Description
Steps:
- Create a 9 node cluster
- Create a 5 node XDCR remote cluster
- Create required buckets and 10 collections.
- Create required buckets and 10 collections on XDCR remote.
- Create 1000000 items/collection with durability majority
- Update 1000000 keys to create 50 percent fragmentation
- Create new 1000000 items/collection with durability majority
- Update new 1000000 keys to create 50 percent fragmentation
- Start a CRUD data load asynchronously.
- Rebalance in with Loading of docs. Crash and resume rebalance at 20%, 40%, 60%, 80%.
- Crash Magma/memc on source cluster 20 times with Loading of docs
- Rebalance Out with Loading of docs. Crash and resume rebalance at 20%, 40%, 60%, 80%.
- XDCR replication seems to be stuck. Since 30 mins 64.005M mutations remaining
- Also, because there were continuous CRUD going on the in the source cluster items in destination cluster are more than in source. Not sure if this is expected?
|
QE Test |
git fetch "http://review.couchbase.org/TAF" refs/changes/06/163706/1 && git checkout FETCH_HEAD
|
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/magma_temp_job4.ini -p bucket_storage=magma,bucket_eviction_policy=fullEviction,rerun=False,iterations=2,sdk_timeout=60,log_level=debug,infra_log_level=debug,skip_cleanup=True -t aGoodDoctor.Hospital.Murphy.SystemTestMagma,nodes_init=9,graceful=True,skip_cleanup=True,num_items=1000000,num_buckets=1,bucket_names=GleamBook,doc_size=1024,key_size=18,assert_crashes_on_load=True,num_collections=10,xdcr_collections=10,maxttl=10,num_indexes=20,pc=10,xdcr_remote_nodes=5,index_nodes=0,query_nodes=0,cbas_nodes=0,fts_nodes=0,ops_rate=50000,doc_ops=create:update:delete:read,durability=Majority,crashes=10 -m rest'
|
I have this observation with XDCR that the RAM usage on the source/Dstn cluster is always very high while there is no mutation on the source cluster and just XDCR is runing.
Source
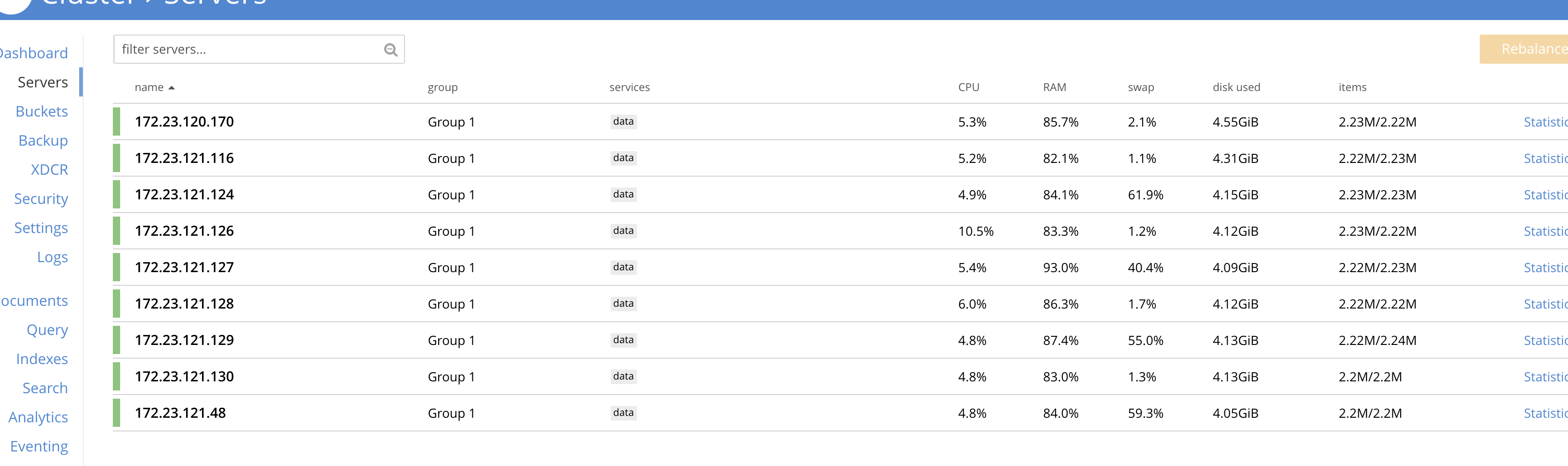
Destination

{kind=link}
{kind=link}