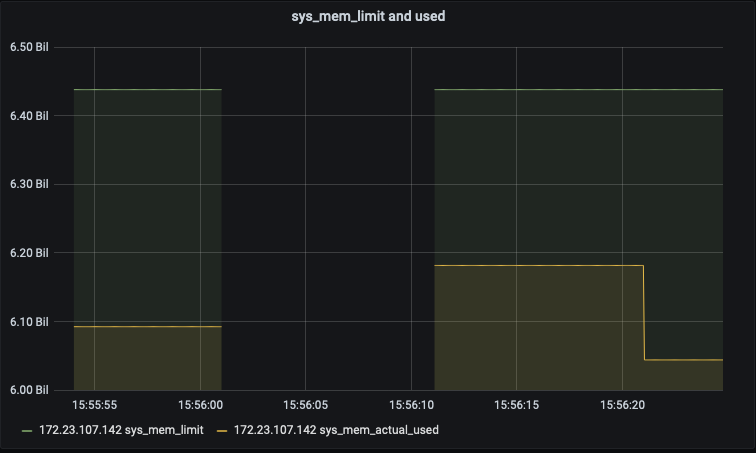
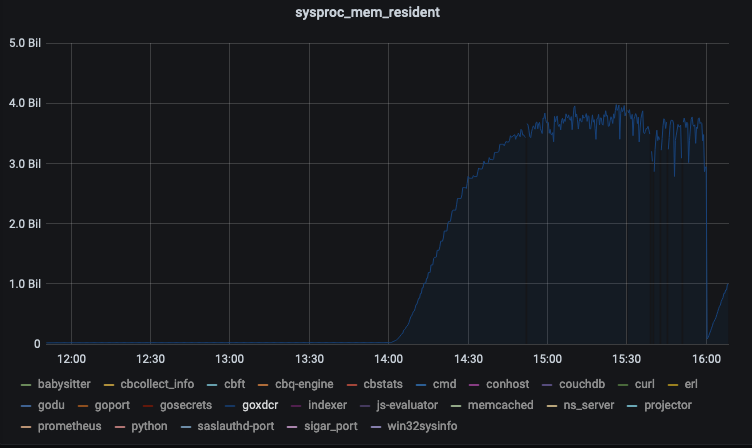
Details
-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
Cheshire-Cat
-
Untriaged
-
-
1
-
Unknown
Description
Steps to repro :
1. Setup a 2-node cluster running 6.6.2-9588 with kv+n1ql+index+fts services on both nodes
2. Install the sample buckets and create FTS indexes
3. Swap rebalance node2 with a spare node running 7.0.0-5016.
4. The cluster will now be in mixed mode
5. Add a new 7.0 node to the cluster.
The rebalance fails with error :
Rebalance exited with reason {pre_rebalance_janitor_run_failed,
|
"travel-sample",
|
{error,wait_for_memcached_failed,
|
['ns_1@172.23.107.142']}}.
|
Rebalance Operation Id = fda046d63e6f8a8b8014af2288bb470a
|
6. Retried the rebalance. That too failed as ns_server on the existing 7.0 node 172.23.107.142 has crashed with the following error -
Service 'ns_server' exited with status 1. Restarting. Messages:
|
working as port
|
4092: Booted. Waiting for shutdown request
|
working as port
|
eheap_alloc: Cannot allocate 1573200 bytes of memory (of type "heap").
|
|
|
Crash dump is being written to: erl_crash.dump...done
|
[os_mon] win32 supervisor port (win32sysinfo): Erlang has closed
|