Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
6.6.2, Cheshire-Cat
-
Triaged
-
Windows 64-bit
-
-
1
-
Yes
Description
- Create a 6.6.2 cluster on windows machines. Include all services in the cluster
- Create buckets and create secondary indexes. Drop and recreate atleast 1 index.
- Try to upgrade the data nodes in the cluster via graceful failover and re-add of the nodes.
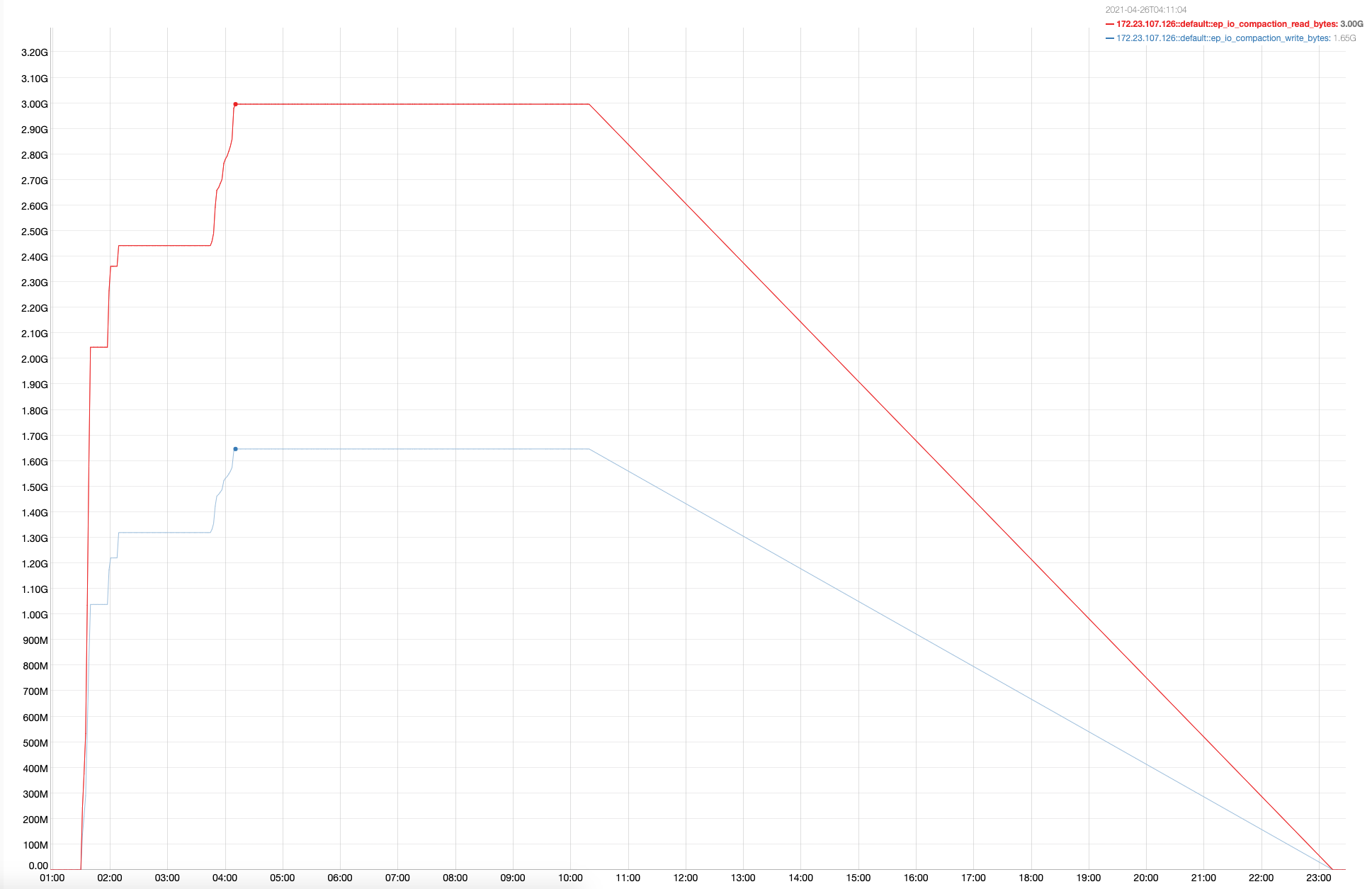
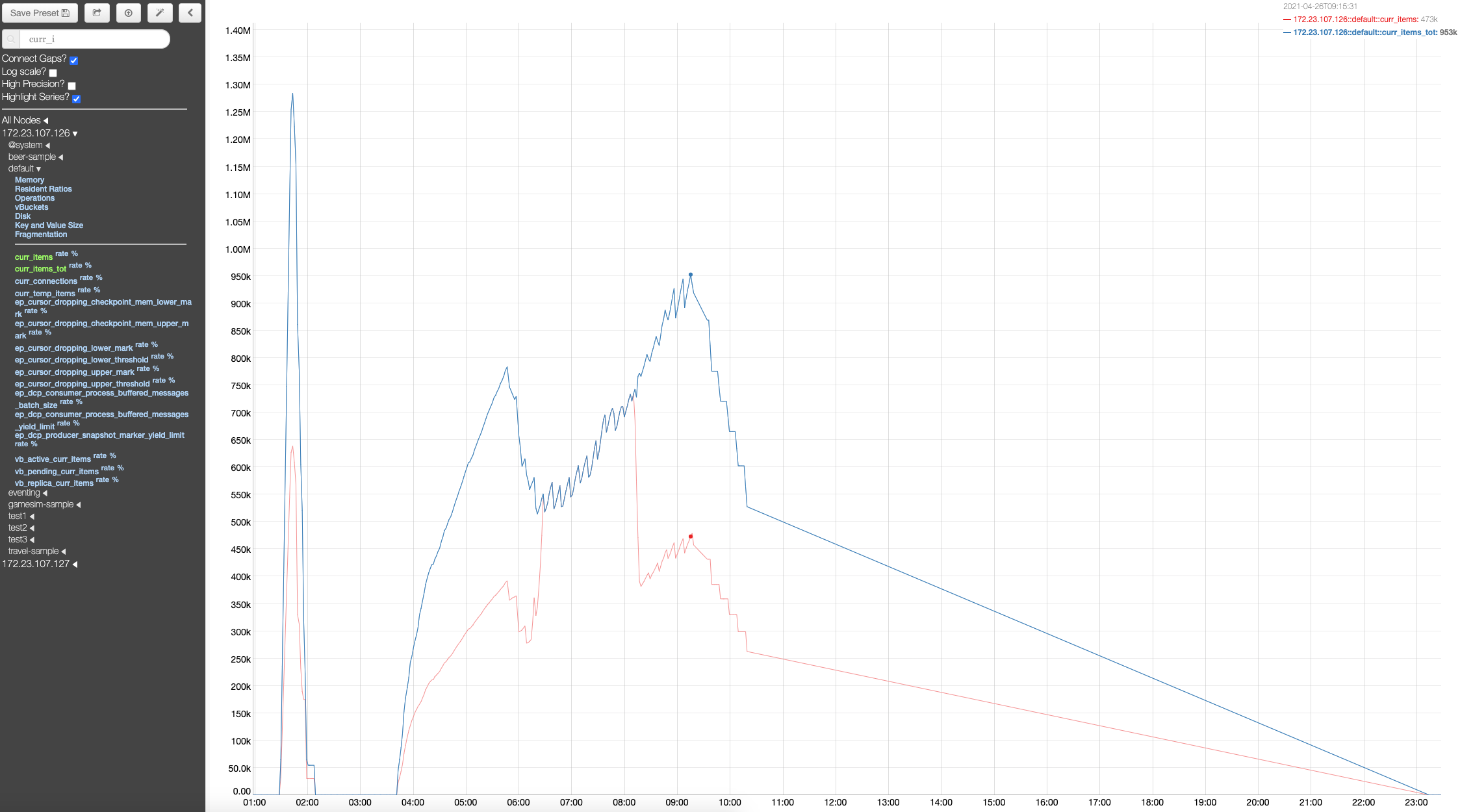
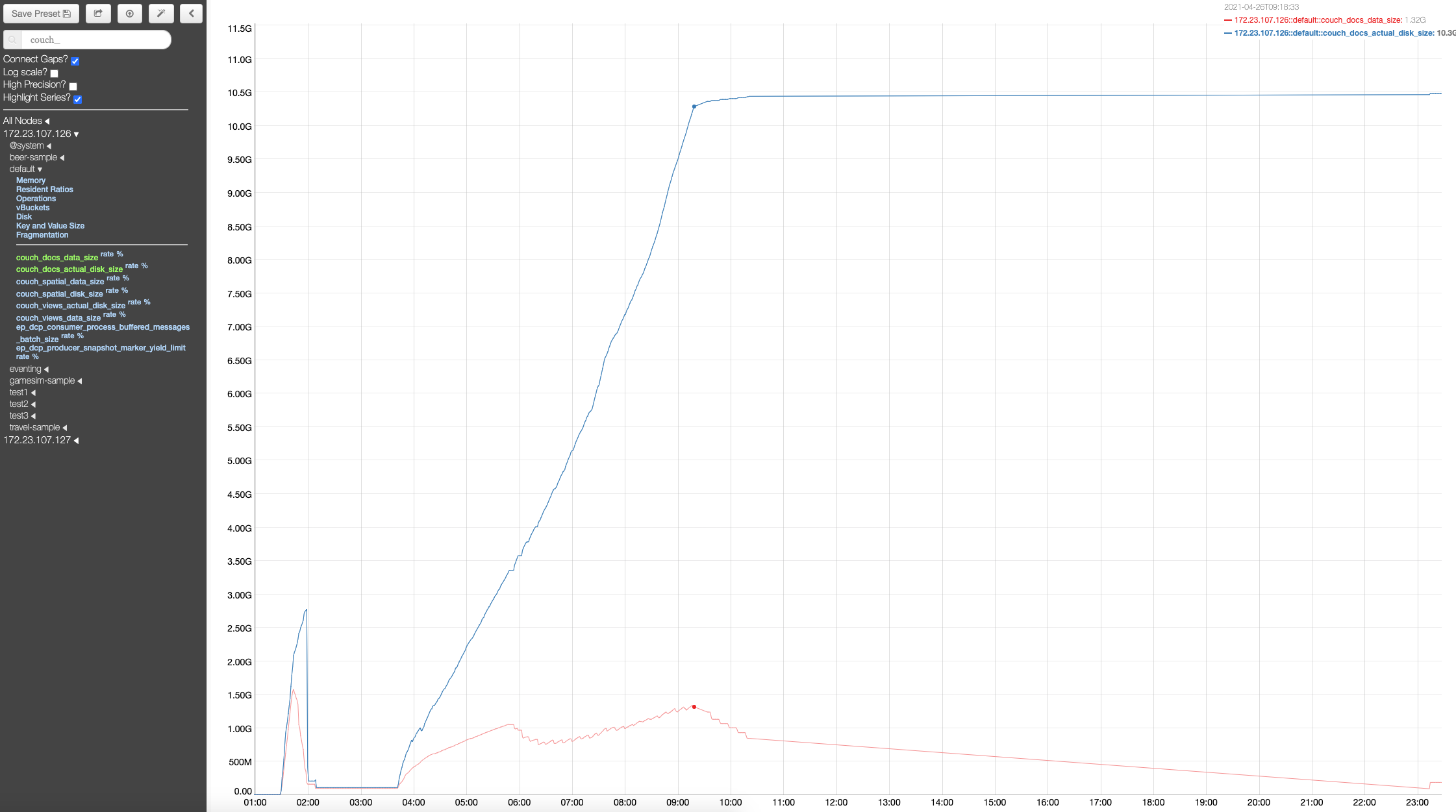
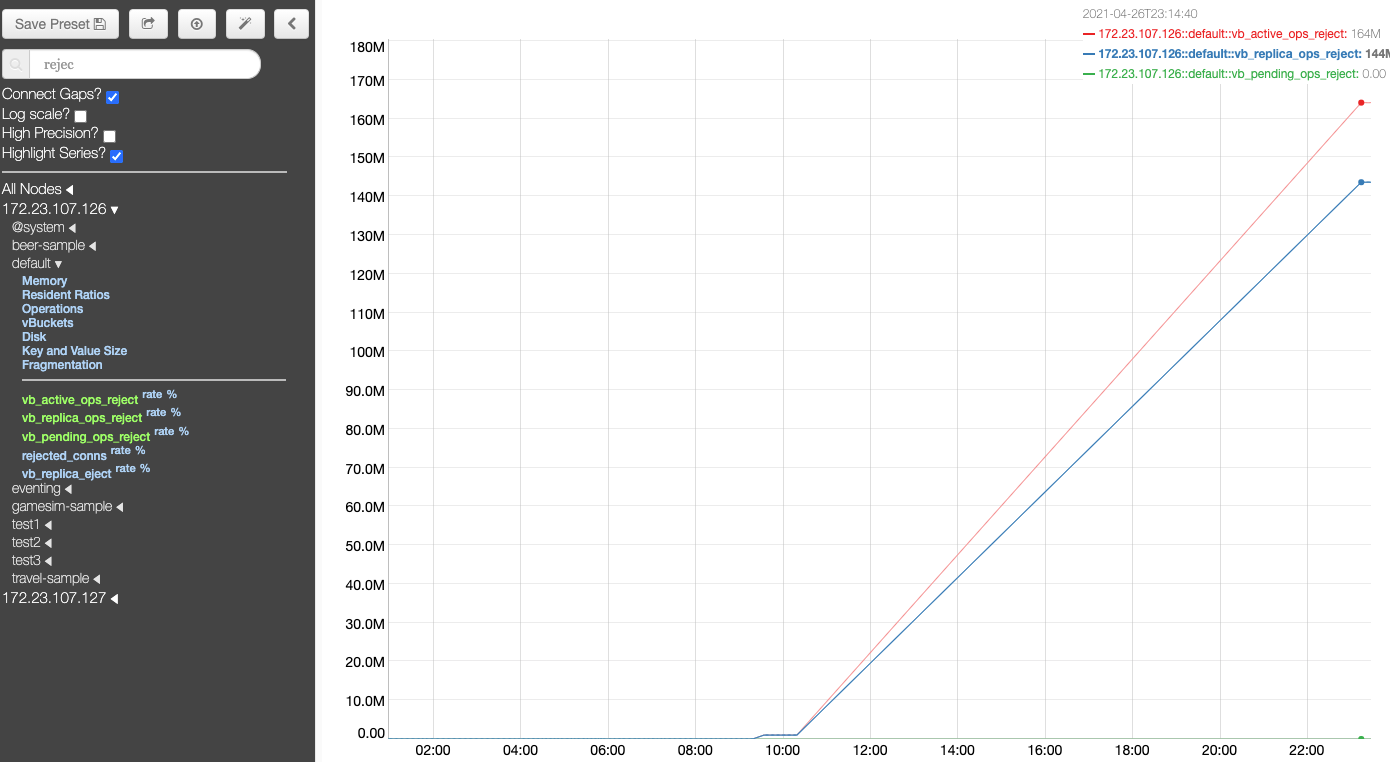
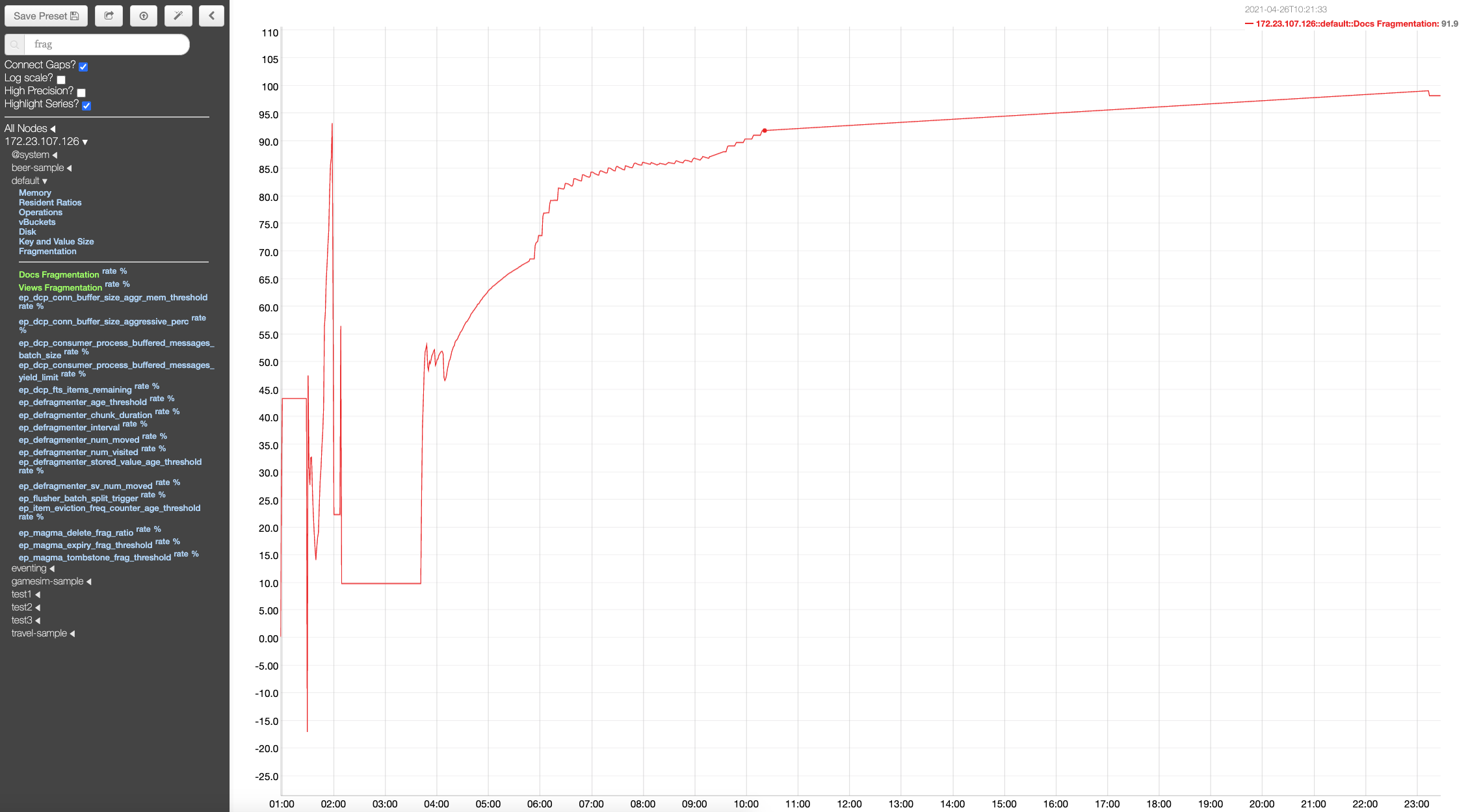
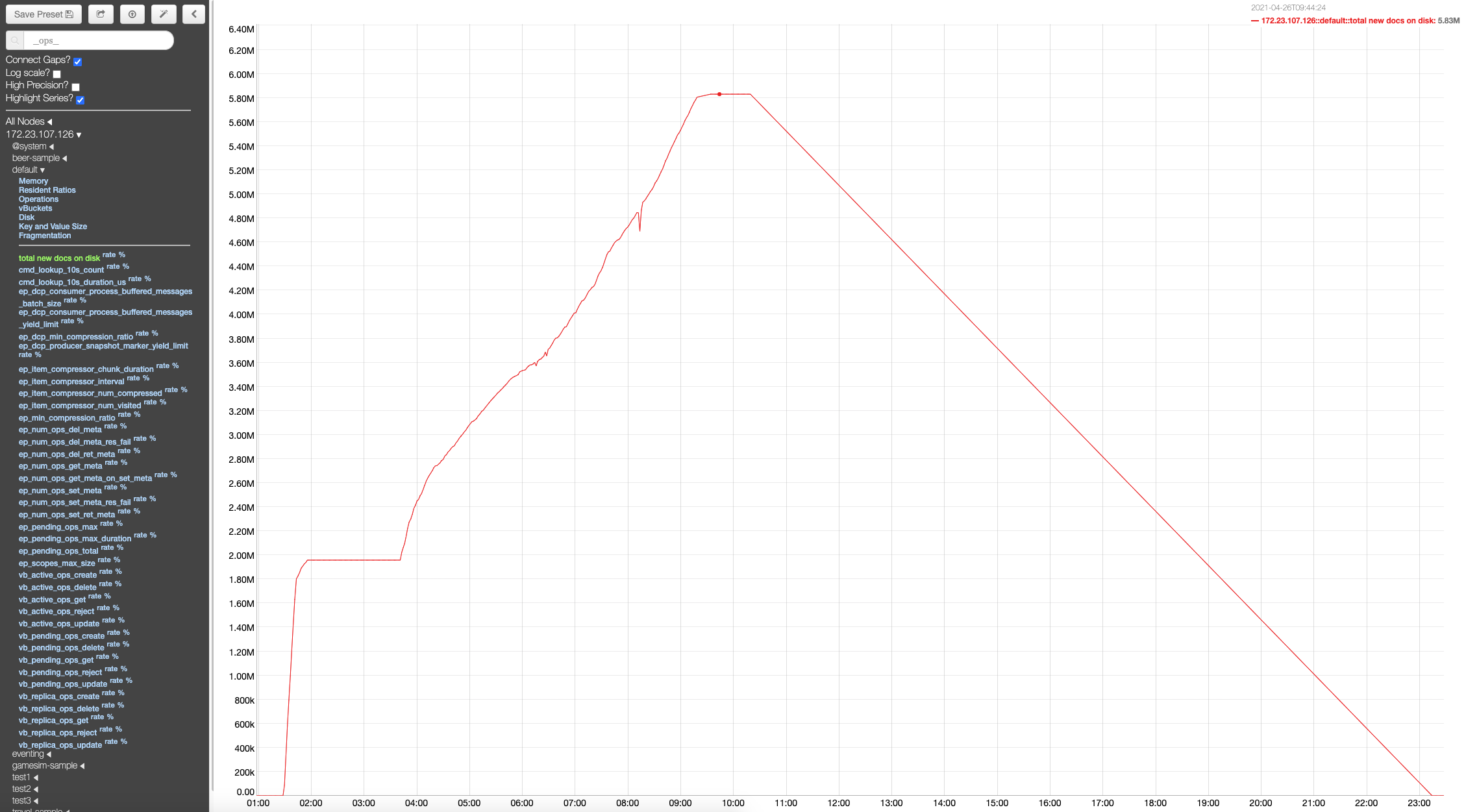
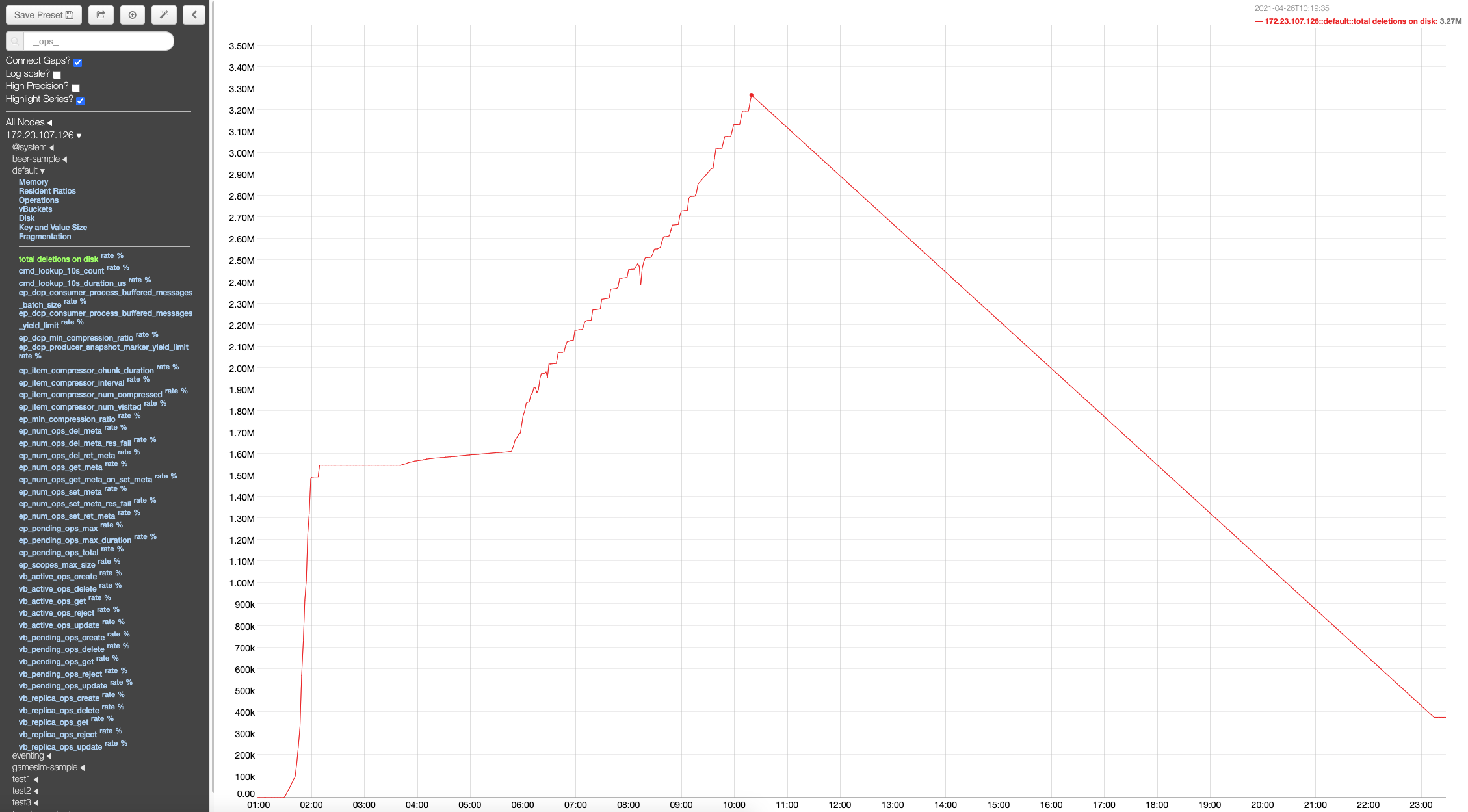
After re-adding the node, the disk space in the non-upgraded nodes shoots up disproportionately to the data present in the cluster. And the disk space isn't reclaimed even after the data is purged or has expired from the cluster. The disk space isn't reclaimed even after compaction or after setting the meta-data purge to 1 hour and waiting for few hours.
This is on a windows cluster, with 6 gb 6 core VMs. Upgrade path: 6.6.2 to 7.0.0-5016
This is a regression, since previous versions upgrade hadn't run into this issue.