Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.0.0
-
Untriaged
-
-
1
-
No
Description
Environment: 7.0.0-5295
Test : 30 bucket test with all the components
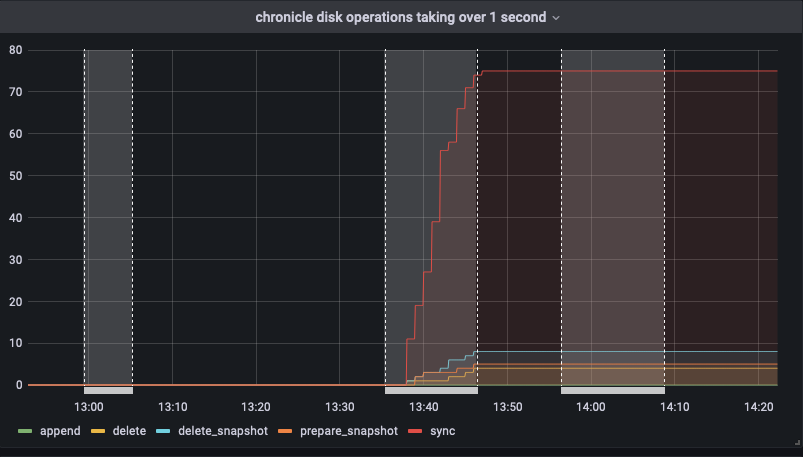
Failed at : Rebalance step
Error message:
completionMessage":"Rebalance exited with reason
Unknown macro:
Unknown macro: {buckets_cleanup_failed,['ns_1@172.23.96.20']}
."}
Link to the job : http://perf.jenkins.couchbase.com/view/Eventing/job/themis_multibucket/102/
Steps of the test :
- Load the buckets with documents
- Create n1ql indexes
- Initialise XDCR (init_only_xdcr() )
- Creating the eventing functions
- Creating FTS indexes
- Creating Analytics dataset
- Running rebalance for each phase as follows :
- KV rebalance
- Rebalance in with mutations
- Rebalance swap
- Rebalance out
- Index rebalance
- Rebalance in
- Rebalance swap
- Rebalance Out
- Eventing rebalance
- Rebalance in
- Rebalance swap
- Rebalance Out
- CBAS rebalance
- Rebalance in
- Rebalance swap
- Rebalance Out
- KV rebalance
- Backup
- FTS swap rebalance
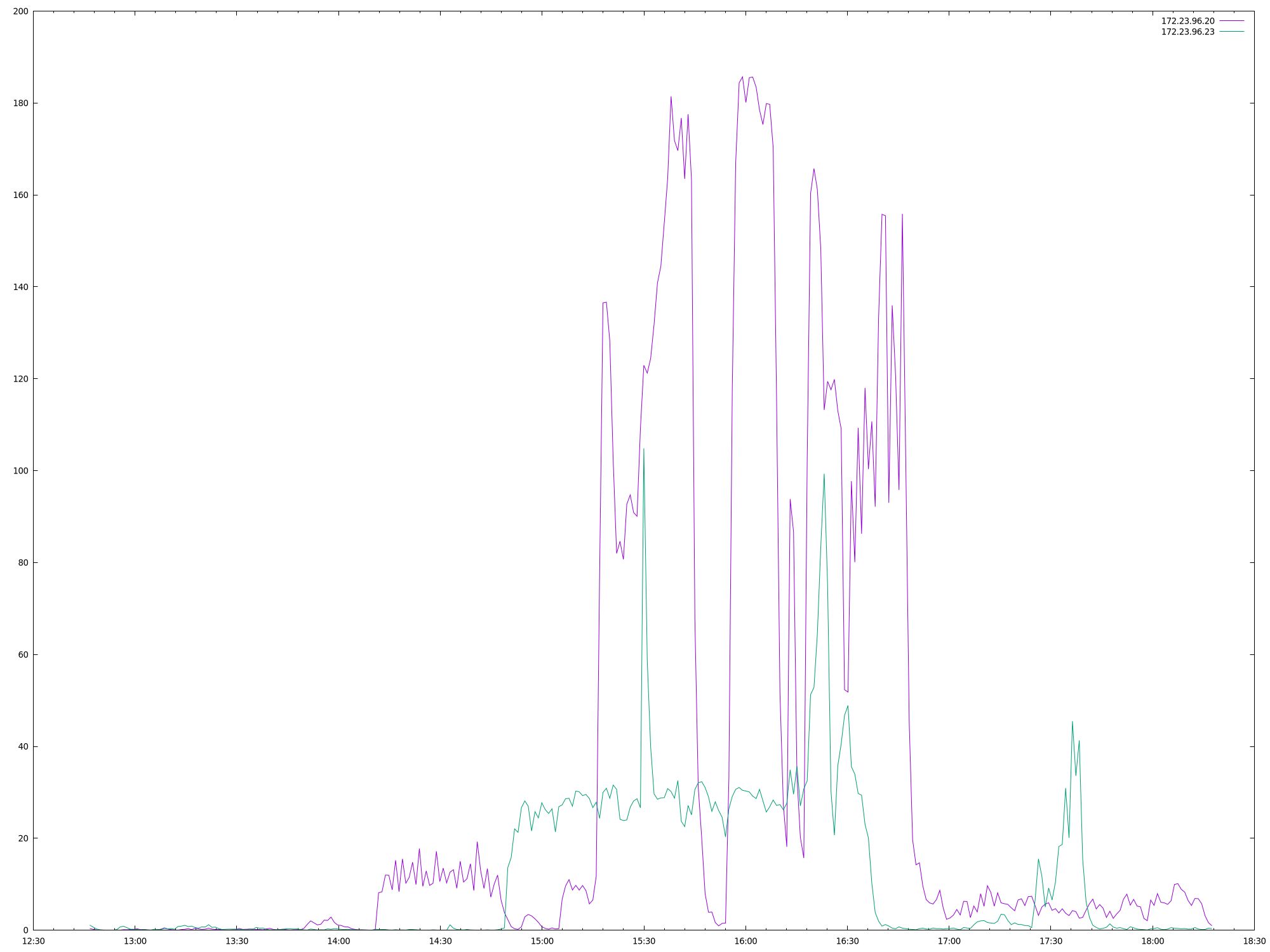
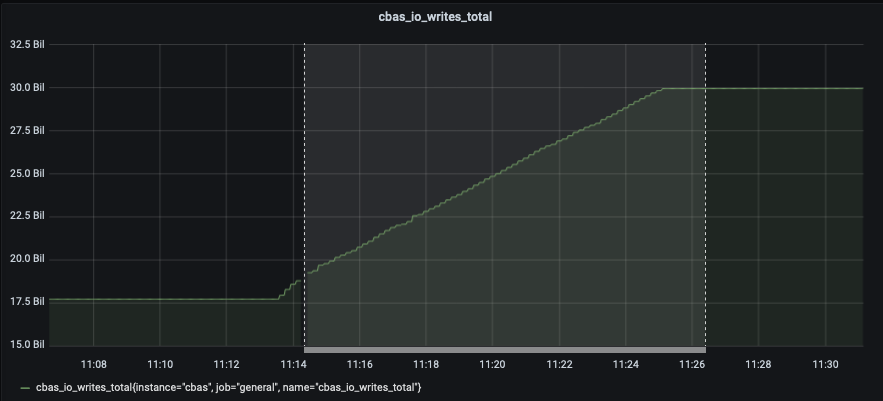
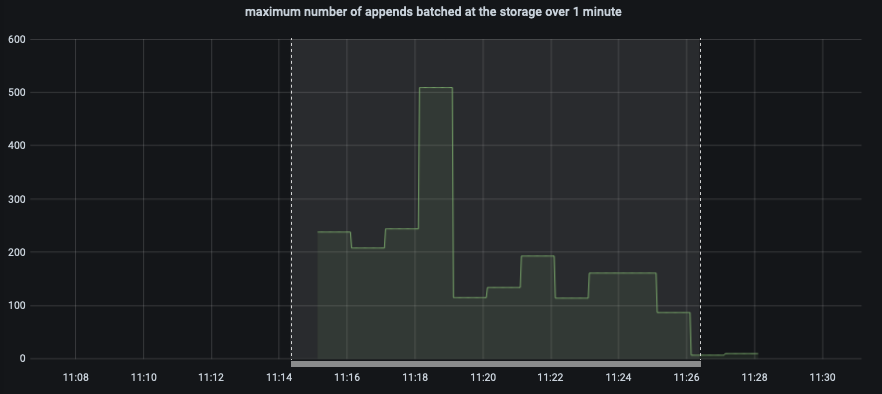
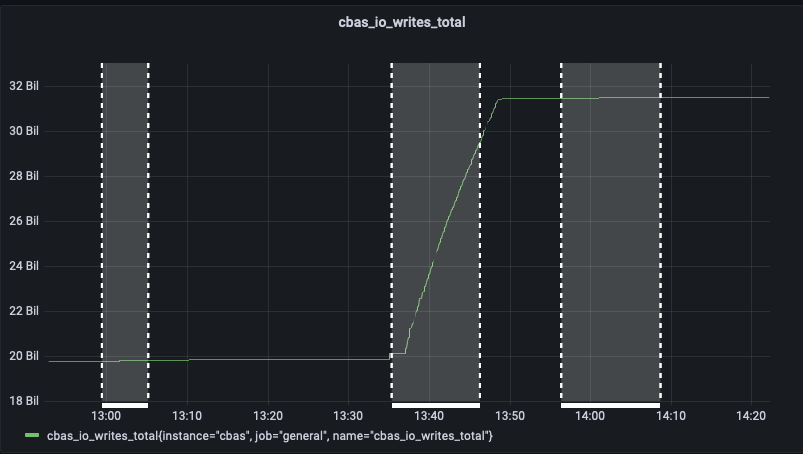
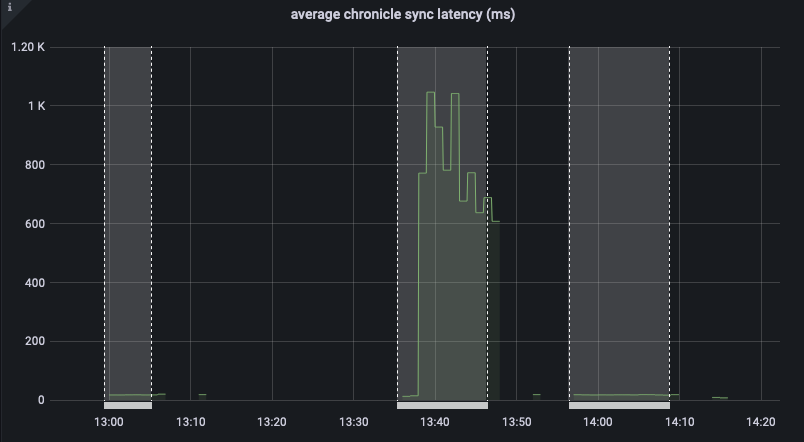
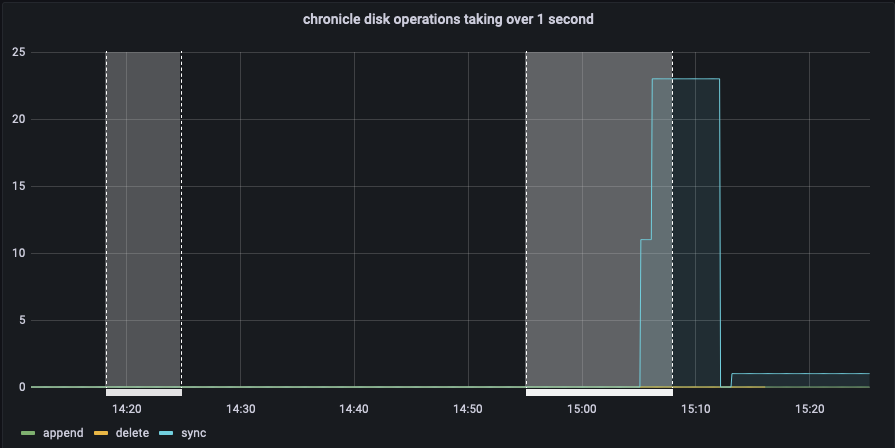
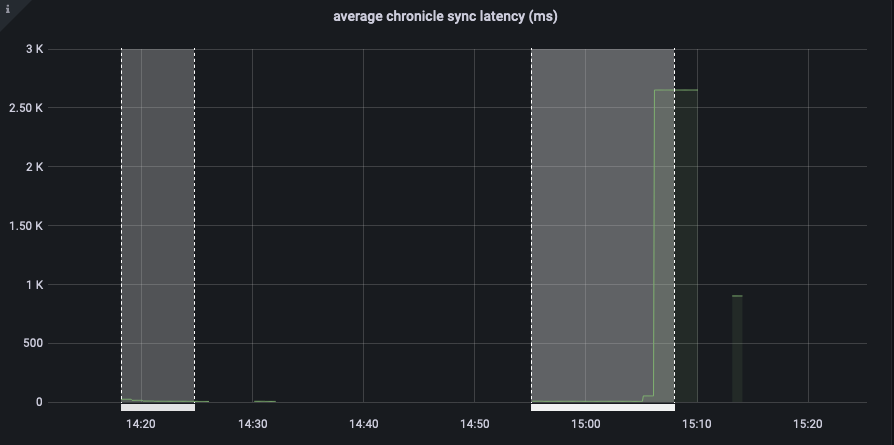
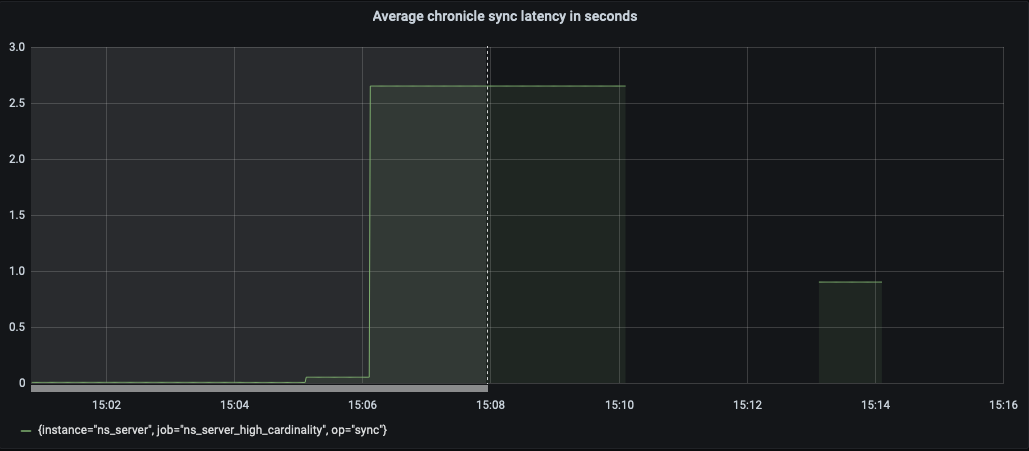
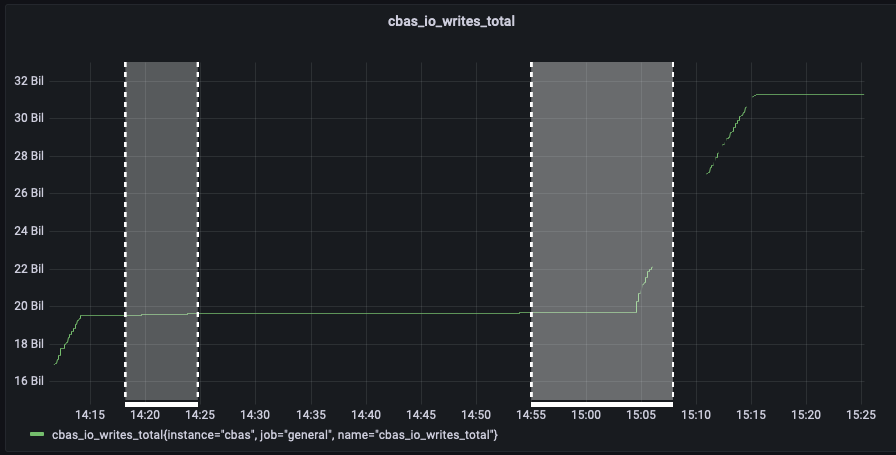
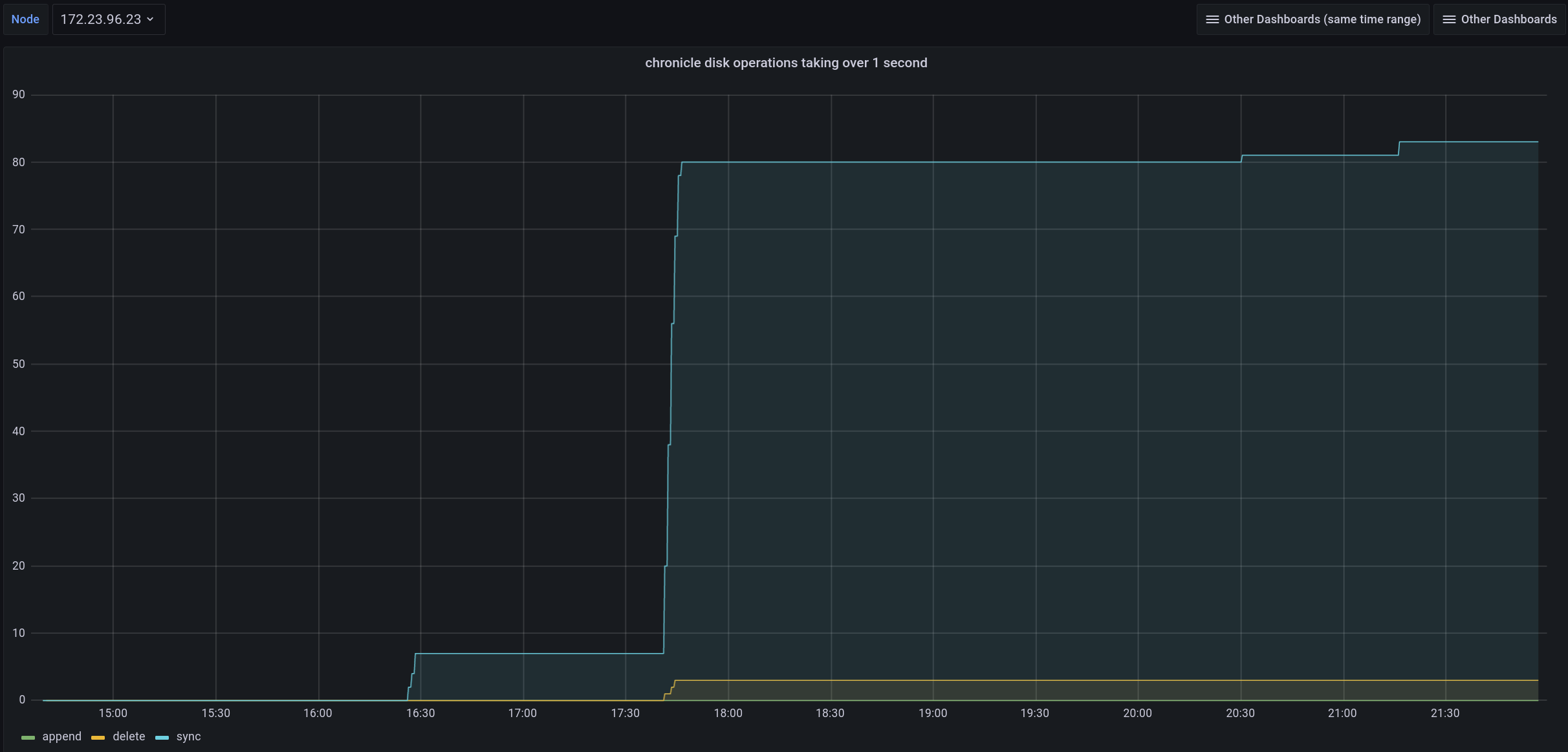
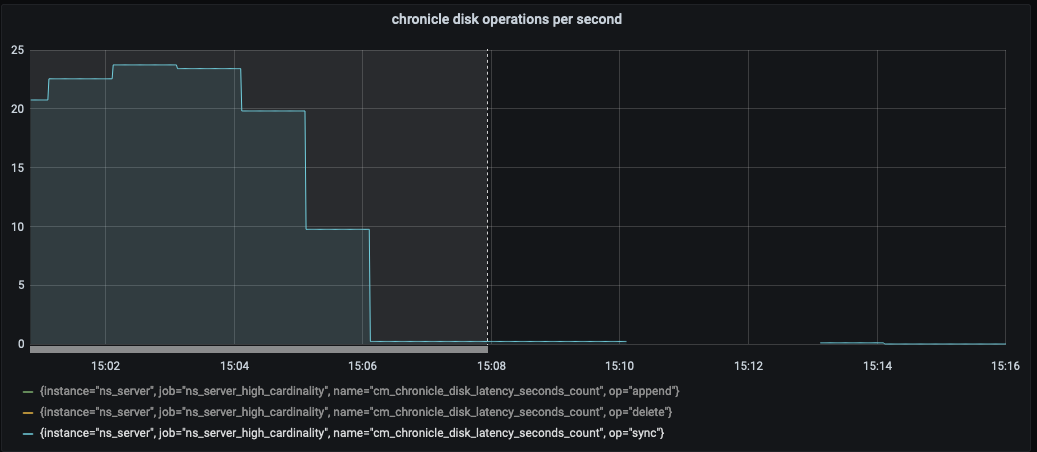
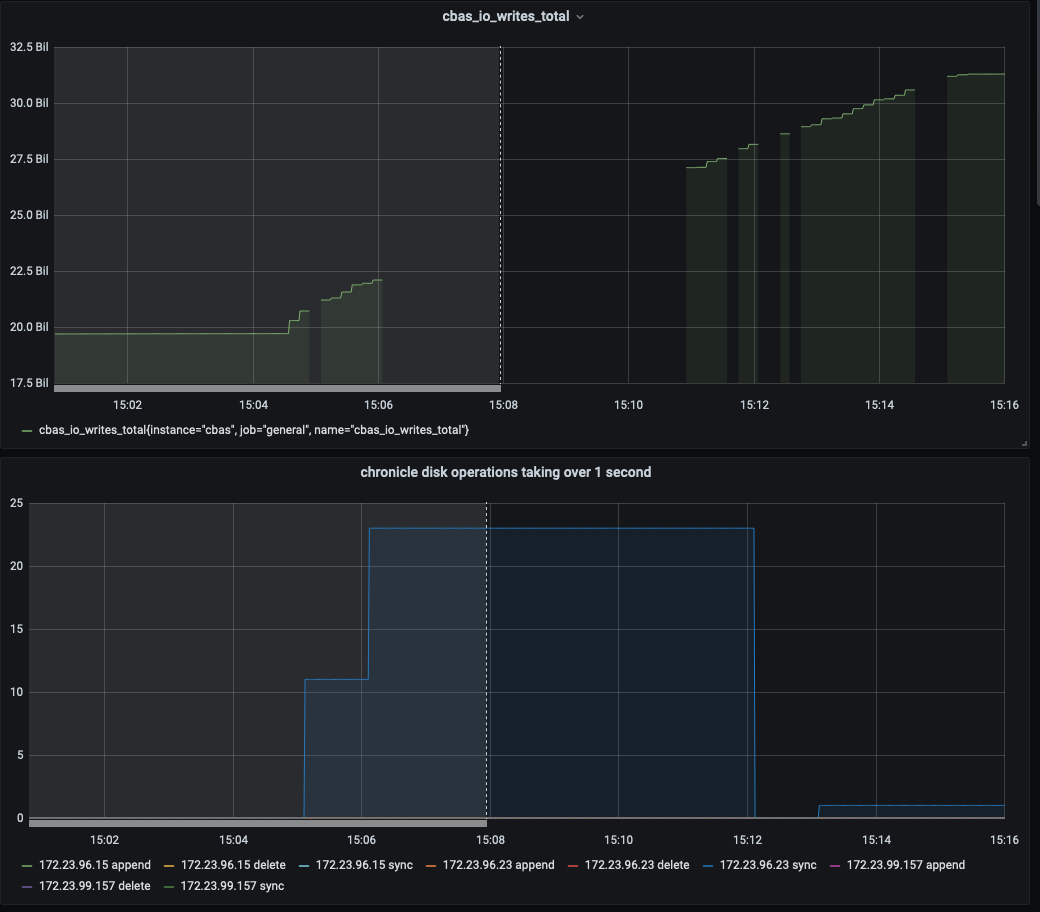
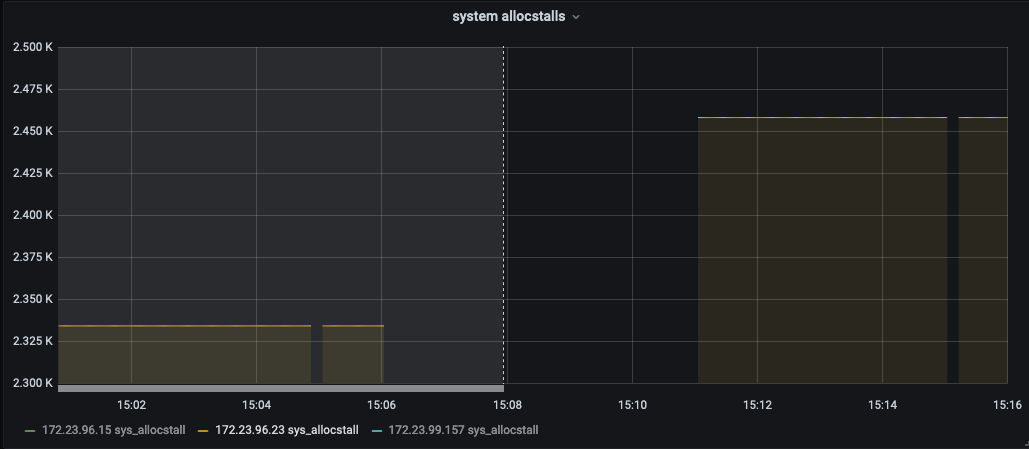
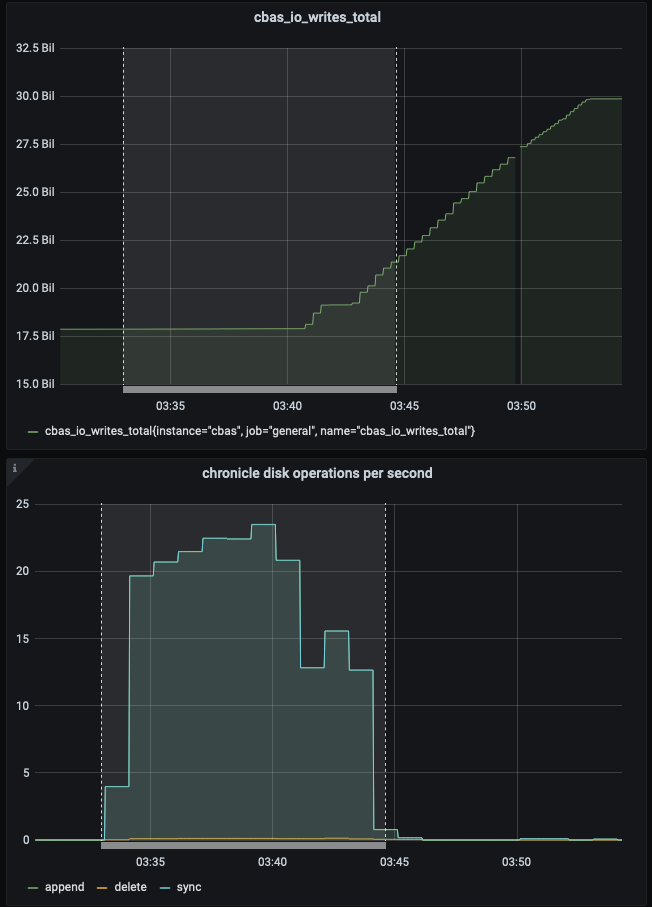
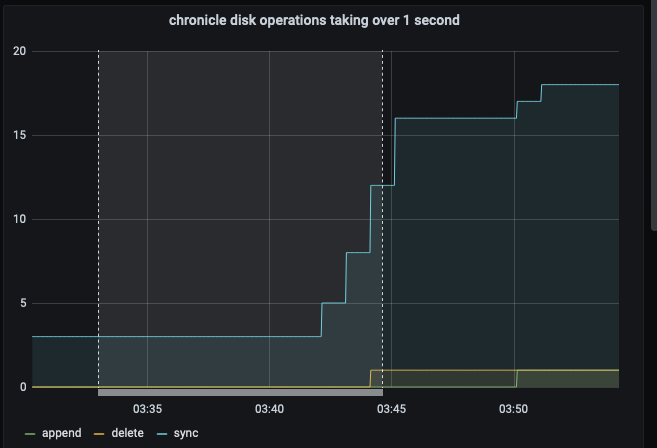
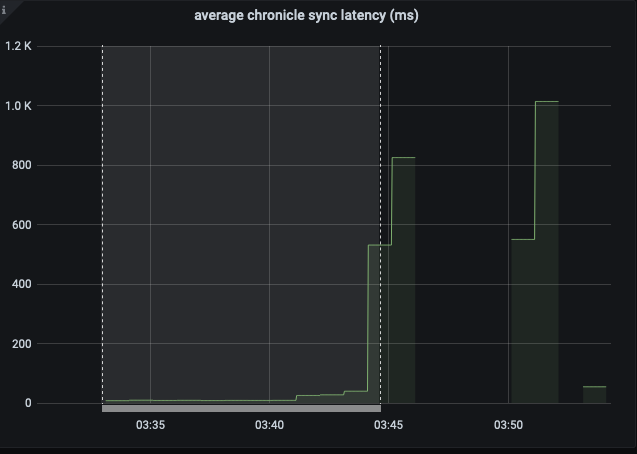
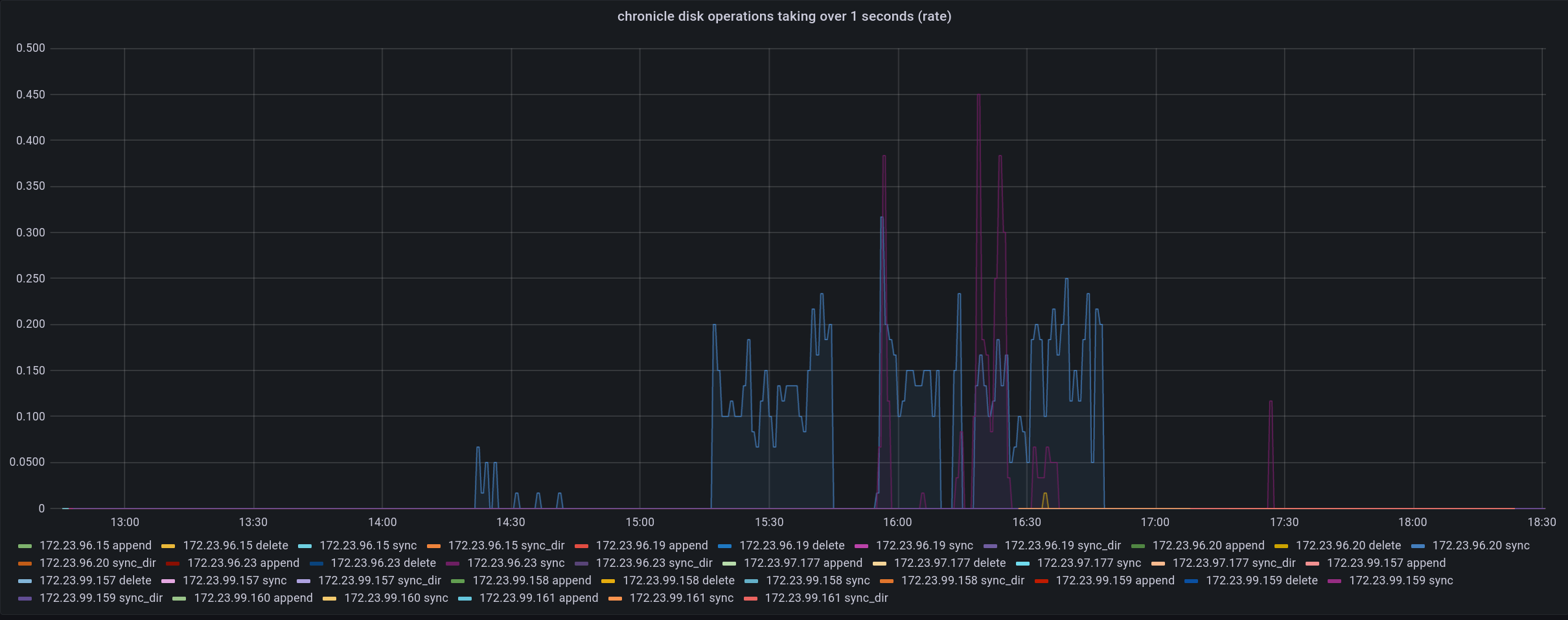
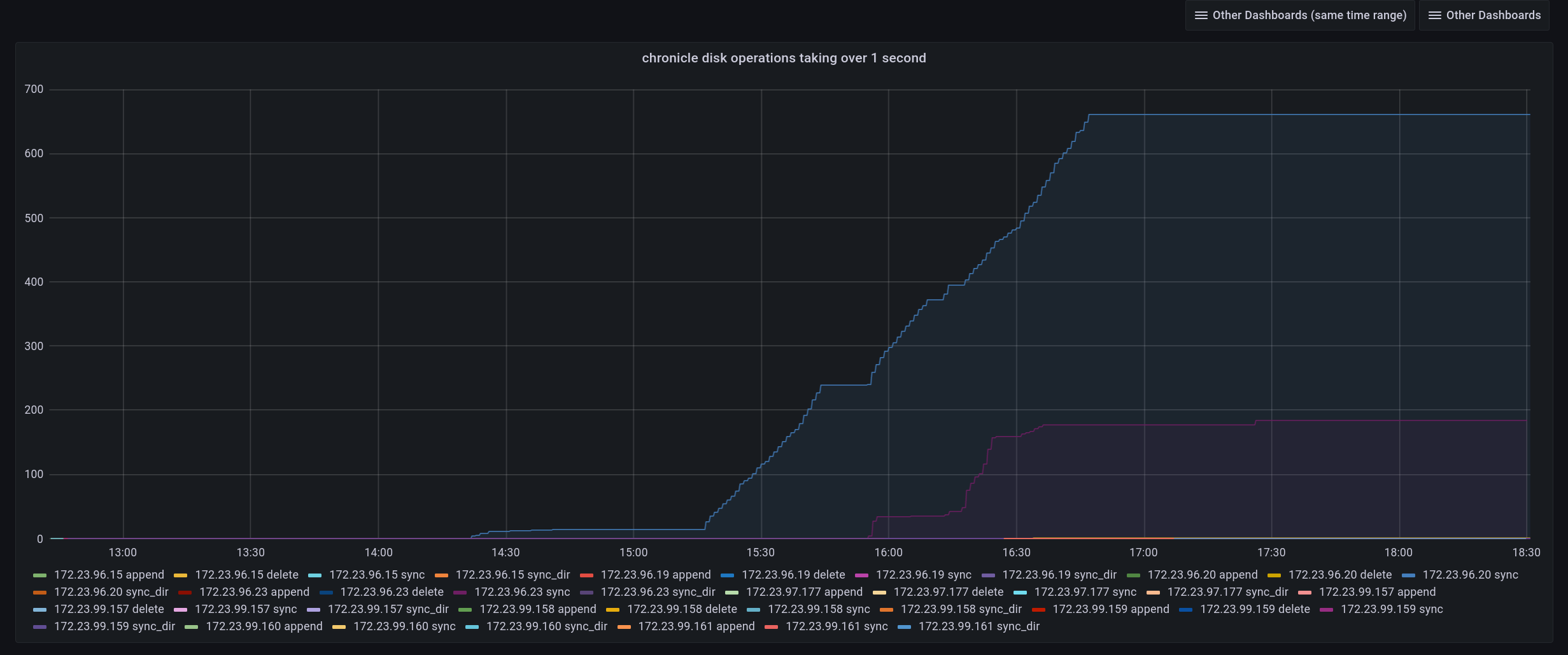
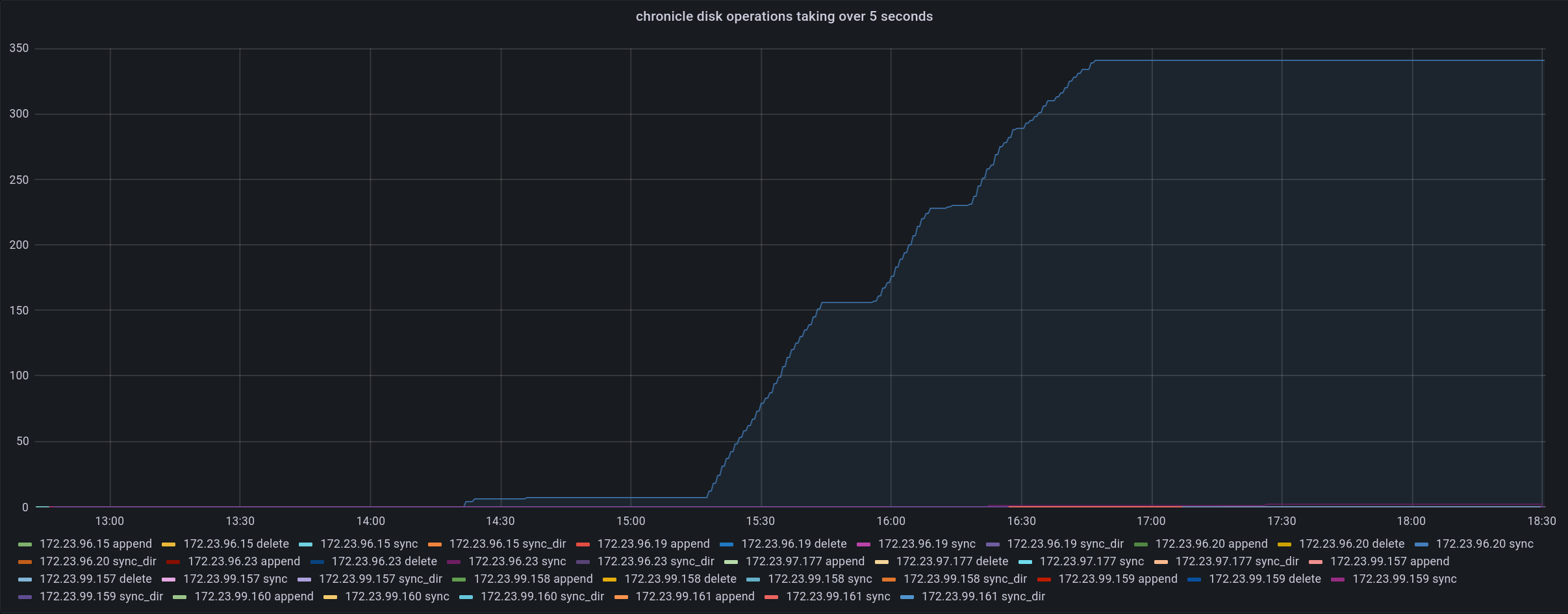
The test failed when Eventing Swap rebalance was being executed. (Marked in red)
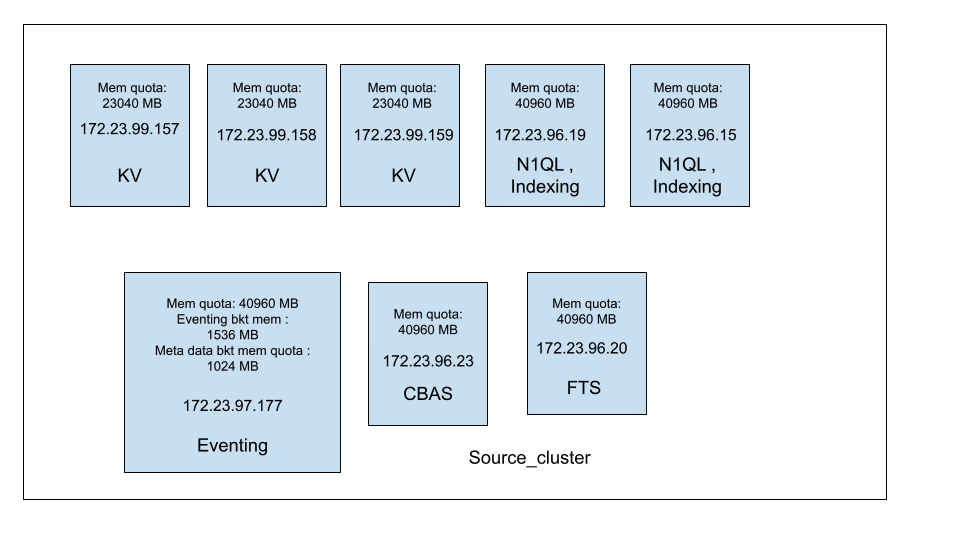
Cluster setup and the cluster details are mentioned in the screenshot attached below.