Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
Enterprise Edition 7.0.0 build 5095
-
Untriaged
-
Centos 64-bit
-
-
1
-
Unknown
Description
Build: 7.0.0-5095
Scenario:
- Cluster with index,eventing,fts,backup services actively running
- 3 FTS indexes created (2 with indexPartition=1 and 1 index with indexPartition=6)
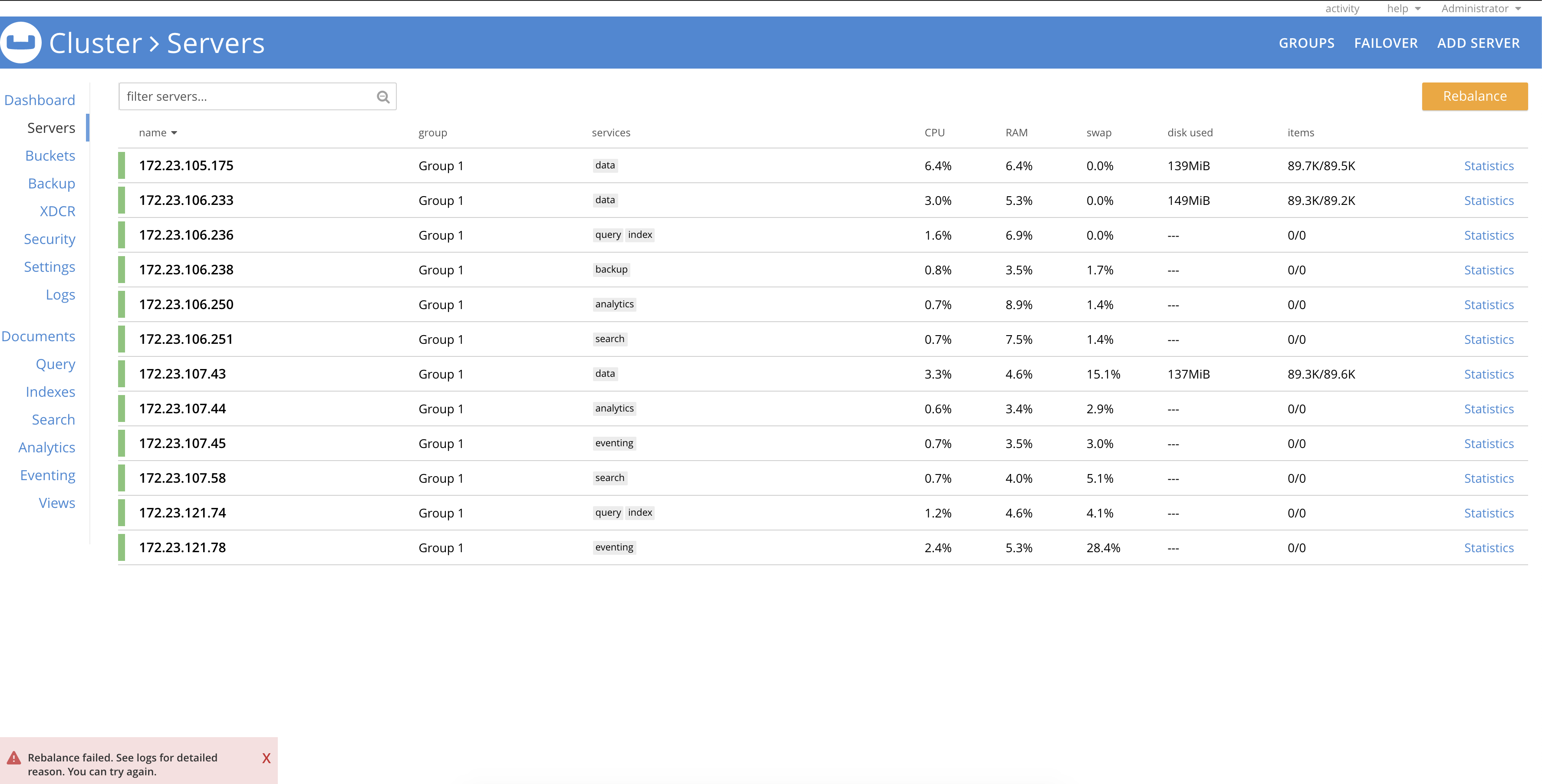
- Rebalance in extra FTS node into the cluster along with few other nodes with other services
Observation:
Fts rebalance failed with reason fts worker died,
Rebalance exited with reason {service_rebalance_failed,fts,
|
{worker_died,
|
{'EXIT',<0.12316.37>,
|
{rebalance_failed,inactivity_timeout}}}}.
|
Rebalance Operation Id = b5ce1e972169e0377441008a937cb498
|
..
|
..
|
Starting rebalance, KeepNodes = ['ns_1@172.23.105.175','ns_1@172.23.106.233',
|
'ns_1@172.23.106.236','ns_1@172.23.106.238',
|
'ns_1@172.23.106.250','ns_1@172.23.106.251',
|
'ns_1@172.23.107.43','ns_1@172.23.107.44',
|
'ns_1@172.23.107.45','ns_1@172.23.107.58',
|
'ns_1@172.23.121.74','ns_1@172.23.121.78'], EjectNodes = [], Failed over and being ejected nodes = []; no delta recovery nodes; Operation Id = b5ce1e972169e0377441008a937cb49
|
Snapshot: https://supportal.couchbase.com/snapshot/ff8cc1ad0a5b1fdc2c01fdd52cec4165::0