Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
1.8.0
-
Security Level: Public
-
CentOS 54-64 bit
Description
Keeping this cluster alive.
http://ec2-67-202-63-126.compute-1.amazonaws.com:8091/index.html#sec=overview
Steps
1) Create 4 node cluster on 172.
2) Upgrade these 4 nodes cluster to 180.
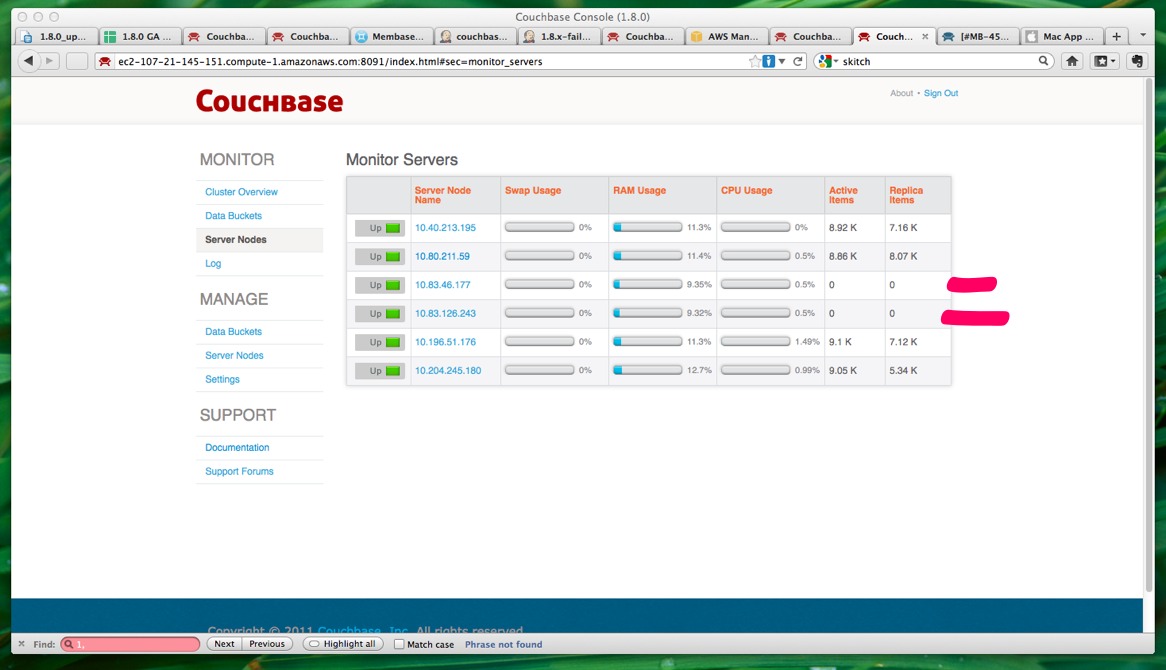
3) Rebalance in 2 new 180 nodes to this cluster at the same time. (10.83.47.43 and 10.112.27.9 are the brand new 180 nodes that were added onto the cluster. )
4) After rebalance. The active/replica item count on newly added node (10.83.47.43 and 10.112.27.9) is 0.
5) Post rebalance, Was able to load the data into (10.83.47.43 and 10.112.27.9) using python loader.
Attaching logs from all the nodes.
{kind=link}