Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.1.0
-
Enterprise Edition 7.1.0 build 1317 ‧ IPv4 © 2021 Couchbase, Inc.
-
Untriaged
-
Centos 64-bit
-
1
-
No
Description
Script to Repro
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/win10-bucket-ops-temp_rebalance_magma.ini rerun=False,disk_optimized_thread_settings=True,batch_size=300 -t bucket_collections.collections_rebalance.CollectionsRebalance.test_data_load_collections_with_graceful_failover_recovery,nodes_init=5,nodes_failover=2,recovery_type=delta,bucket_spec=magma_dgm.5_percent_dgm.5_node_2_replica_magma_256,doc_size=256,randomize_value=True,data_load_stage=during,skip_validations=False'
|
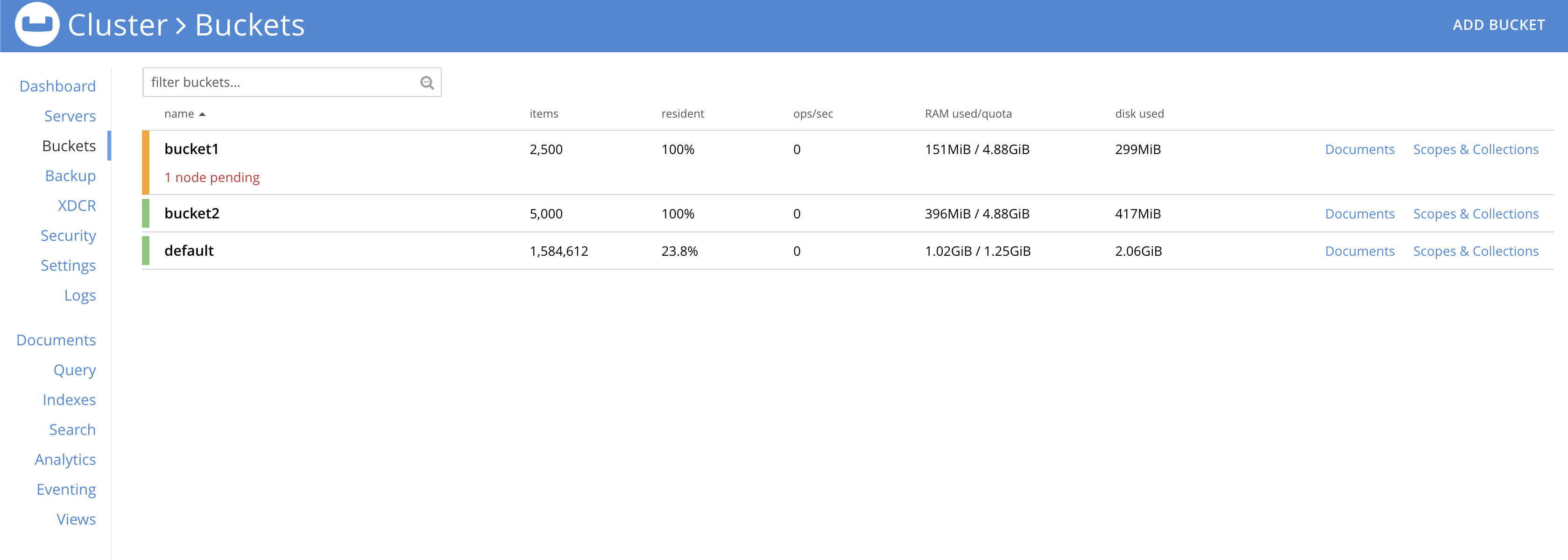
I have noticed this happening consistently during the data load stage. Nodes/Buckets turn amber consistently. It's not always the same node or the same bucket (during the course of the same test).
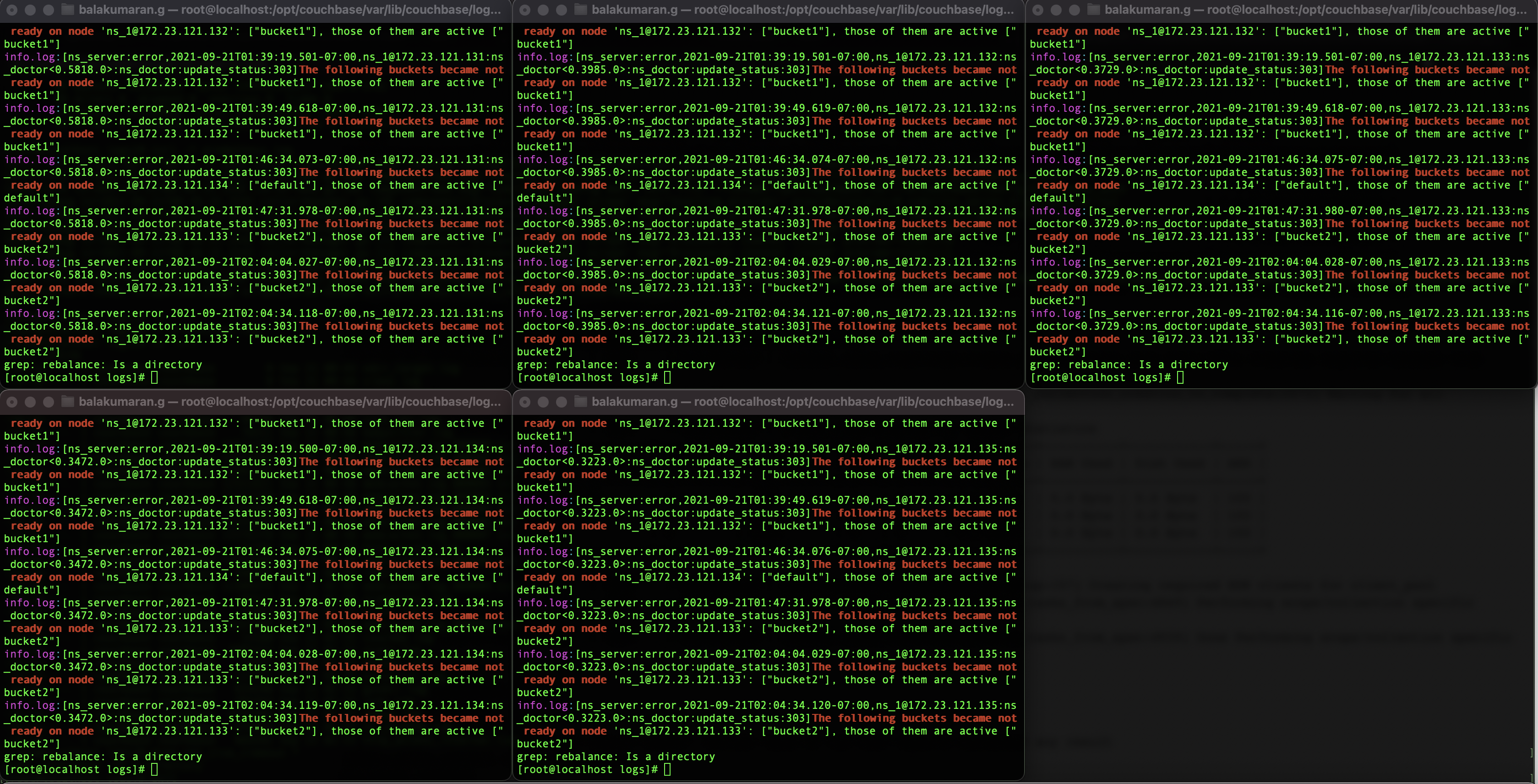
It is worth mentioning that it error.log does say that buckets are not ready on some nodes.
172.23.121.135 error.log
[ns_server:error,2021-09-21T01:37:03.508-07:00,ns_1@172.23.121.135:<0.2871.11>:ns_server_stats:report_prom_stats:108]couchdb stats reporting exception: exit:normal
|
[{mochiweb_request,send,2,
|
[{file,"/home/couchbase/jenkins/workspace/couchbase-server-unix/couchdb/src/mochiweb/mochiweb_request.erl"},
|
{line,264}]},
|
{ns_server_stats,report_couch_stats,2,
|
[{file,"src/ns_server_stats.erl"},{line,173}]},
|
{ns_server_stats,'-report_couchdb_stats/1-lc$^0/1-0-',2,
|
[{file,"src/ns_server_stats.erl"},{line,151}]},
|
{ns_server_stats,'-report_couchdb_stats/1-lc$^0/1-0-',2,
|
[{file,"src/ns_server_stats.erl"},{line,151}]},
|
{ns_server_stats,'-report_prom_stats/2-fun-0-',2,
|
[{file,"src/ns_server_stats.erl"},{line,106}]},
|
{ns_server_stats,report_prom_stats,2,
|
[{file,"src/ns_server_stats.erl"},{line,119}]},
|
{menelaus_web_prometheus,handle_get_local_metrics,2,
|
[{file,"src/menelaus_web_prometheus.erl"},
|
{line,110}]},
|
{request_throttler,do_request,3,
|
[{file,"src/request_throttler.erl"},{line,58}]}]
|
[ns_server:error,2021-09-21T01:37:25.946-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.133': ["bucket2"], those of them are active ["bucket2"]
|
[ns_server:error,2021-09-21T01:38:19.024-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.132': ["bucket1"], those of them are active ["bucket1"]
|
[ns_server:error,2021-09-21T01:38:24.665-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.133': ["bucket2"], those of them are active ["bucket2"]
|
[ns_server:error,2021-09-21T01:38:54.316-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.132': ["bucket1"], those of them are active ["bucket1"]
|
[ns_server:error,2021-09-21T01:39:19.501-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.132': ["bucket1"], those of them are active ["bucket1"]
|
[ns_server:error,2021-09-21T01:39:49.619-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.132': ["bucket1"], those of them are active ["bucket1"]
|
[ns_server:error,2021-09-21T01:46:34.076-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.134': ["default"], those of them are active ["default"]
|
[ns_server:error,2021-09-21T01:47:31.978-07:00,ns_1@172.23.121.135:ns_doctor<0.3223.0>:ns_doctor:update_status:303]The following buckets became not ready on node 'ns_1@172.23.121.133': ["bucket2"], those of them are active ["bucket2"]
|
Also noticed lot of errors in prometheus.log
172.23.121.135 prometheus.log
level=debug ts=2021-09-21T08:41:42.978Z caller=scrape.go:1117 component="scrape manager" scrape_pool=kv_high_cardinality target=http://127.0.0.1:11280/_prometheusMetricsHigh msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetricsHigh\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:41:50.599Z caller=scrape.go:1117 component="scrape manager" scrape_pool=general target=http://127.0.0.1:11280/_prometheusMetrics msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetrics\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:41:52.978Z caller=scrape.go:1117 component="scrape manager" scrape_pool=kv_high_cardinality target=http://127.0.0.1:11280/_prometheusMetricsHigh msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetricsHigh\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:00.599Z caller=scrape.go:1117 component="scrape manager" scrape_pool=general target=http://127.0.0.1:11280/_prometheusMetrics msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetrics\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:02.978Z caller=scrape.go:1117 component="scrape manager" scrape_pool=kv_high_cardinality target=http://127.0.0.1:11280/_prometheusMetricsHigh msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetricsHigh\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:10.600Z caller=scrape.go:1117 component="scrape manager" scrape_pool=general target=http://127.0.0.1:11280/_prometheusMetrics msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetrics\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:12.979Z caller=scrape.go:1117 component="scrape manager" scrape_pool=kv_high_cardinality target=http://127.0.0.1:11280/_prometheusMetricsHigh msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetricsHigh\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:20.600Z caller=scrape.go:1117 component="scrape manager" scrape_pool=general target=http://127.0.0.1:11280/_prometheusMetrics msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetrics\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:22.979Z caller=scrape.go:1117 component="scrape manager" scrape_pool=kv_high_cardinality target=http://127.0.0.1:11280/_prometheusMetricsHigh msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetricsHigh\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:30.601Z caller=scrape.go:1117 component="scrape manager" scrape_pool=general target=http://127.0.0.1:11280/_prometheusMetrics msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetrics\": context deadline exceeded"
|
level=debug ts=2021-09-21T08:42:32.980Z caller=scrape.go:1117 component="scrape manager" scrape_pool=kv_high_cardinality target=http://127.0.0.1:11280/_prometheusMetricsHigh msg="Scrape failed" err="Get \"http://127.0.0.1:11280/_prometheusMetricsHigh\": context deadline exceeded"
|
Also errors like these were seen on debug.log
172.23.121.135 debug.log
debug.log:[ns_server:debug,2021-09-21T02:24:32.119-07:00,ns_1@172.23.121.135:<0.20865.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 1780339 us
|
debug.log:[ns_server:debug,2021-09-21T02:24:37.600-07:00,ns_1@172.23.121.135:<0.21263.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 1764712 us
|
debug.log:[ns_server:debug,2021-09-21T02:24:37.600-07:00,ns_1@172.23.121.135:<0.20992.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 1764790 us
|
debug.log:[ns_server:debug,2021-09-21T02:25:08.835-07:00,ns_1@172.23.121.135:<0.22605.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 6645866 us
|
debug.log:[ns_server:debug,2021-09-21T02:25:41.965-07:00,ns_1@172.23.121.135:<0.24611.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 13051160 us
|
debug.log:[ns_server:debug,2021-09-21T02:26:11.822-07:00,ns_1@172.23.121.135:<0.26542.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 9820891 us
|
debug.log:[ns_server:debug,2021-09-21T02:26:11.824-07:00,ns_1@172.23.121.135:<0.26543.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 655191 us
|
debug.log:[ns_server:debug,2021-09-21T02:26:31.674-07:00,ns_1@172.23.121.135:<0.27813.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 9849478 us
|
debug.log:[ns_server:debug,2021-09-21T02:26:31.677-07:00,ns_1@172.23.121.135:<0.27811.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 5003731 us
|
debug.log:[ns_server:debug,2021-09-21T02:27:06.244-07:00,ns_1@172.23.121.135:<0.30251.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 4447070 us
|
debug.log:[ns_server:debug,2021-09-21T02:27:06.247-07:00,ns_1@172.23.121.135:<0.30250.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 4419470 us
|
debug.log:[ns_server:debug,2021-09-21T02:27:19.337-07:00,ns_1@172.23.121.135:<0.31165.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 3087979 us
|
debug.log:[ns_server:debug,2021-09-21T02:27:41.900-07:00,ns_1@172.23.121.135:<0.31988.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 12560831 us
|
debug.log:[ns_server:debug,2021-09-21T02:27:41.901-07:00,ns_1@172.23.121.135:<0.31986.17>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 12560921 us
|
debug.log:[ns_server:debug,2021-09-21T02:28:11.269-07:00,ns_1@172.23.121.135:<0.1429.18>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 4854487 us
|
debug.log:[ns_server:debug,2021-09-21T02:28:23.555-07:00,ns_1@172.23.121.135:<0.2406.18>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 1379203 us
|
debug.log:[ns_server:debug,2021-09-21T02:28:24.098-07:00,ns_1@172.23.121.135:<0.2339.18>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 2827366 us
|
debug.log:[ns_server:debug,2021-09-21T02:28:37.044-07:00,ns_1@172.23.121.135:<0.3116.18>:ns_memcached:perform_very_long_call_with_timing:849]ensure_bucket took too long: 2944442 us
|
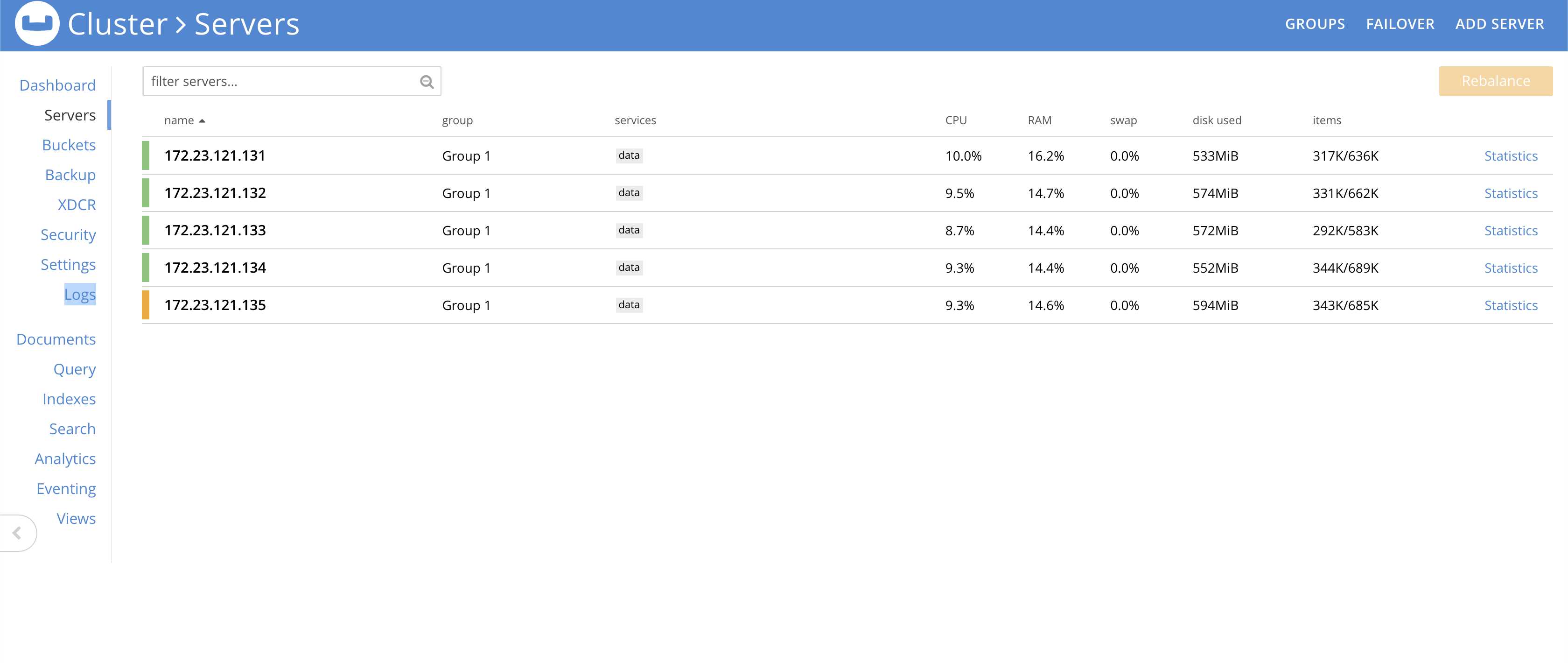
CPU/RAM/Disk were under control when this was happening. Also confirmed that there are no dropped ticks to rule out any network issues.
cbcollect_info attached. It is consistently repro'able.
We did not notice this before as I don't remember logging into UI.
Attachments
Issue Links
- causes
-
-

- Closed
-
- is duplicated by
-
-
- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
| For Gerrit Dashboard: MB-48533 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 163638,2 | Revert "MB-48533 stats: Fix population of get stats counters" | master | magma | Status: NEW | 0 | +1 |
| 162998,8 | MB-48533 lsm: Remove lock contention in stats read path due to snapshot manager | master | magma | Status: MERGED | +2 | +1 |
| 163065,3 | MB-48533 stats: Fix population of get stats counters | master | magma | Status: MERGED | +2 | +1 |