Details
-
Bug
-
Resolution: Cannot Reproduce
-
 Critical
Critical
-
Cheshire-Cat
-
Untriaged
-
Centos 64-bit
-
1
-
Unknown
Description
Build: 7.0.0-4797
After execution if the following test
./testrunner -i /tmp/testexec.22646.ini -p get-cbcollect-info=True,disable_HTP=True,get-logs=True,stop-on-failure=False,index_type=scorch,fts_quota=750,run_via_n1ql=True,custom_map_add_non_indexed_fields=False,GROUP=N1QL_MATCH_PHRASE,query_types=N1QL_MATCH_PHRASE -t fts.stable_topology_fts.StableTopFTS.index_query_custom_mapping,items=1000,custom_map=True,num_custom_analyzers=1,compare_es=True,cm_id=105,num_queries=100,GROUP=BUCKETS;P0;SKIP_FOR_N1QL;N1QL_MATCH_PHRASE;COLLECTIONS |
Job name:
centos-fts_custom-map-n1ql-rqg-scorch-match-phrase_6.5_P1
|
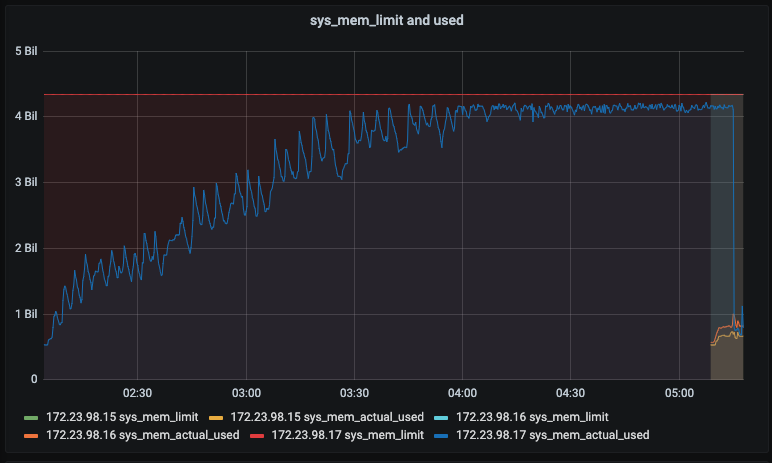
cluster rebalance was failed with the following messages:
[2021-03-31 04:15:05,554] - [rest_client:1864] ERROR - {'status': 'none', 'errorMessage': 'Rebalance failed. See logs for detailed reason. You can try again.'} - rebalance failed |
[2021-03-31 04:15:05,568] - [rest_client:3816] INFO - Latest logs from UI on 172.23.98.17: |
[2021-03-31 04:15:05,568] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'critical', 'code': 0, 'module': 'ns_orchestrator', 'tstamp': 1617189297176, 'shortText': 'message', 'text': 'Rebalance exited with reason {service_rebalance_failed,fts,\n {agent_died,<0.3286.0>,\n {lost_connection,shutdown}}}.\nRebalance Operation Id = 505bbfc322316c65568f2883ccff257d', 'serverTime': '2021-03-31T04:14:57.176Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'info', 'code': 0, 'module': 'ns_log', 'tstamp': 1617189297162, 'shortText': 'message', 'text': "Service 'fts' exited with status 137. Restarting. Messages:\n2021-03-31T04:14:55.582-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:55.604-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:55.615-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:55.625-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:55.648-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:51.641-07:00 [WARN] (GOCBCORE) memdClient read failure on conn `02769c42d8bd79fd/2f07c519c255cdd8` : EOF -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:55.671-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n2021-03-31T04:14:55.727-07:00 [WARN] (GOCBCORE) Failed to connect to host, bad bucket. -- cbgt.GocbcoreLogger.Log() at gocbcore_utils.go:615\n", 'serverTime': '2021-03-31T04:14:57.162Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'info', 'code': 0, 'module': 'ns_orchestrator', 'tstamp': 1617189285401, 'shortText': 'message', 'text': "Starting rebalance, KeepNodes = ['ns_1@172.23.98.17'], EjectNodes = ['ns_1@172.23.98.15',\n 'ns_1@172.23.98.16'], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = 505bbfc322316c65568f2883ccff257d", 'serverTime': '2021-03-31T04:14:45.401Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'warning', 'code': 102, 'module': 'menelaus_web', 'tstamp': 1617189285397, 'shortText': 'client-side error report', 'text': 'Client-side error-report for user "Administrator" on node \'ns_1@172.23.98.17\':\nUser-Agent:Python-httplib2/0.13.1 (gzip)\nStarting rebalance from test, ejected nodes [\'ns_1@172.23.98.15\', \'ns_1@172.23.98.16\']', 'serverTime': '2021-03-31T04:14:45.397Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'info', 'code': 11, 'module': 'menelaus_web', 'tstamp': 1617189285361, 'shortText': 'message', 'text': 'Deleted bucket "default"\n', 'serverTime': '2021-03-31T04:14:45.361Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'info', 'code': 0, 'module': 'ns_memcached', 'tstamp': 1617189284182, 'shortText': 'message', 'text': 'Shutting down bucket "default" on \'ns_1@172.23.98.17\' for deletion', 'serverTime': '2021-03-31T04:14:44.182Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.16', 'type': 'info', 'code': 0, 'module': 'ns_memcached', 'tstamp': 1617189284180, 'shortText': 'message', 'text': 'Shutting down bucket "default" on \'ns_1@172.23.98.16\' for deletion', 'serverTime': '2021-03-31T04:14:44.180Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'info', 'code': 0, 'module': 'ns_memcached', 'tstamp': 1617189010688, 'shortText': 'message', 'text': 'Bucket "default" loaded on node \'ns_1@172.23.98.17\' in 0 seconds.', 'serverTime': '2021-03-31T04:10:10.688Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.16', 'type': 'info', 'code': 0, 'module': 'ns_memcached', 'tstamp': 1617189003953, 'shortText': 'message', 'text': 'Bucket "default" loaded on node \'ns_1@172.23.98.16\' in 0 seconds.', 'serverTime': '2021-03-31T04:10:03.953Z'} |
[2021-03-31 04:15:05,569] - [rest_client:3817] ERROR - {'node': 'ns_1@172.23.98.17', 'type': 'info', 'code': 12, 'module': 'menelaus_web', 'tstamp': 1617189003862, 'shortText': 'message', 'text': 'Created bucket "default" of type: couchbase\n[{num_replicas,1},\n {replica_index,true},\n {ram_quota,1800404992},\n {durability_min_level,none},\n {flush_enabled,true},\n {num_threads,3},\n {eviction_policy,value_only},\n {conflict_resolution_type,seqno},\n {storage_mode,couchstore},\n {max_ttl,0},\n {compression_mode,passive}]', 'serverTime': '2021-03-31T04:10:03.862Z'} |
|
All cluster logs are attached