Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
Untriaged
-
1
-
Unknown
Description
Build: 7.0.0 build 5046
Test: Eventing volume https://docs.google.com/document/d/1dJ6VhHtLaRLTPVKQm0EomakzUNZDz2x7xJv3JqZVuqw/edit?usp=sharing
- Create 9 node cluster ( Eventing:2 , Kv:5,index:1,query:1)
- Create 15 handlers (3 of bucket op, timer,n1ql, SBM, curl)
- deploy bucket op, timers and N1ql
- Rebalance in 1 eventing node
- Start CRUD on bucket_op where no handler are deployed
- Verify handlers
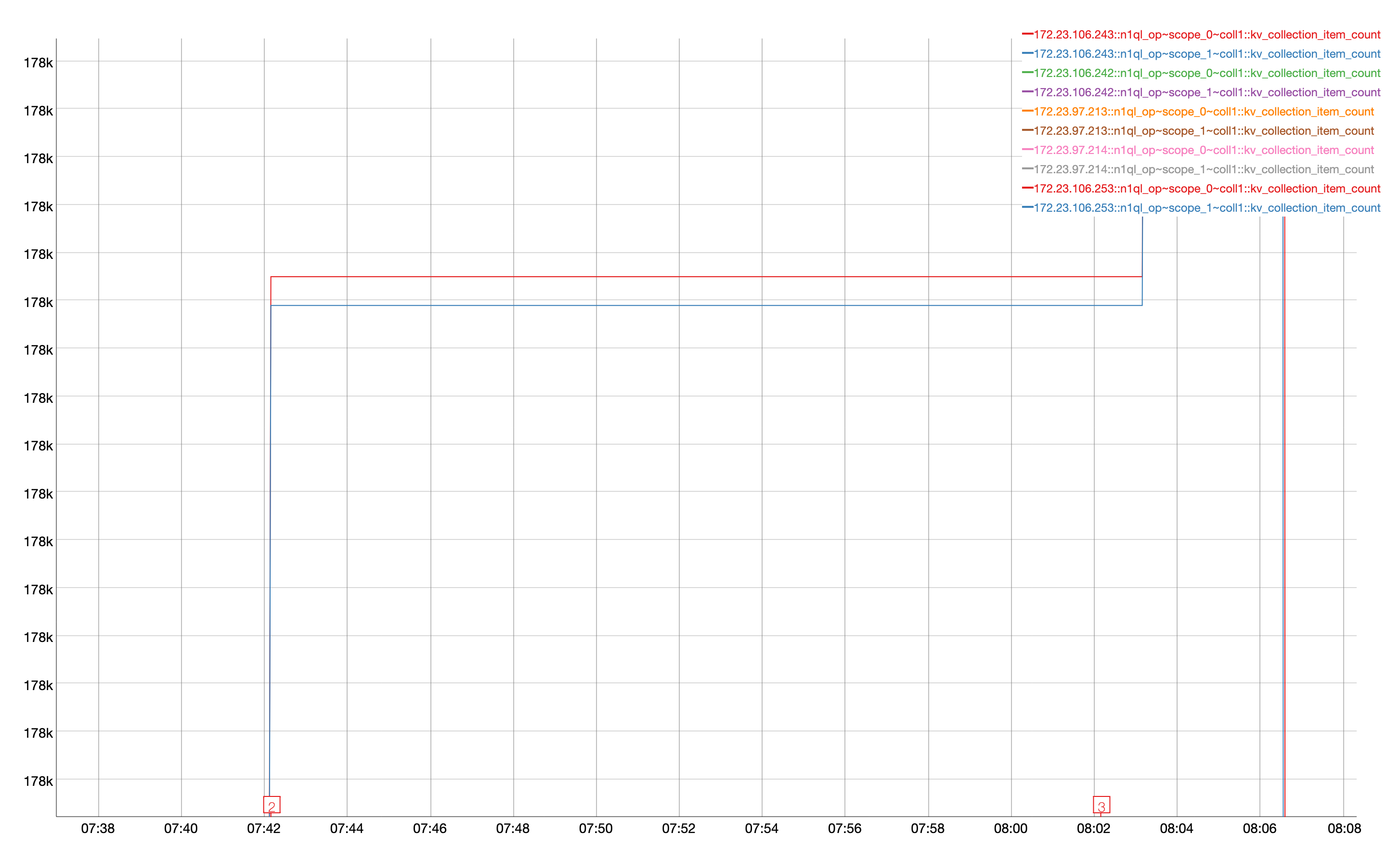
Source Bucket(n1ql_op.scope_0.coll0) : 6226696, Destination Bucket(['n1ql_op.scope_1.coll0']) : 6226691
|
Source Bucket(n1ql_op.scope_0.coll1) : 6226416, Destination Bucket(['n1ql_op.scope_1.coll1']) : 6226410
|
function OnUpdate(doc, meta) {
|
try{
|
var query = UPSERT INTO n1ql_op.scope_1.`coll0` ( KEY, VALUE ) VALUES ( $meta.id ,"n1ql insert");
|
}
|
catch(e){
|
log("Query failed: ",e)
|
}
|
}function OnDelete(meta, options) {
|
try{
|
var query = DELETE from n1ql_op.scope_1.`coll0` USE KEYS $meta.id ;
|
}
|
catch(e){
|
log("Query failed: ",e)
|
}
|
}
|
|
|
|
function OnUpdate(doc, meta) {
|
try{
|
var query = UPSERT INTO n1ql_op.scope_1.`coll1` ( KEY, VALUE ) VALUES ( $meta.id ,"n1ql insert");
|
}
|
catch(e){
|
log("Query failed: ",e)
|
}
|
}function OnDelete(meta, options) {
|
try{
|
var query = DELETE from n1ql_op.scope_1.`coll1` USE KEYS $meta.id ;
|
}
|
catch(e){
|
log("Query failed: ",e)
|
}
|
}
|
Attachments
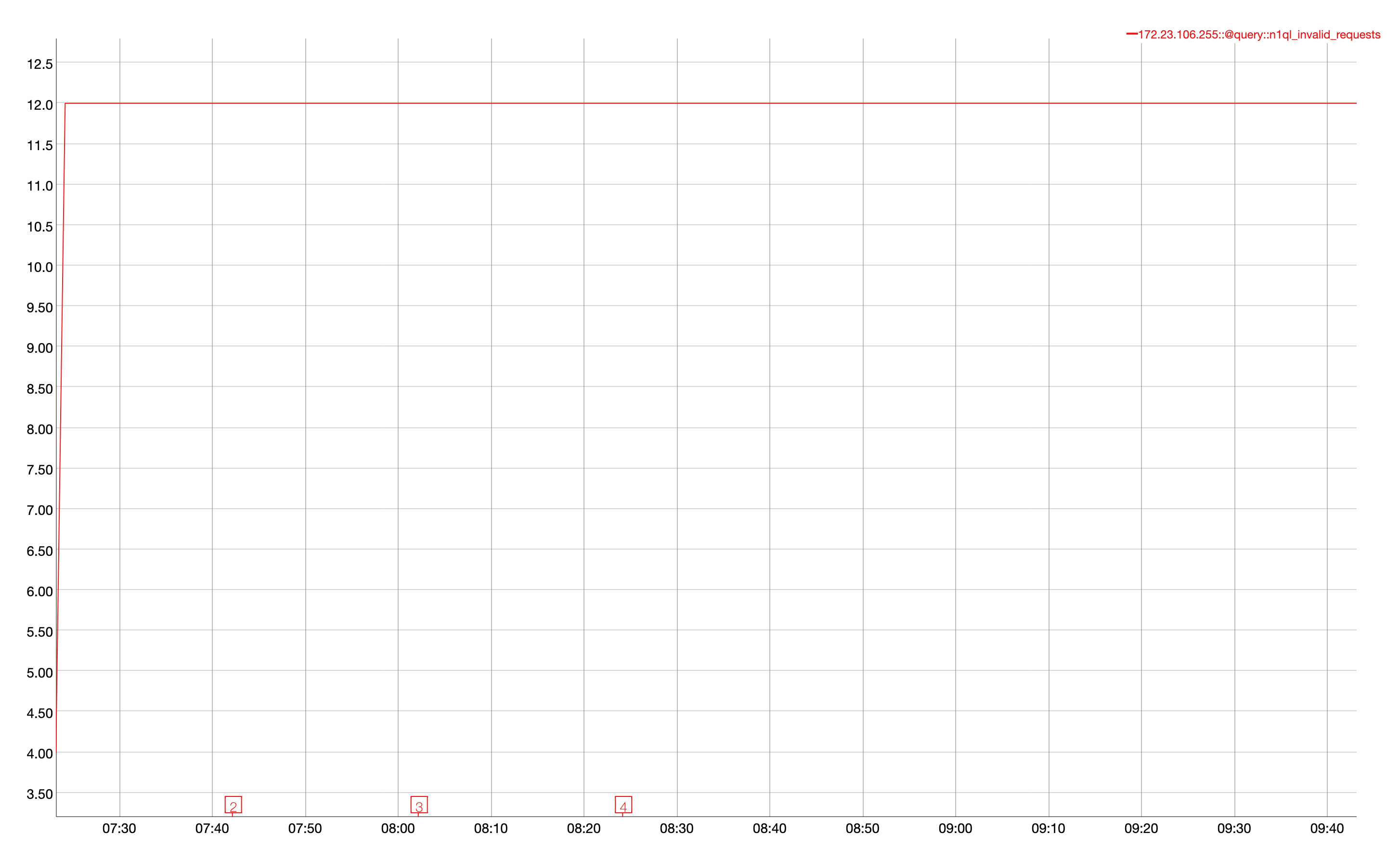
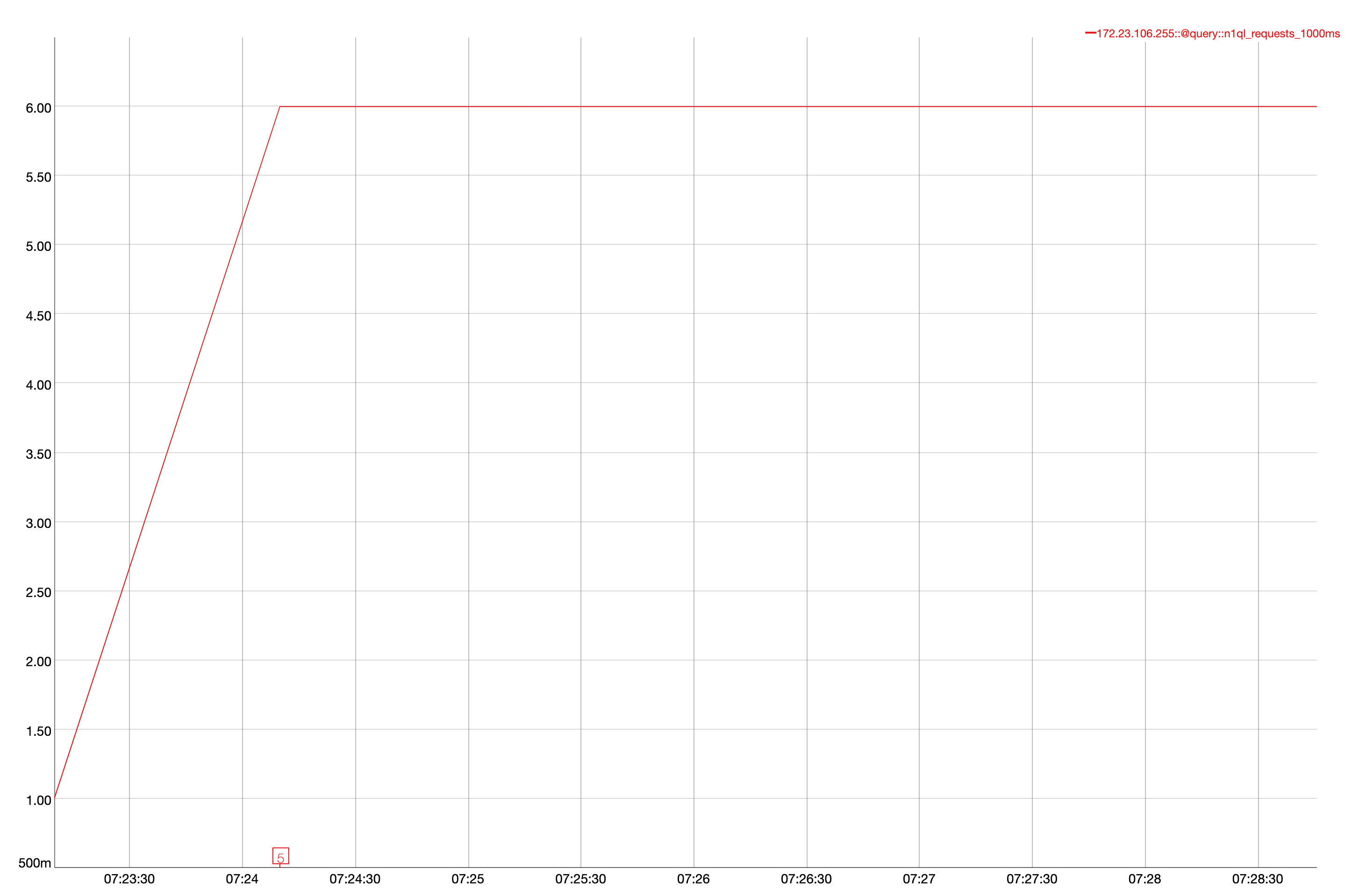
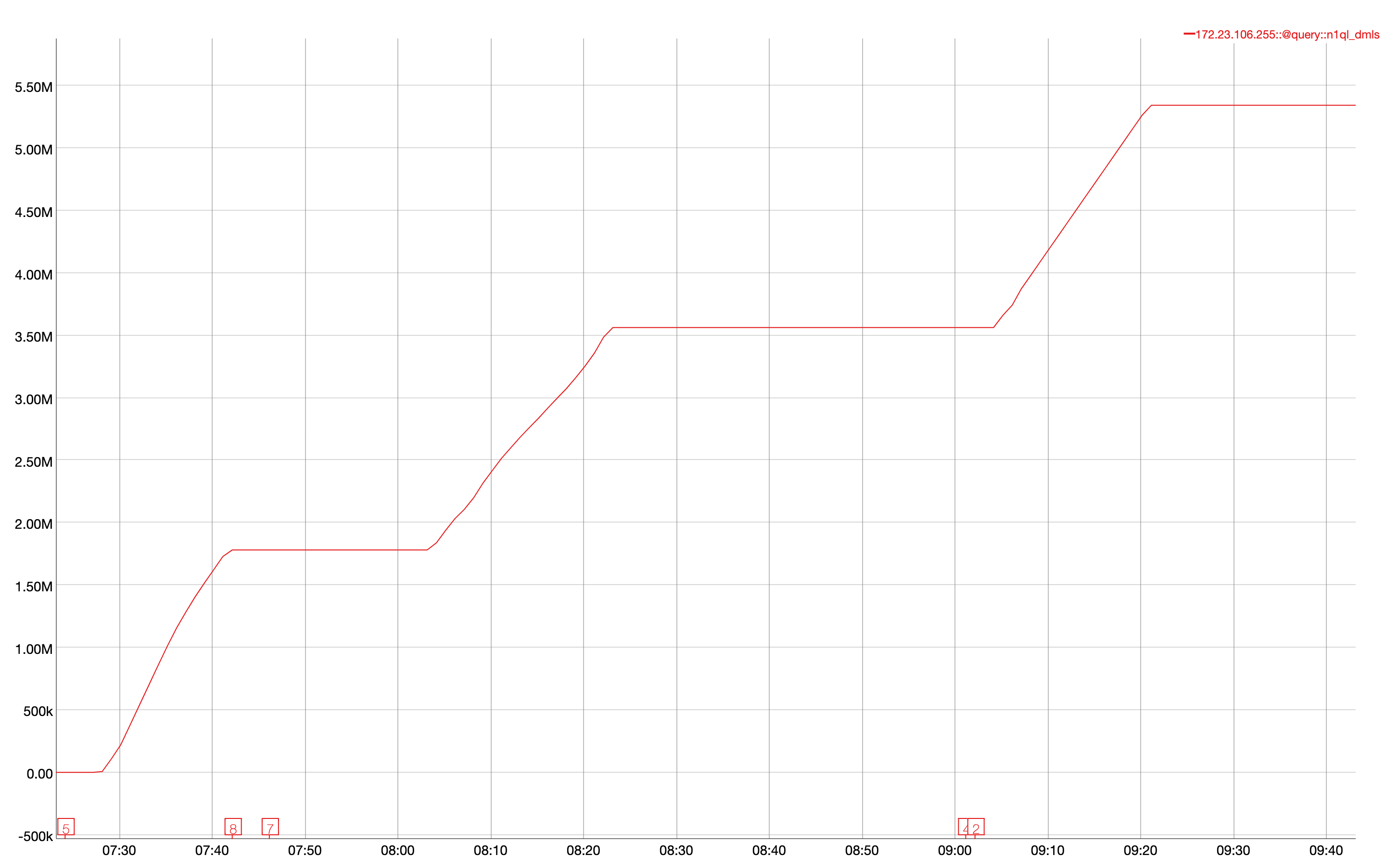
Issue Links
- backports to
-
-
- Closed
-
- depends on
-
CCBC-1411 Further disambiguate 12009 error returned by Query into retriable-transient-errors and non-retriable-specific-errors
-
- Resolved
-
- is duplicated by
-
-
- Closed
-