com/job/jepsen-durability-misc-daily-new/) for the partition-failover workload(and when the failed over node happens to be the first node in the cluster).
Nemesis crashes because failover fails with the above mentioned error and results in "unknown" error. The config for that is as follows:
workload=partition-failover,node-count=6,replicas=2,no-autofailover,kv-timeout=30,durability=0:100:0:0 |
Node that this may fail or succeed depending upon whether the failed over node is first node of the cluster or not.