Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
7.0.0-4432-enterprise
-
Untriaged
-
Centos 64-bit
-
1
-
No
Description
Script to Repro
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/win10-bucket-ops.ini rerun=False,quota_percent=95,crash_warning=True -t bucket_collections.collections_rebalance.CollectionsRebalance.test_data_load_collections_with_graceful_failover_recovery,nodes_init=5,nodes_failover=1,recovery_type=delta,override_spec_params=durability;replicas,durability=MAJORITY_AND_PERSIST_TO_ACTIVE,replicas=2,bucket_spec=multi_bucket.buckets_all_membase_for_rebalance_tests_with_ttl,data_load_spec=ttl_load1,data_load_stage=during,skip_validations=False,rerun=False'
|
Steps to Repro
1) Create a 5 node cluster
2021-02-10 04:11:54,838 | test | INFO | pool-1-thread-6 | [table_view:display:72] Rebalance Overview
-----------------------++-------------------------------------------------
| Nodes | Services | Version | CPU | Status |
-----------------------++-------------------------------------------------
| 172.23.98.196 | kv | 7.0.0-4432-enterprise | 7.02282417858 | Cluster node |
| 172.23.98.195 | None | <--- IN — | ||
| 172.23.121.10 | None | <--- IN — | ||
| 172.23.104.186 | None | <--- IN — | ||
| 172.23.120.206 | None | <--- IN — |
-----------------------++-------------------------------------------------
2) Create buckets/scopes/collections/data
2021-02-10 04:17:26,428 | test | INFO | MainThread | [table_view:display:72] Bucket statistics
-----------------++--------------------------------------------------------------
| Bucket | Type | Replicas | Durability | TTL | Items | RAM Quota | RAM Used | Disk Used |
-----------------++--------------------------------------------------------------
| bucket1 | couchbase | 2 | none | 350 | 20000 | 1572864000 | 116284664 | 138497807 |
| bucket2 | couchbase | 2 | none | 350 | 30000 | 1572864000 | 118290072 | 292333273 |
| default | couchbase | 2 | none | 350 | 100084 | 7864320000 | 173652712 | 386482149 |
-----------------++--------------------------------------------------------------
3) Hard failover a node(172.23.120.206)
2021-02-10 04:17:35,237 | test | INFO | MainThread | [collections_rebalance:rebalance_operation:545] failing over nodes [ip:172.23.120.206 port:8091 ssh_username:root]
|
2021-02-10 04:21:47,165 | test | WARNING | MainThread | [rest_client:get_nodes:1697] 172.23.120.206 - Node not part of cluster inactiveFailed
|
4) Do delta recovery + rebalance
2021-02-10 04:22:07,907 | test | INFO | pool-1-thread-7 | [table_view:display:72] Rebalance Overview
-----------------------++-------------------------------------------------
| Nodes | Services | Version | CPU | Status |
-----------------------++-------------------------------------------------
| 172.23.98.196 | kv | 7.0.0-4432-enterprise | 38.842345773 | Cluster node |
| 172.23.98.195 | kv | 7.0.0-4432-enterprise | 19.1934660541 | Cluster node |
| 172.23.104.186 | kv | 7.0.0-4432-enterprise | 33.0700636943 | Cluster node |
| 172.23.120.206 | kv | 7.0.0-4432-enterprise | 1.58172231986 | Cluster node |
| 172.23.121.10 | kv | 7.0.0-4432-enterprise | 47.2741233683 | Cluster node |
-----------------------++-------------------------------------------------
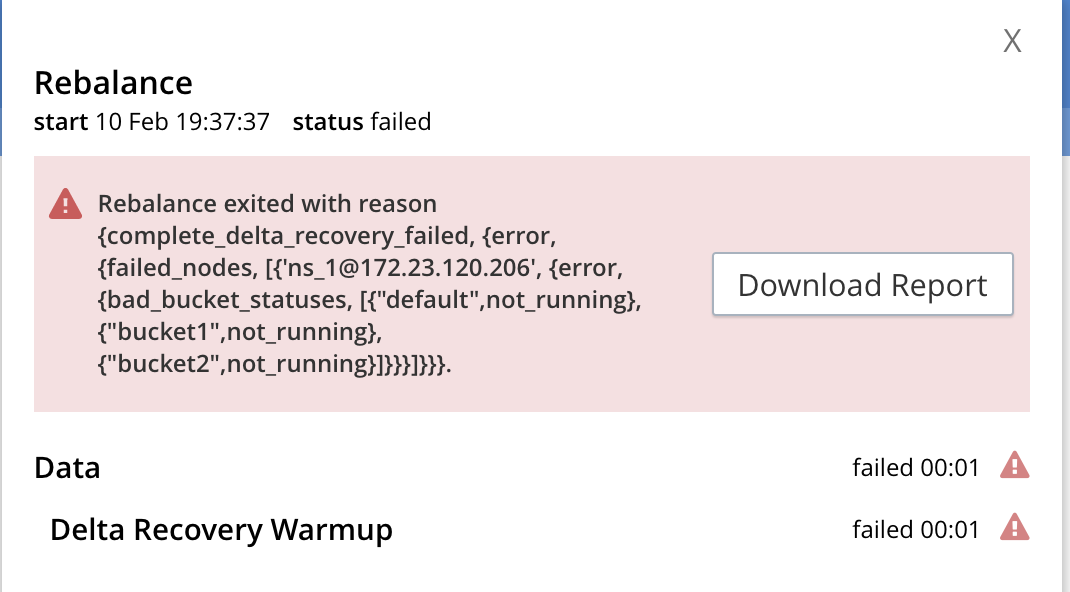
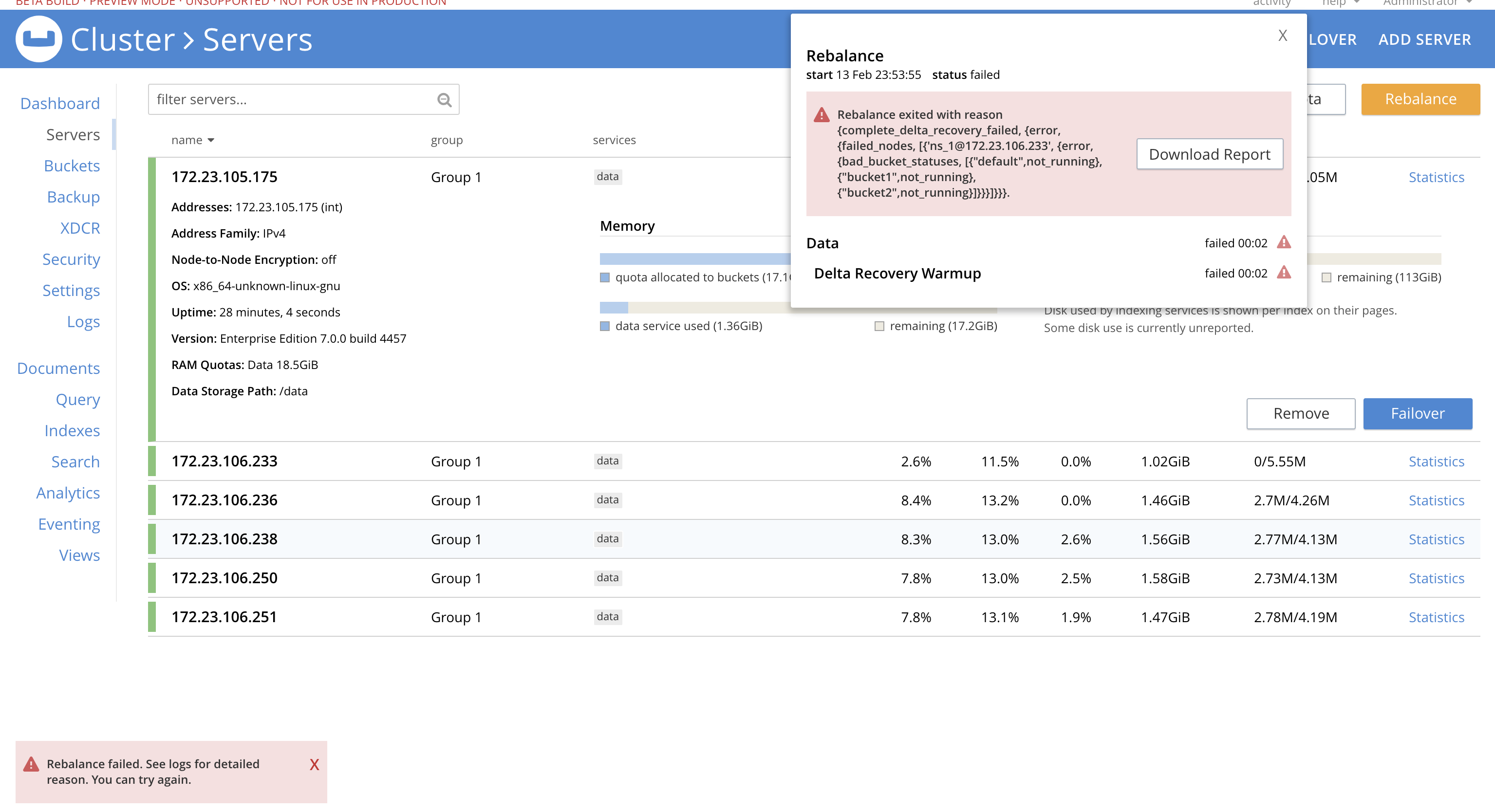
Rebalance fails as shown below.
on 172.23.98.196
Rebalance exited with reason {complete_delta_recovery_failed,
|
{error,
|
{failed_nodes,
|
[{'ns_1@172.23.120.206',
|
{error,
|
{bad_bucket_statuses,
|
[{"default",not_running},
|
{"bucket1",not_running},
|
{"bucket2",not_running}]}}}]}}}.
|
Rebalance Operation Id = b8707bbdc934d2144308e0d7db4973ee
|
Haven't seen this failure before. I saw lot of test failures that involve delta recovery + rebalance tests fail because of this.
Attachments
Issue Links
- is duplicated by
-
-
- Closed
-