Details
-
Improvement
-
Resolution: Unresolved
-
 Major
Major
-
6.6.3, 7.0.0
Description
As seen in CBSE-10704
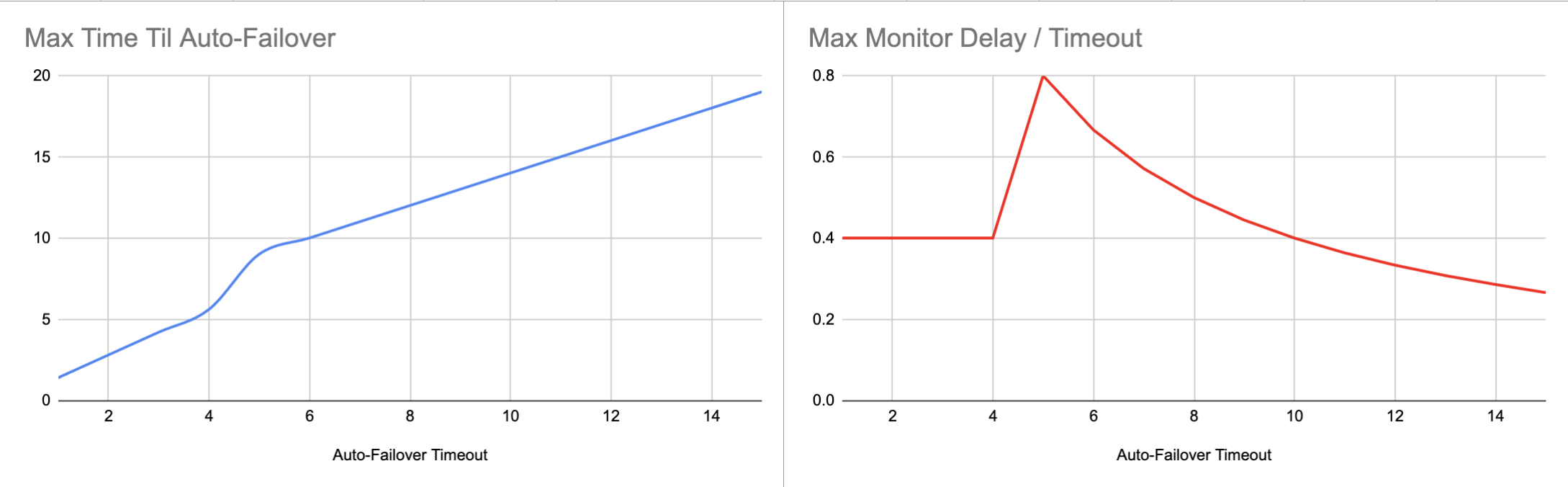
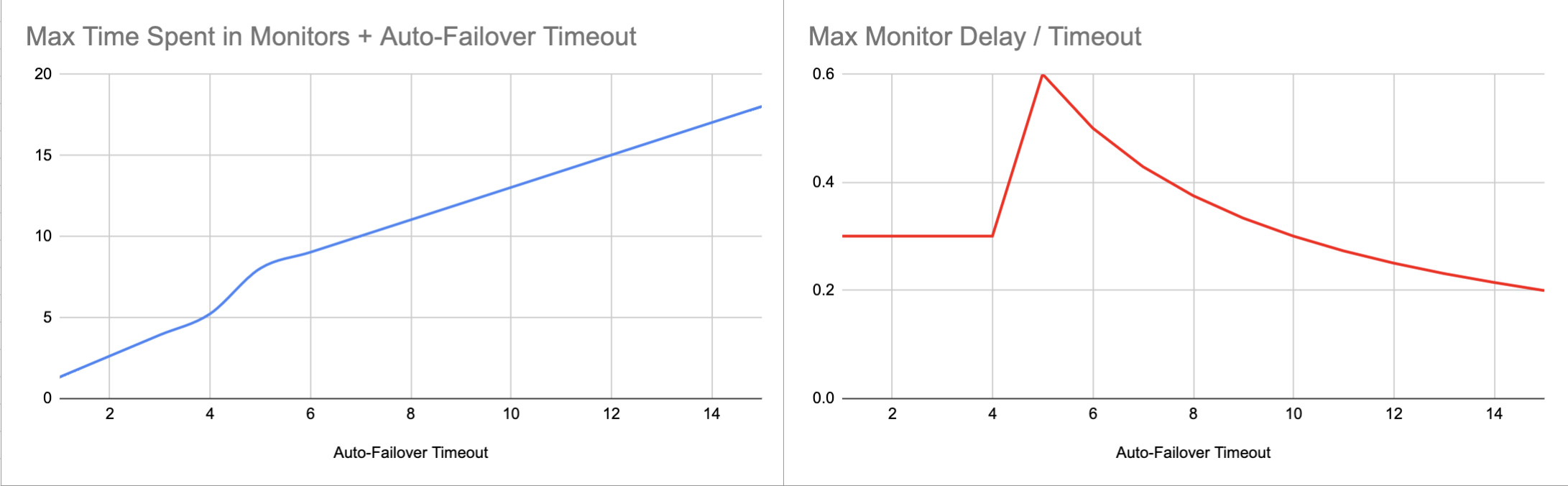
We promise 5 seconds auto failover timeout but it takes 9 seconds for the shut down node to be failed over.
The node is considered to be down if the latest heartbeat was received 2 seconds ago. So if the mode went down exactly after heartbeat was sent, you will have 2 seconds lag on detecting that it is down.
Then unfortunately we have series of internal monitors that refresh their status once a second requesting status from other monitors that also refresh their status once a second. Some unfortunate alignment of such events can account for other 2 seconds of delay.
And only after the top level monitor discovers that the node is down we begin the count down for the configured auto failover time out.
What can be improved:
1. Reduce asynchronicity in health monitors. Do all the information gathering in one tick, instead of doing independent ticks on each monitor
2. Account for 2 seconds passed since last heartbeat when we start count down to auto failover.
3. Consider using ns_node_disco info as a backup way to see if other node is down.
Attachments

Issue Links
- relates to
-
-
- Open
-
Gerrit Reviews
| For Gerrit Dashboard: MB-48412 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 190251,14 | MB-48412: wip: notify unhealthy node | master | ns_server | Status: NEW | 0 | 0 |
| 192184,9 | MB-48412: Add ability to forcefully tick auto_failover | master | ns_server | Status: NEW | 0 | 0 |