Details
-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
Cheshire-Cat
-
Untriaged
-
1
-
Unknown
Description
Build: 7.0.0 build 4619
Test: Eventing Volume
- Create 9 node cluster ( Eventing:3 , Kv:4,index:1,query:1)
- Create 15 handlers (3 of bucket op, timer,n1ql, SBM, curl)
- deploy bucket op, timers and N1ql
- Rebalance in 1 eventing node
- Start CRUD on bucket_op where no handler are deployed
- Verify handlers
- Load more data
- Add to 2 KV nodes
- deploy curl and SBM handlers
- Rebalance out 2 kv nodes
- Verify all handlers
- Pause bucket op and timers
- Swap 2 kv nodes 1 after another
- load more data
- Rebalance in 2 eventing nodes
- Resume bucket op and timers
- Verify all handlers
- load more data
- rebalance out 2 eventing nodes
- verify all handlers
- load more data
- Swap 2 eventing nodes 1 after another
- Verify all handlers
- load all data
- Rebalance in kv and eventing node
- Verify all handlers
- load all data
- Rebalance out 1 kv 1 eventing
- Verify all handlers
- load all data
- Swap 1 kv and 1 eventing
- Verify all handlers
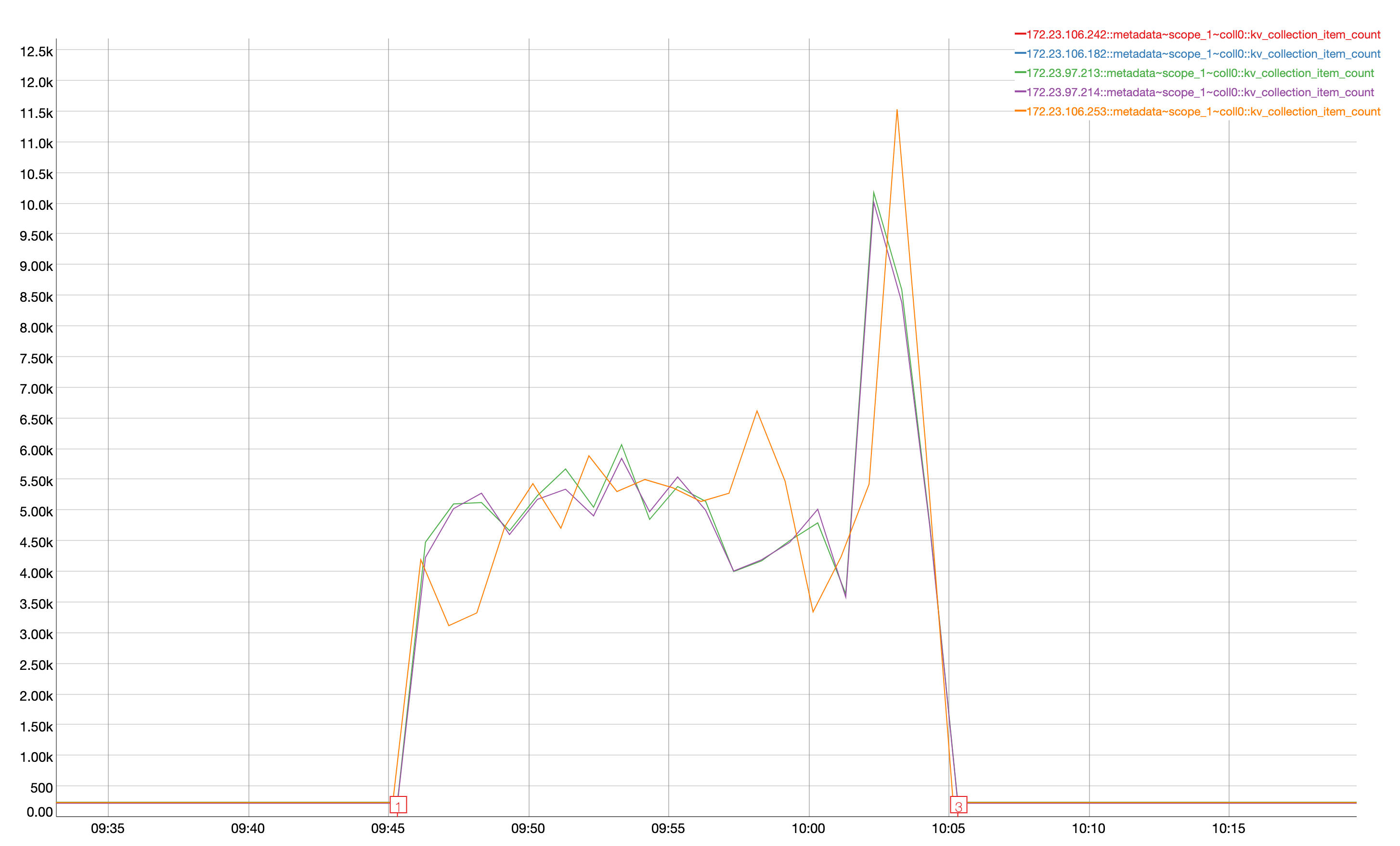
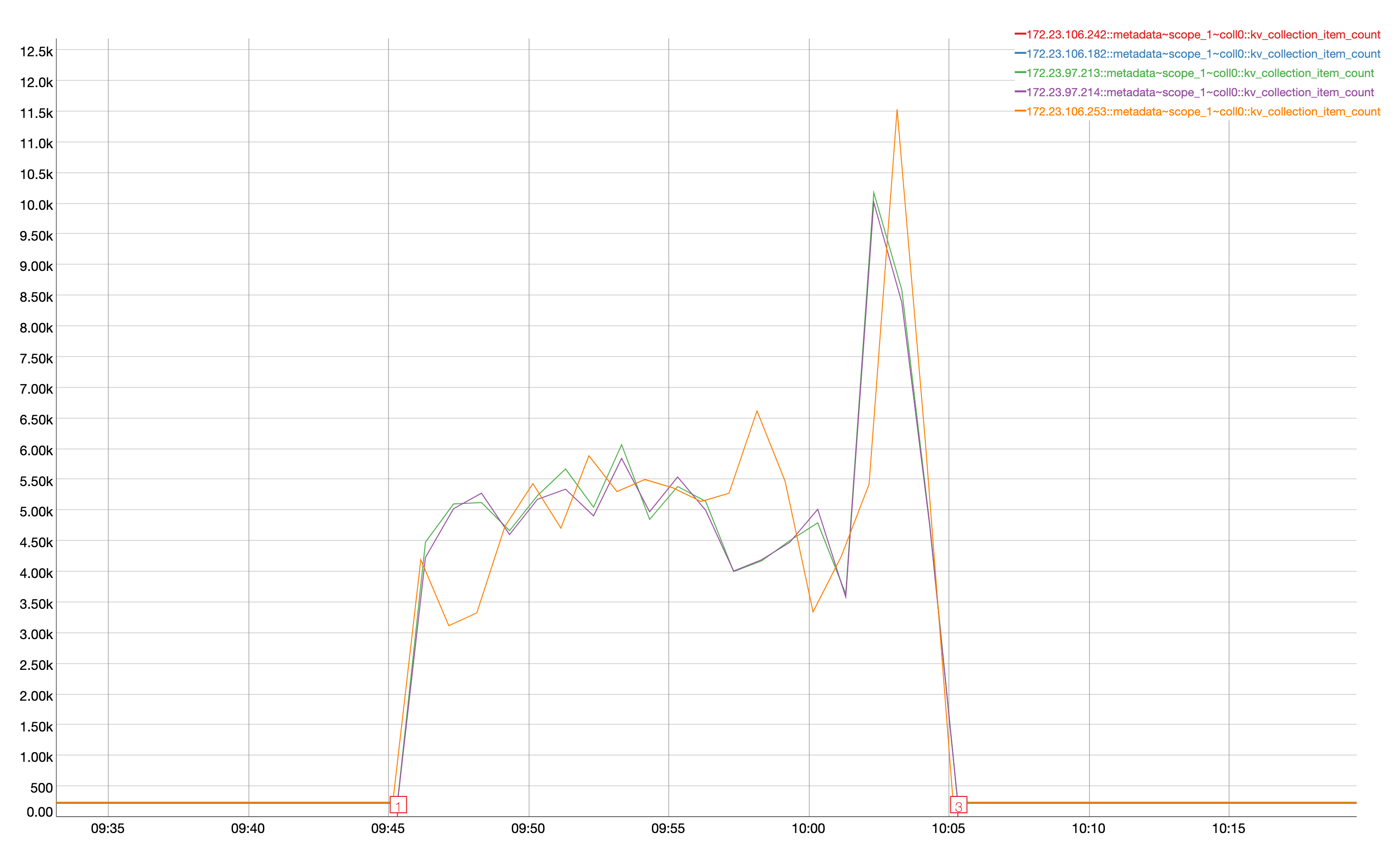
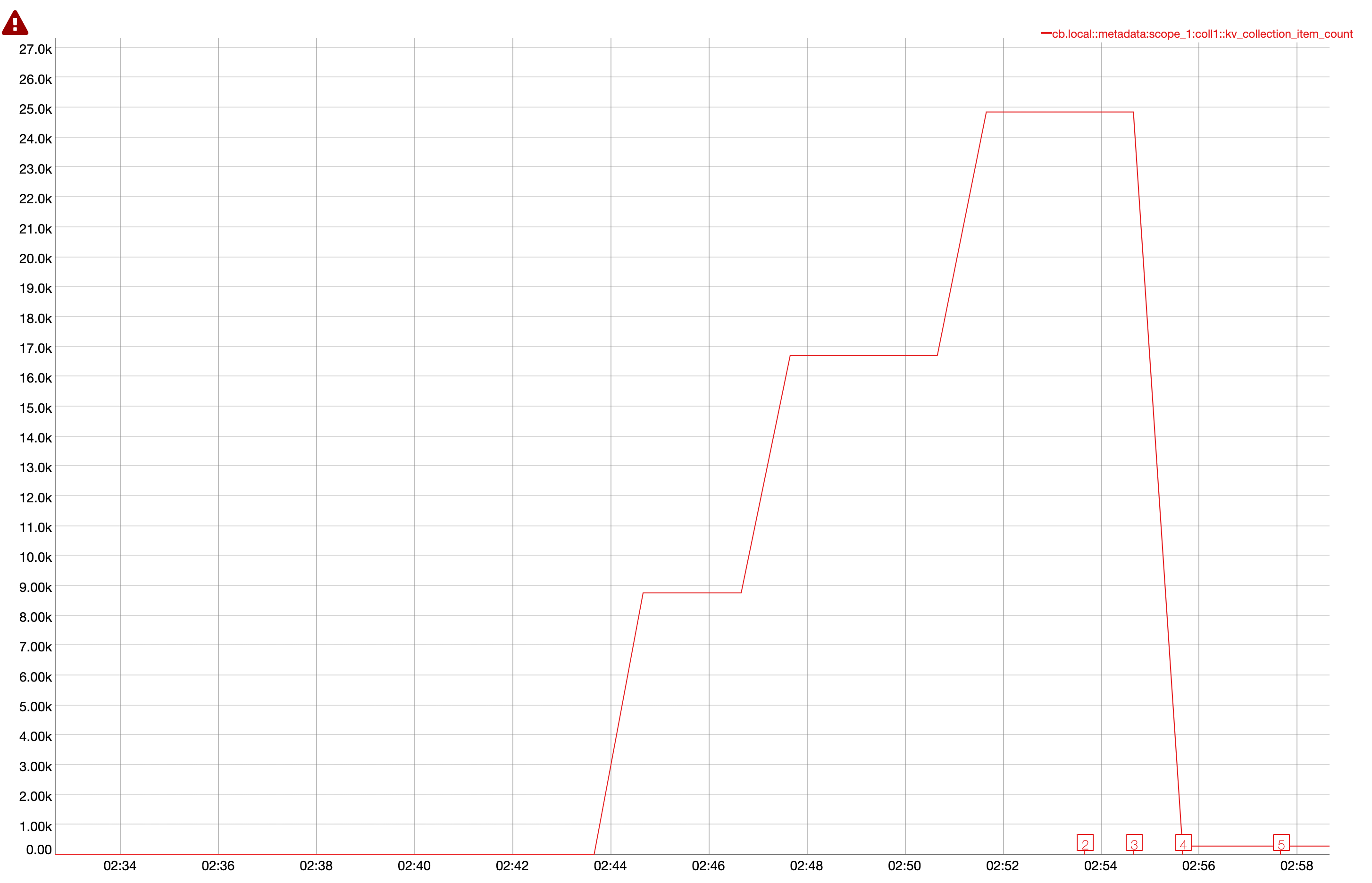
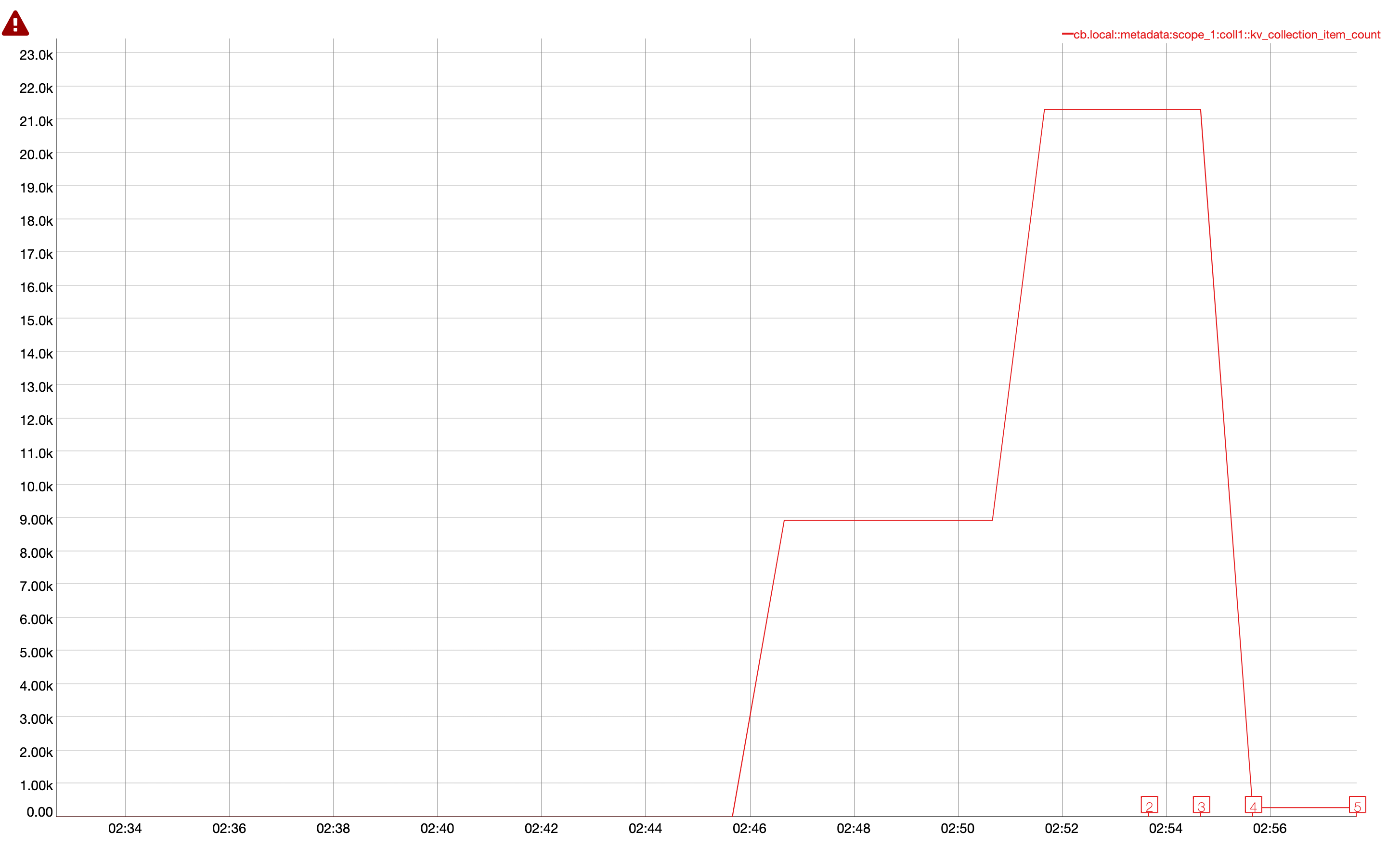
Observed that all verification for timer handler failed due to data miss match and seeing the documents in metadata
select count(*) from metadata.scope_1.coll0 where
|
meta().id like 'eventing::%:sp' and sta != stp; --> 128
|
|
|
select count(*) from metadata.scope_1.coll1 where meta().id like 'eventing::%:sp' and sta != stp; --> 128
|
|
|
select count(*) from metadata.scope_1.coll2 where meta().id like 'eventing::%:sp' and sta != stp; --> 128
|
|
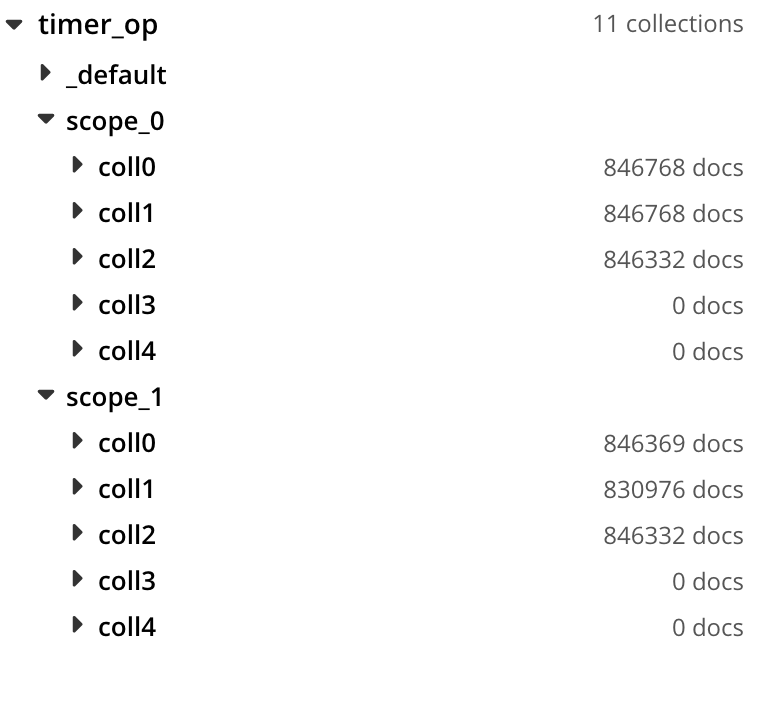
| Handler | Source Scope | Destination Scope |
| timers0_0 | timer_op.scope_0.coll0(4095000) | timer_op.scope_1.coll0(4094498) |
| timers1_0 | timer_op.scope_0.coll1(4091100) | timer_op.scope_1.coll1(4089924) |
| timers2_0 | timer_op.scope_0.coll2(4089600) | timer_op.scope_1.coll2(4089127) |
N1ql queries failing with CAS miss match
2021-03-05T13:20:27.900-08:00 [INFO] "Query failed: " {"message":"SDK error : LCB_ERR_CAS_MISMATCH (209) Query error : {\n\"requestID\": \"1bc36320-7bb6-4e5f-a47d-d33f7c235c62\",\n\"clientContextID\": \"4@n1ql0_0.js(OnUpdate)\",\n\"signature\": null,\n\"results\": [\n],\n\"errors\": [{\"code\":12009,\"msg\":\"DML Error, possible causes include CAS mismatch or concurrent modificationFailed to perform UPSERT - cause: dial tcp 172.23.105.25:11210: connect: cannot assign requested address\"}],\n\"status\": \"errors\",\n\"metrics\": {\"elapsedTime\": \"23.135053ms\",\"executionTime\": \"23.080655ms\",\"resultCount\": 0,\"resultSize\": 0,\"serviceLoad\": 15,\"errorCount\": 1}\n}\n","stack":"Error\n at N1QL (<anonymous>)\n at OnUpdate (n1ql0_0.js:4:21)"} 2021-03-05T13:20:27.875-08:00 [INFO] "Query failed: " {"message":"SDK error : LCB_ERR_CAS_MISMATCH (209) Query error : {\n\"requestID\": \"1570ce91-f811-469c-b4b3-0ac8f1b57cca\",\n\"clientContextID\": \"4@n1ql0_0.js(OnUpdate)\",\n\"signature\": null,\n\"results\": [\n],\n\"errors\": [{\"code\":12009,\"msg\":\"DML Error, possible causes include CAS mismatch or concurrent modificationFailed to perform UPSERT - cause: dial tcp 172.23.105.25:11210: connect: cannot assign requested address\"}],\n\"status\": \"errors\",\n\"metrics\": {\"elapsedTime\": \"18.964561ms\",\"executionTime\": \"18.922147ms\",\"resultCount\": 0,\"resultSize\": 0,\"serviceLoad\": 9,\"errorCount\": 1}\n}\n","stack":"Error\n at N1QL (<anonymous>)\n at OnUpdate (n1ql0_0.js:4:21)"}
|