Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
7.1.0
-
Build number: 7.1.0-1361
OS: Amazon Linux 2
ARM instance: m6g.large
2vCPU
8GB Memory
40GB EBS
-
Triaged
-
1
-
Unknown
-
KV 2021-Nov
Description
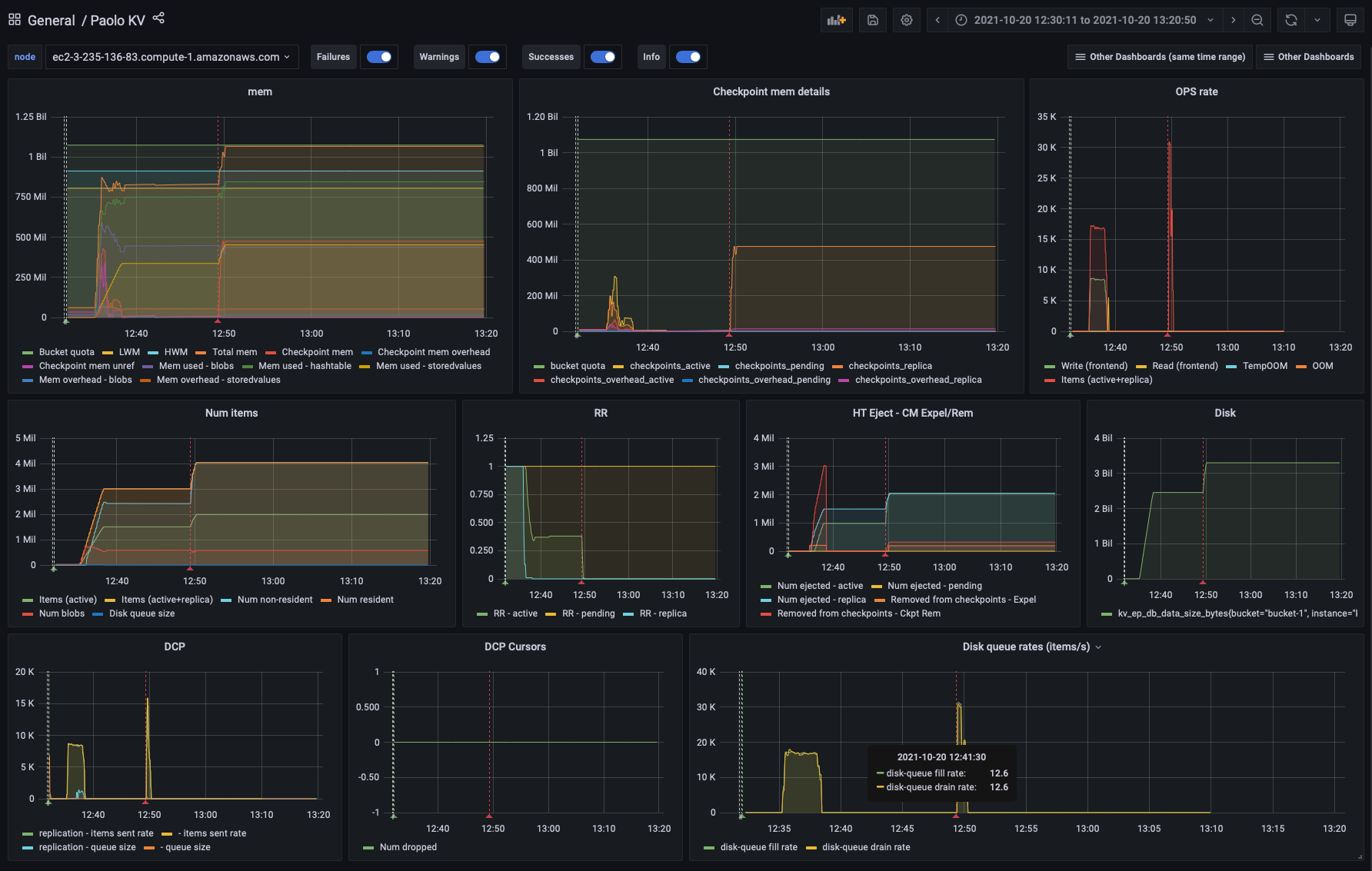
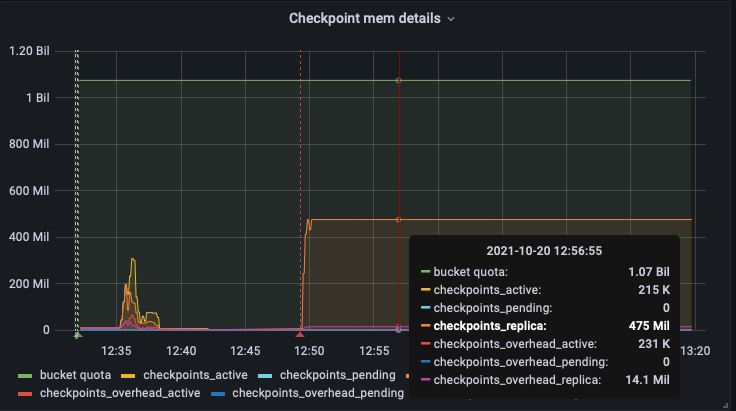
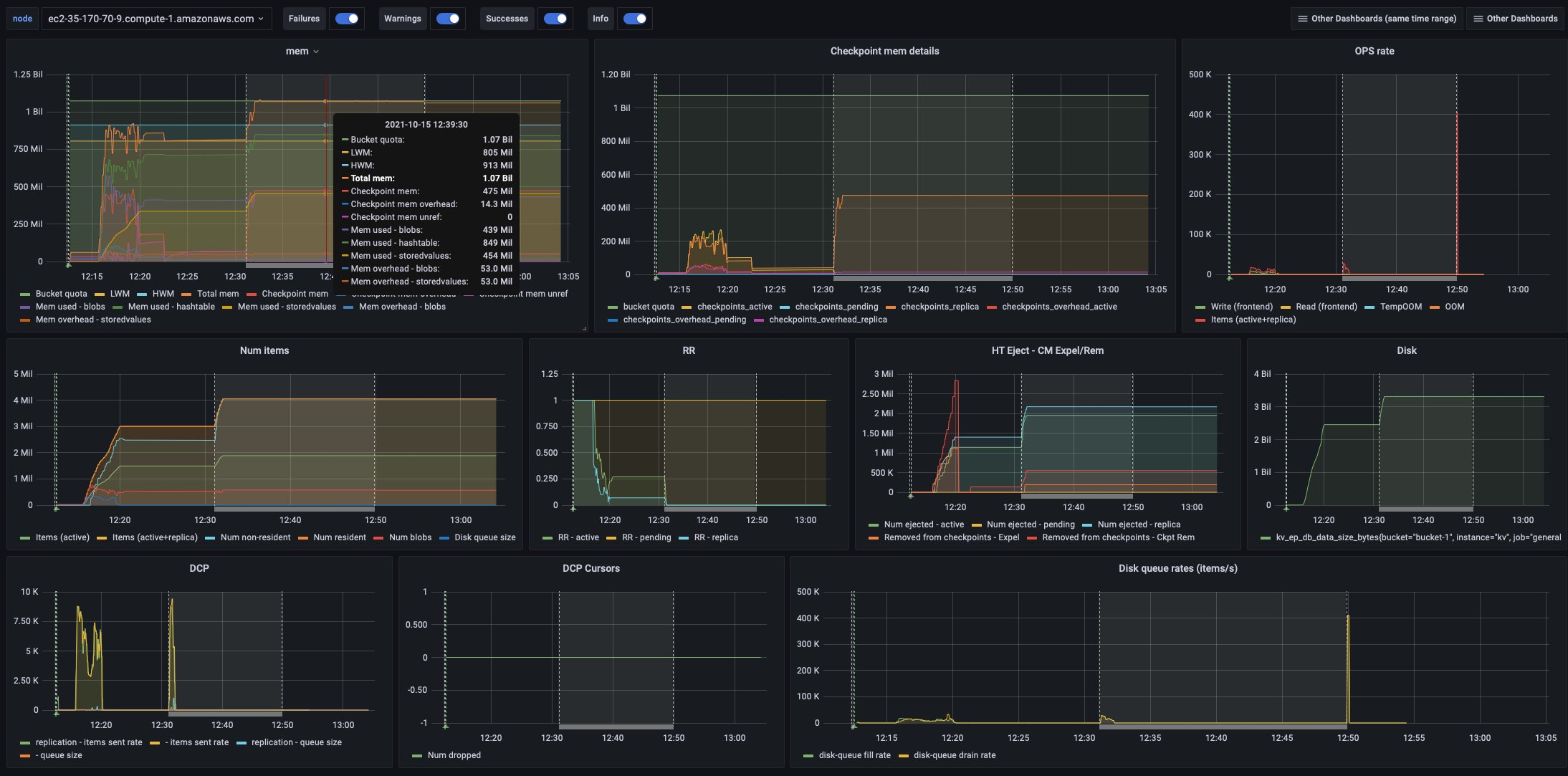
During rebalance performance tests on ARM AWS instances, the tests consistently hang - an example job can be found here along with the logs:
http://perf.jenkins.couchbase.com/job/Cloud-Tester/600/
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2021-10-07T223241-ns_1%40ec2-3-219-56-9.compute-1.amazonaws.com.zip
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2021-10-07T223241-ns_1%40ec2-3-223-6-164.compute-1.amazonaws.com.zip
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2021-10-07T223241-ns_1%40ec2-44-195-22-82.compute-1.amazonaws.com.zip
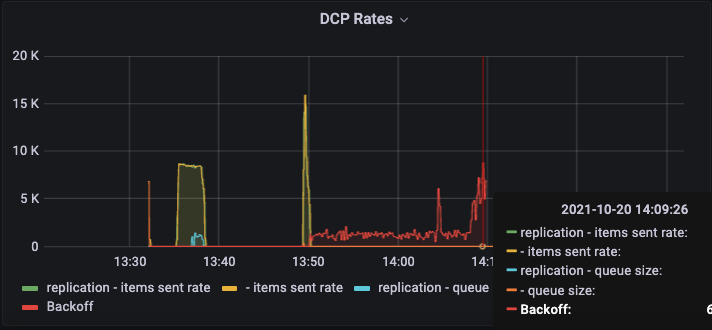
The rebalance seems to hang on 'still waiting for backfill on connection', this happens 115 times in the logs:
[rebalance:debug,2021-10-07T22:35:41.445Z,ns_1@ec2-44-195-22-82.compute-1.amazonaws.com:<0.1108.3>:dcp_replicator:wait_for_data_move_on_one_node:192]Still waiting for backfill on connection "replication:ns_1@ec2-44-195-22-82.compute-1.amazonaws.com->ns_1@ec2-3-223-6-164.compute-1.amazonaws.com:bucket-1" bucket "bucket-1", partition 745, last estimate {0,0, <<"calculating-item-count">>} |
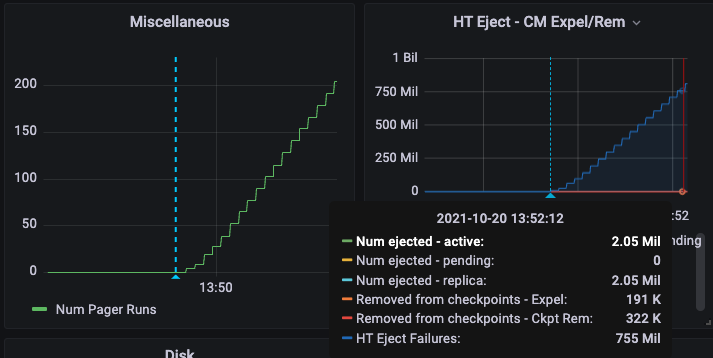
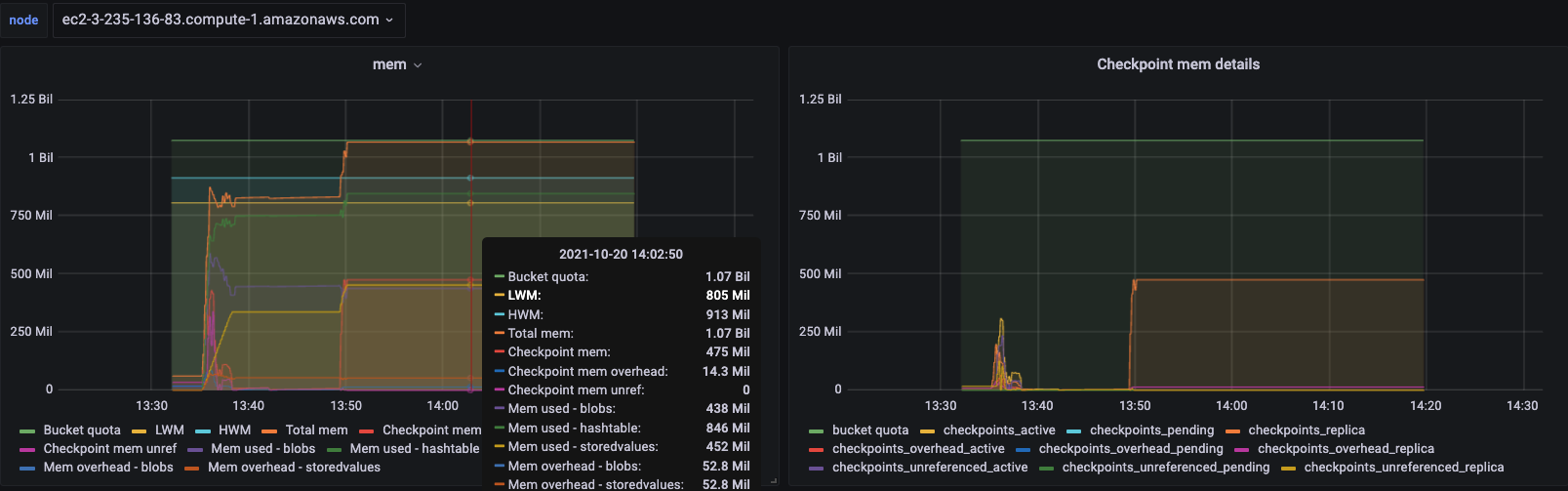
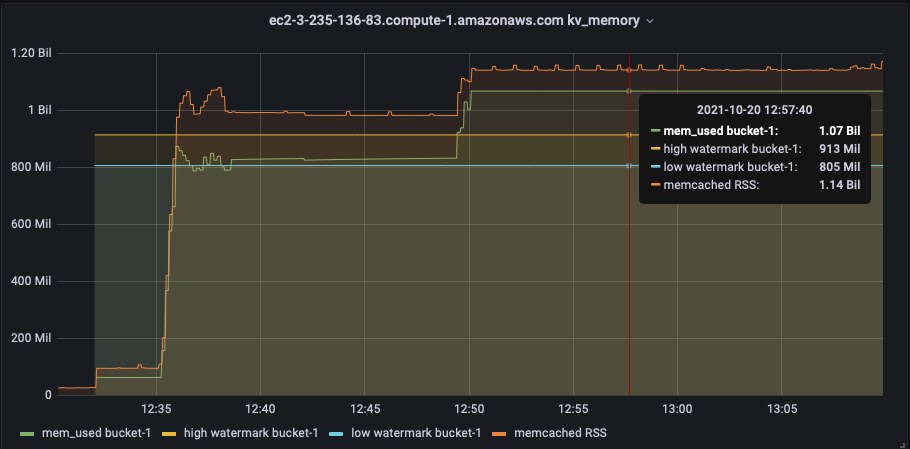
During this time memcached keeps returning <<"calculating-item-count">> with no estimation, CPU usage also spikes at this time.
Attachments


Issue Links
| For Gerrit Dashboard: MB-49037 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 165745,4 | MB-49037: Add ep_ht_item_memory stat | master | kv_engine | Status: MERGED | +2 | +1 |