Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
7.0.0-5032
-
Untriaged
-
-
1
-
Unknown
Description
Steps:
- create a 1kv, 1 n1ql, 2 index nodes cluster
- start a expiry data load with ttl=1000
- ops is close to 50-80k
- rebalance in 1 index node. done is seconds as expected
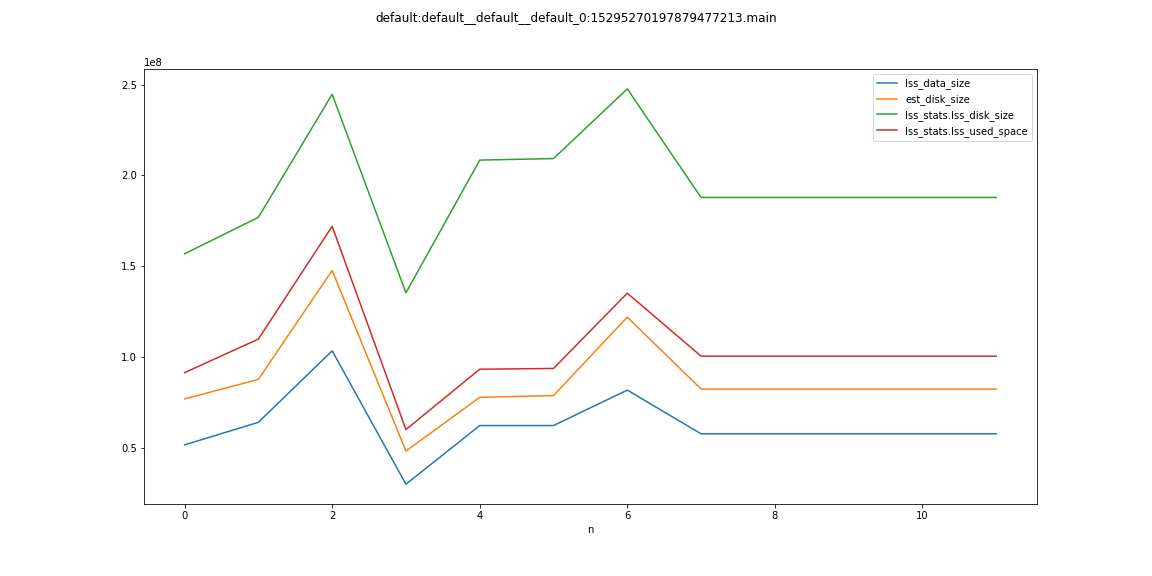
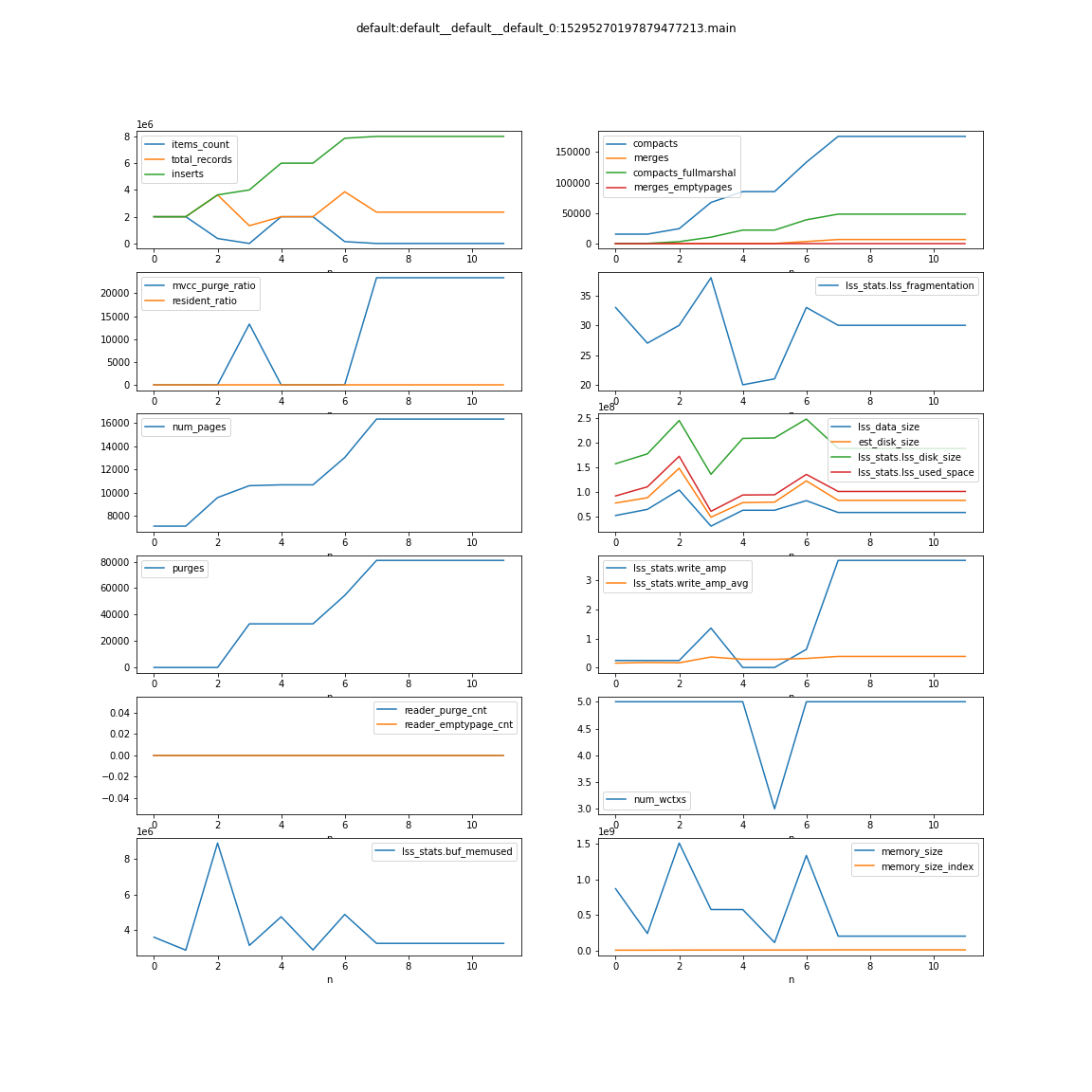
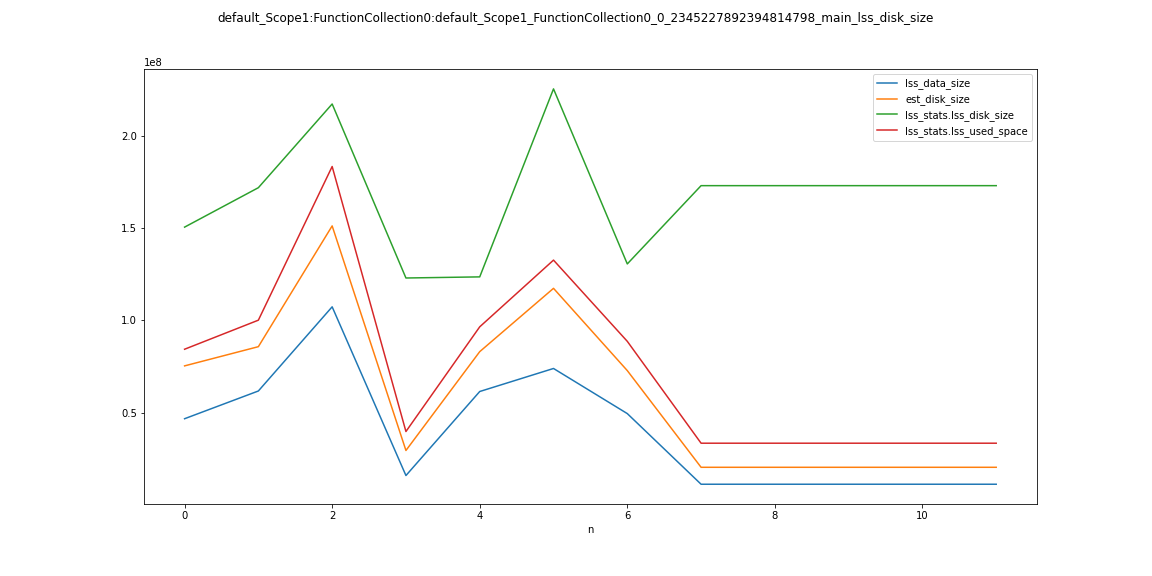
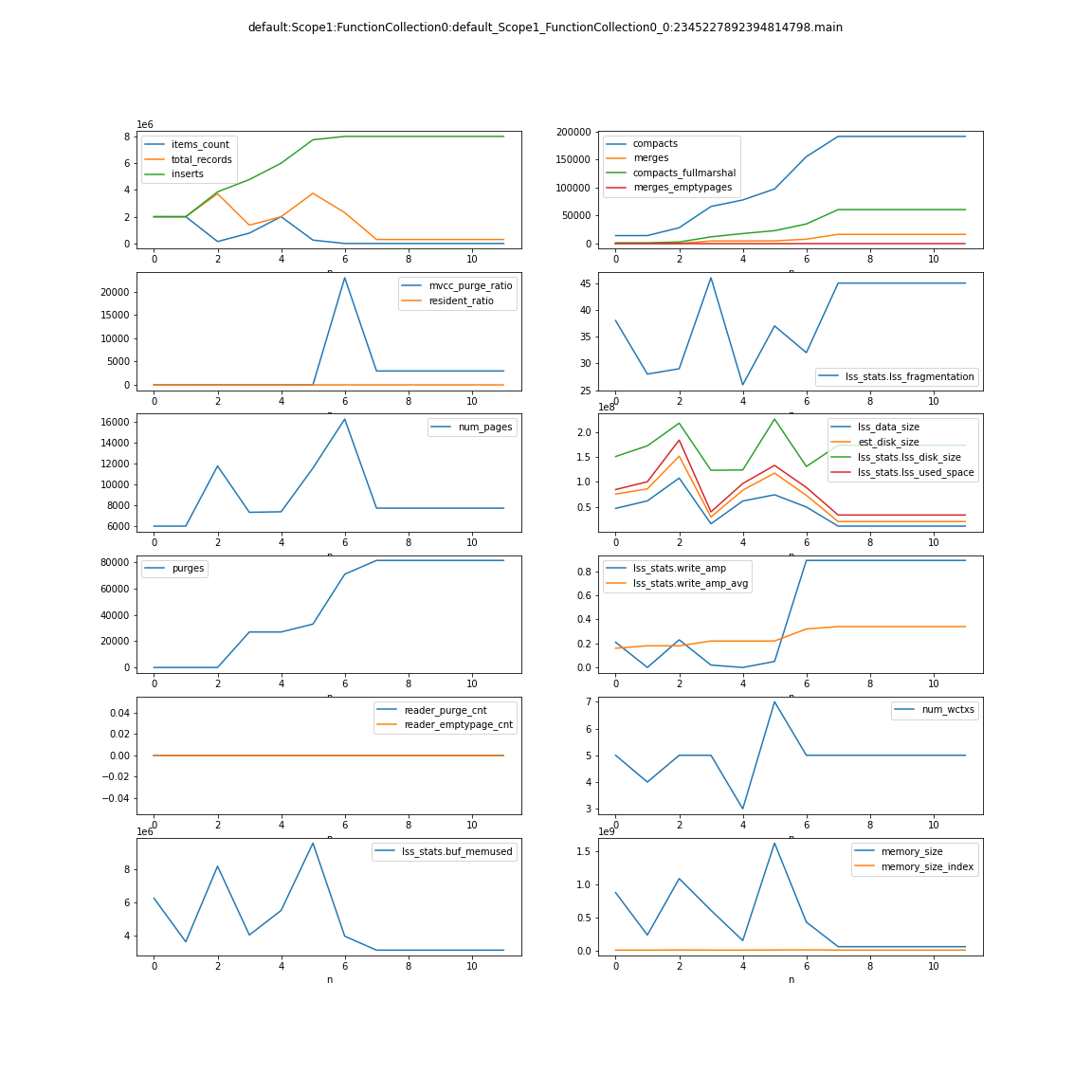
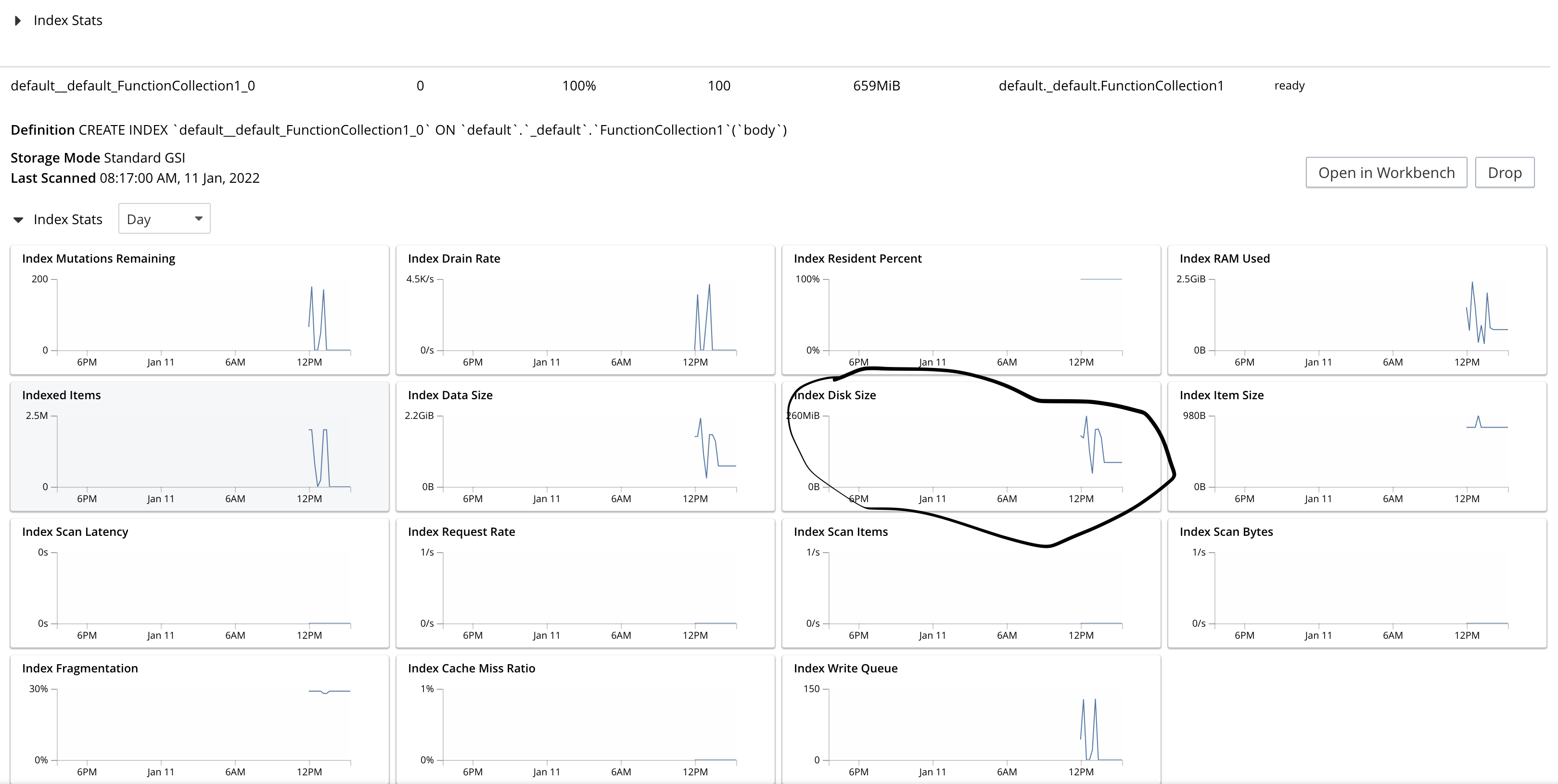
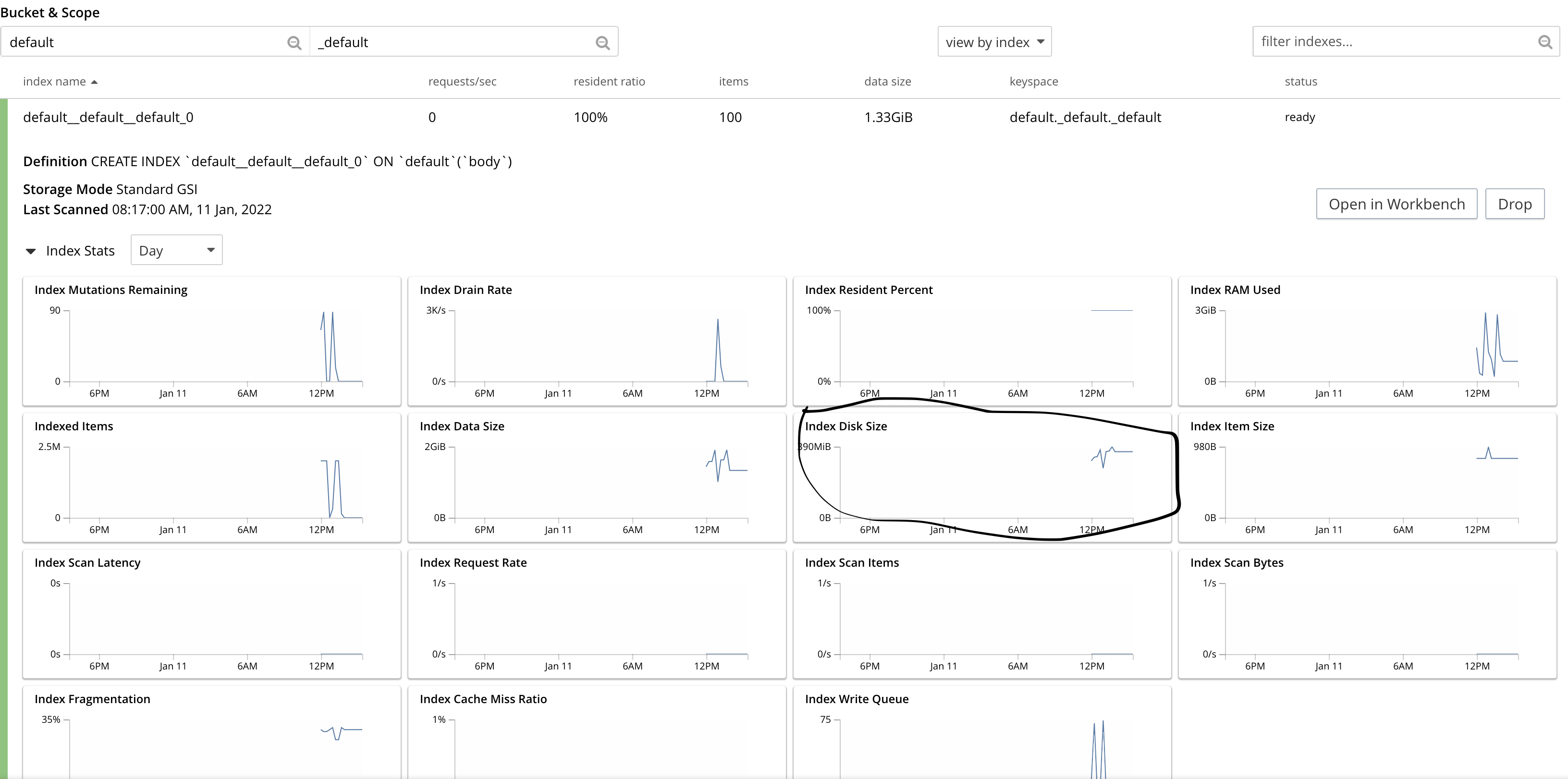
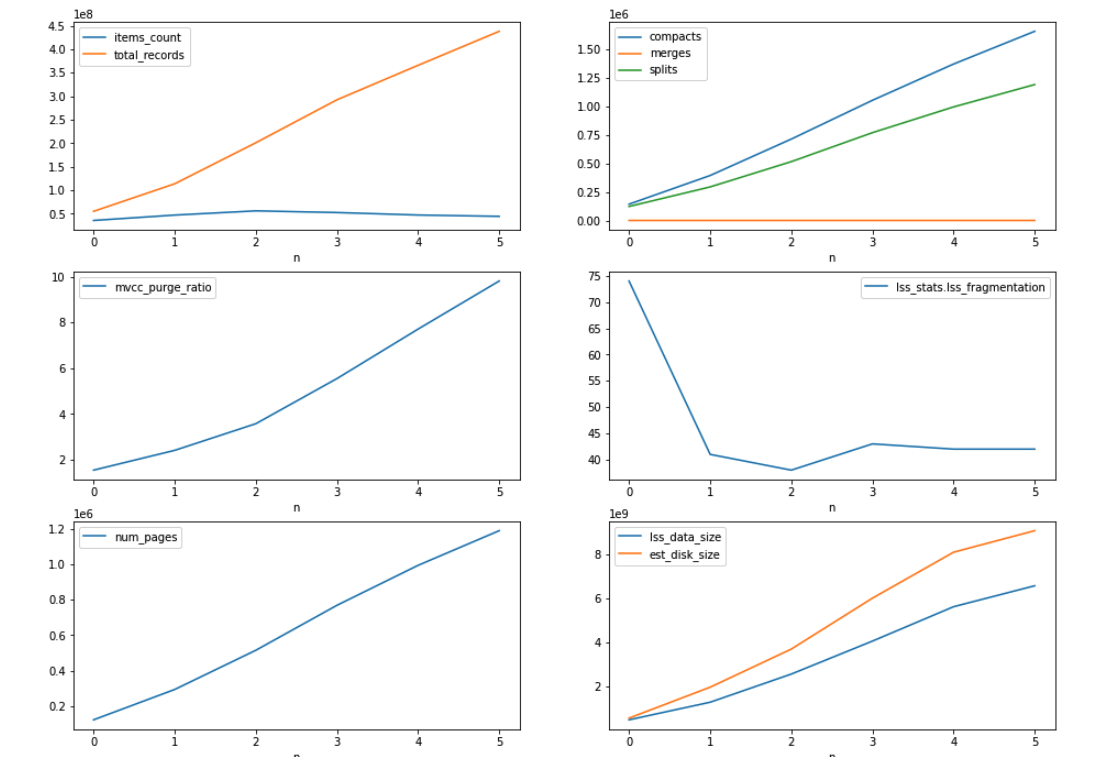
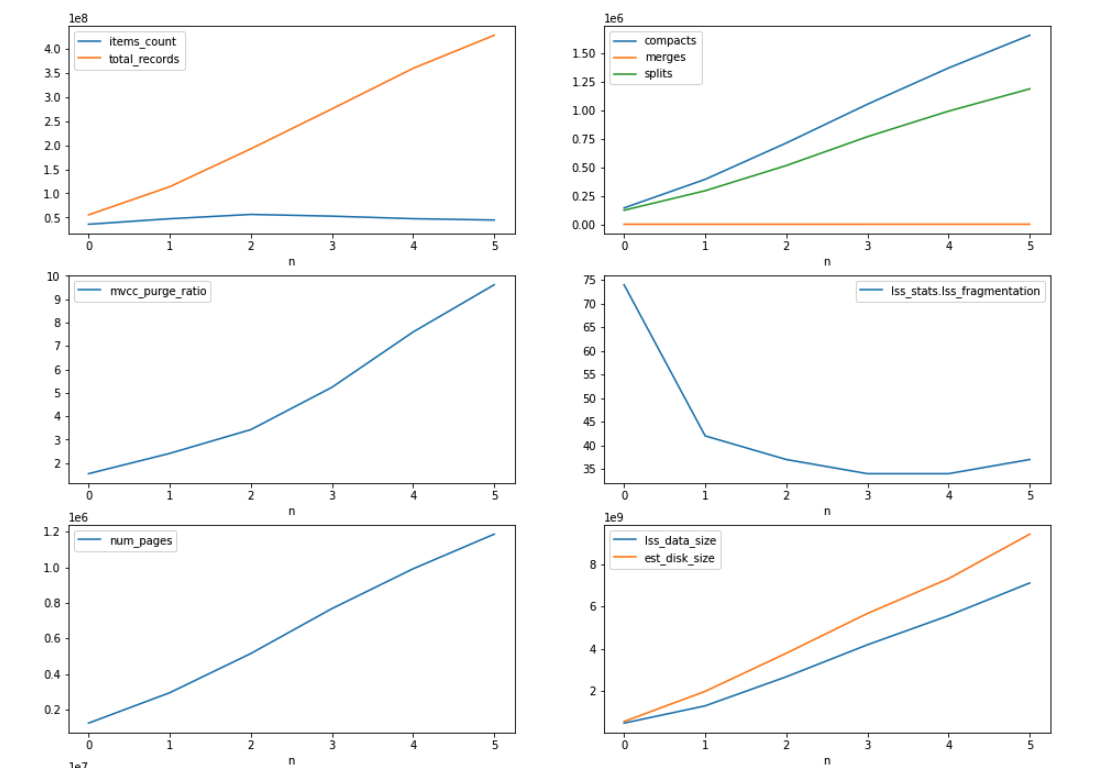
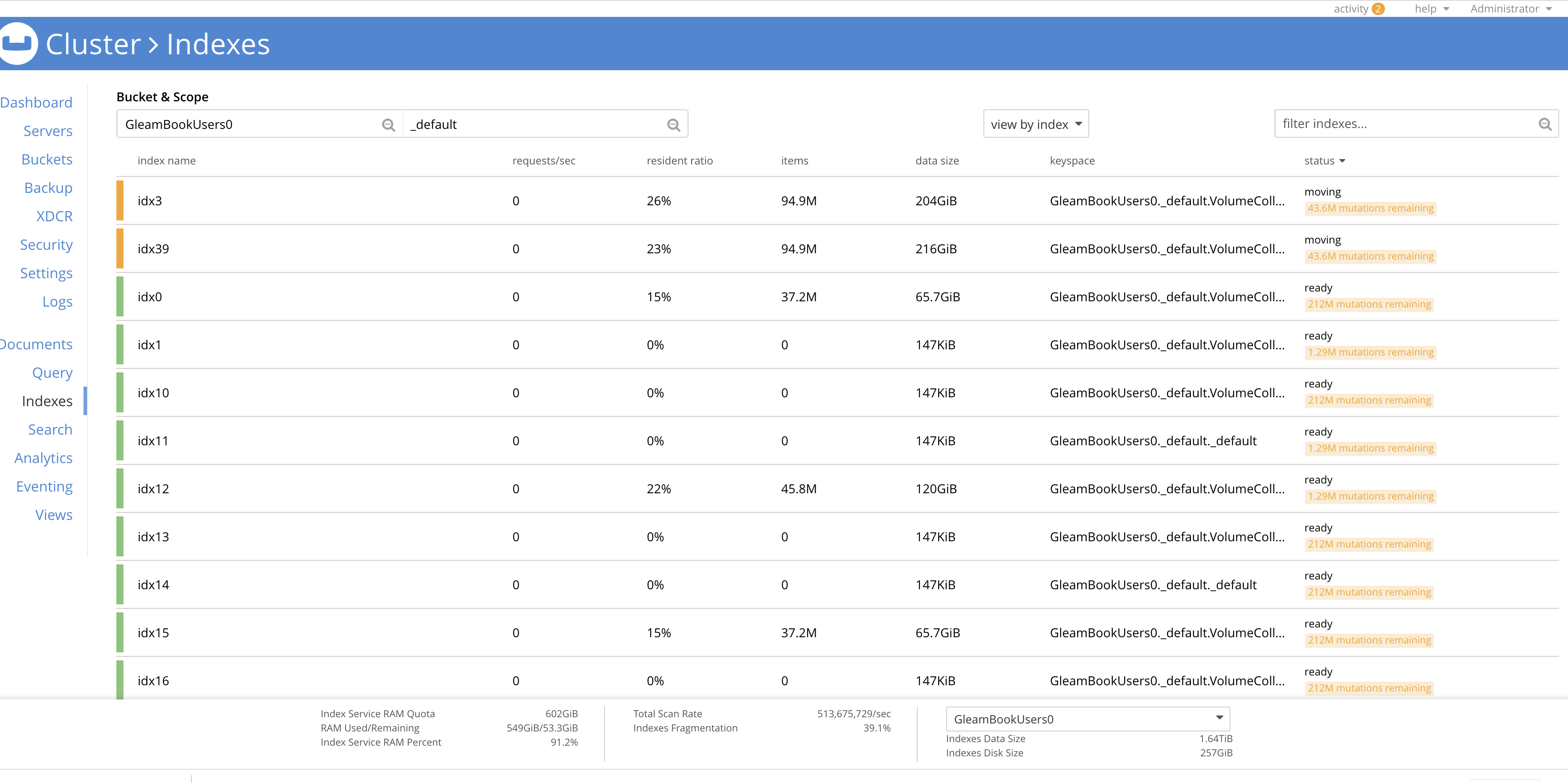
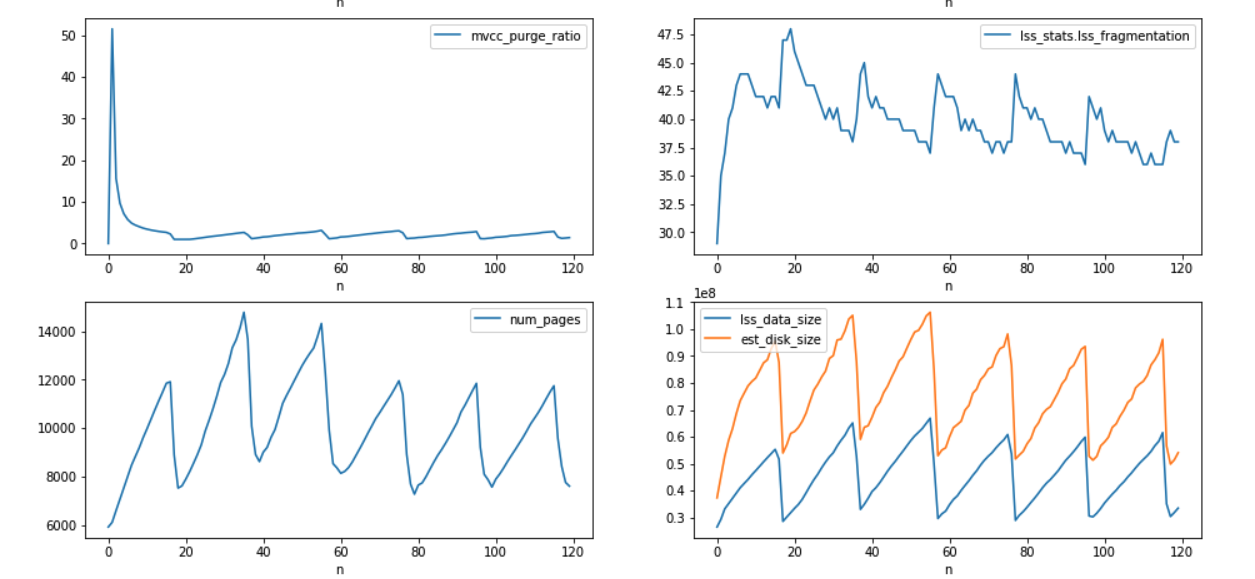
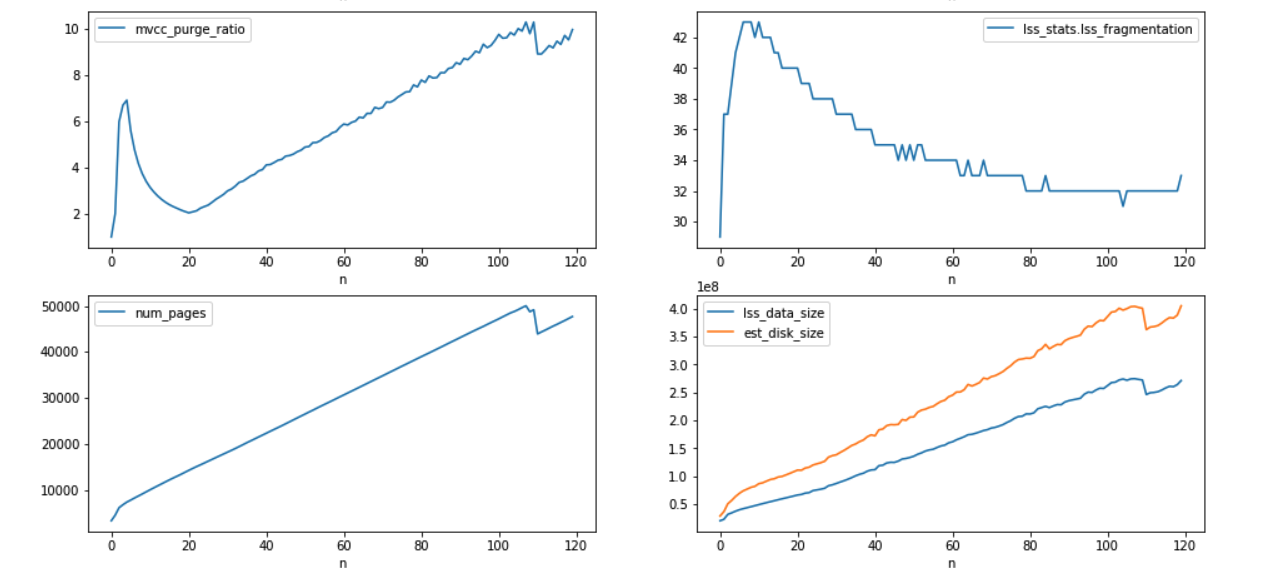
- rebalance out 1 indexer node. indexes moving to other nodes is continuously bloating up in terms of disk space and due to that rebalance is not able to finish and continuously running.
Bucket details:

Moving indexes details:
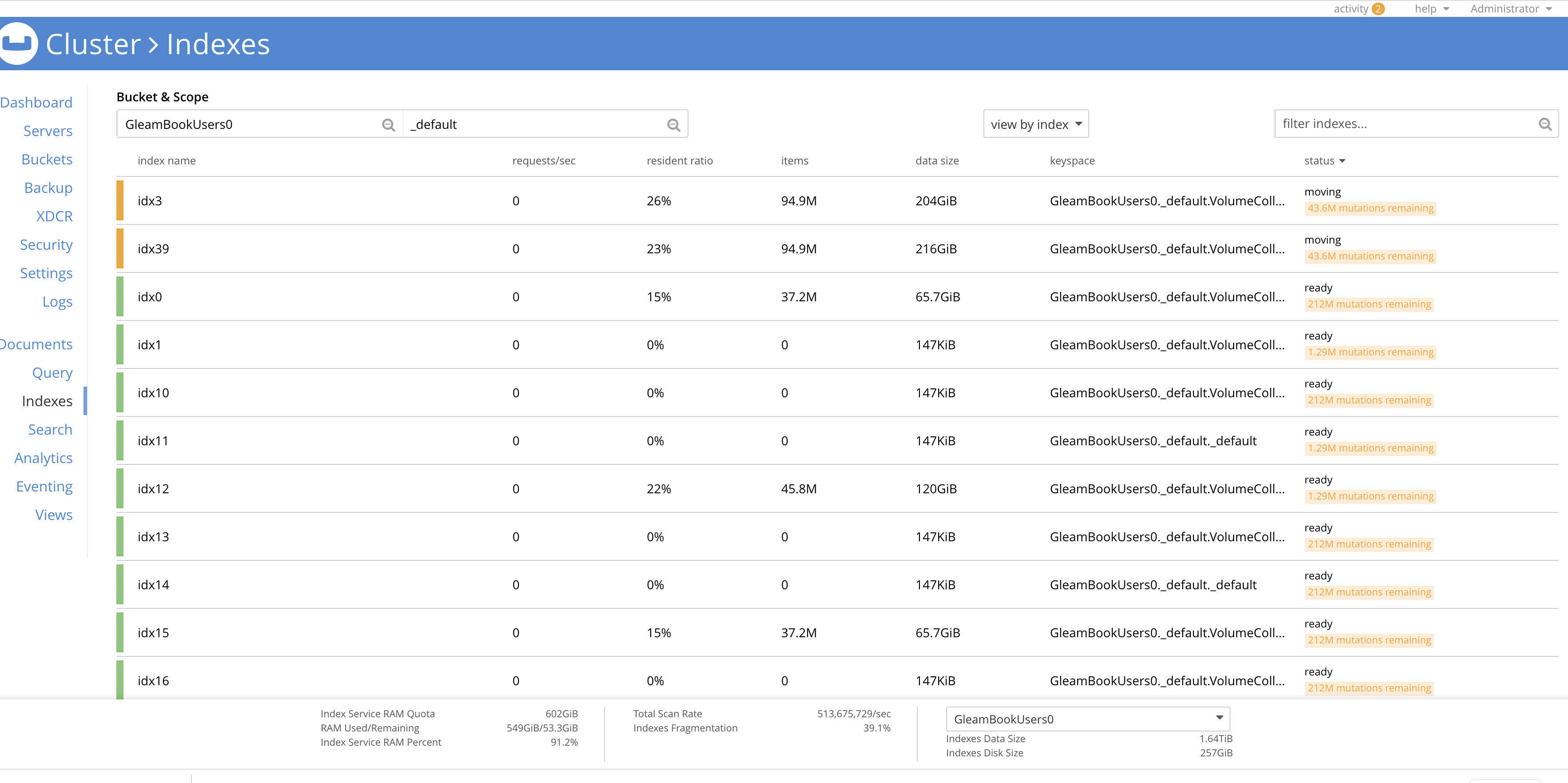
The indexes disk usage is ~200GB while bucket total disk usage is 30GB
|
QE test |
git fetch "http://review.couchbase.org/TAF" refs/changes/34/151634/58 && git checkout FETCH_HEAD
|
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/magma_temp_job3.ini -p bucket_storage=couchstore,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.Hospital.Murphy.test_rebalance,nodes_init=1,graceful=True,skip_cleanup=True,num_items=500000000,num_buckets=1,bucket_names=GleamBook,doc_size=256,bucket_type=membase,eviction_policy=fullEviction,iterations=100,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=18,randomize_doc_size=False,randomize_value=True,assert_crashes_on_load=True,num_collections=2,maxttl=1000,num_indexes=50,pc=1,sdk_client_pool=True,max_clients=10,index_nodes=2,query_nodes=1,cbas_nodes=0,fts_nodes=0 -m rest'
|