Details
-
Bug
-
Resolution: Not a Bug
-
 Major
Major
-
None
-
7.1.0
-
Triaged
-
1
-
Unknown
-
KV 2021-Nov
Description
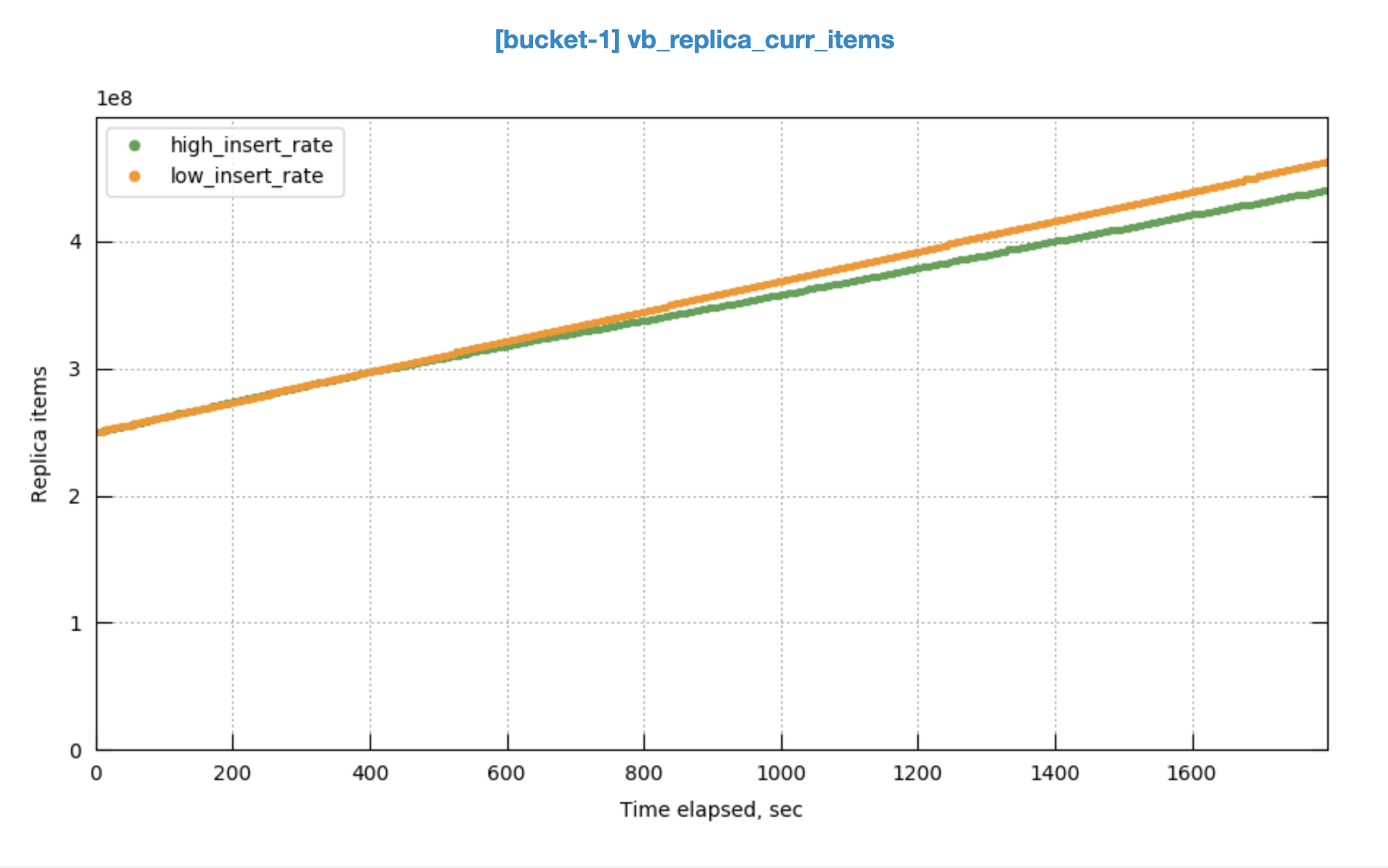
Note: Initially opened on performance variation between, that has been addressed, but now tracking the issue where replica item count does not reach active
—
In Magma insert only tests, we see high performance variation.
http://172.23.123.237/#/timeline/Linux/hidd/S0/all

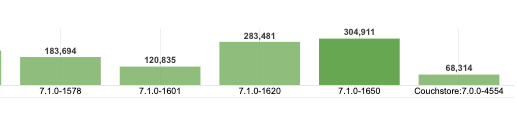
In the latest runs with build 7.1.0-1558, the throughput changed from 122K to 226K.
| Build | Throughput | Job |
|---|---|---|
| 7.1.0-1558 | 122,966 | http://perf.jenkins.couchbase.com/job/rhea-5node2/1538/ |
| 7.1.0-1558 | 226,157 | http://perf.jenkins.couchbase.com/job/rhea-5node2/1539/ |
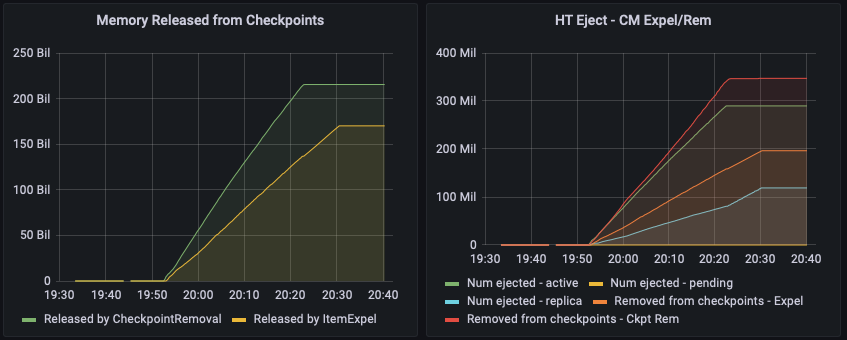
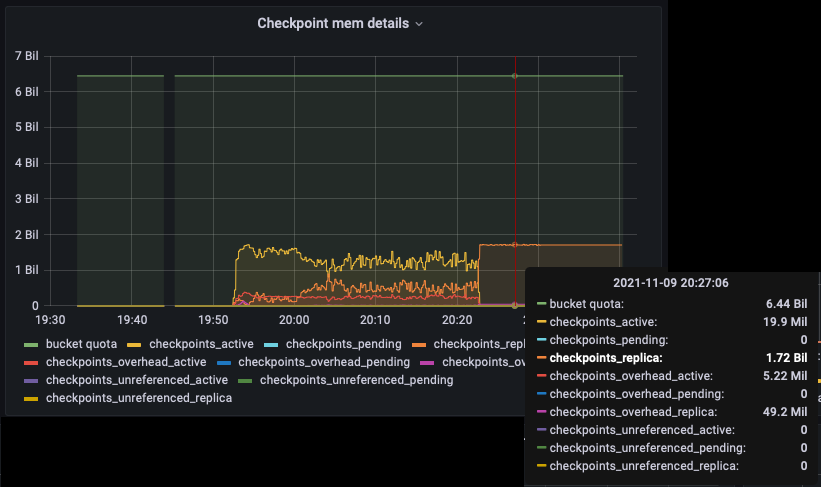
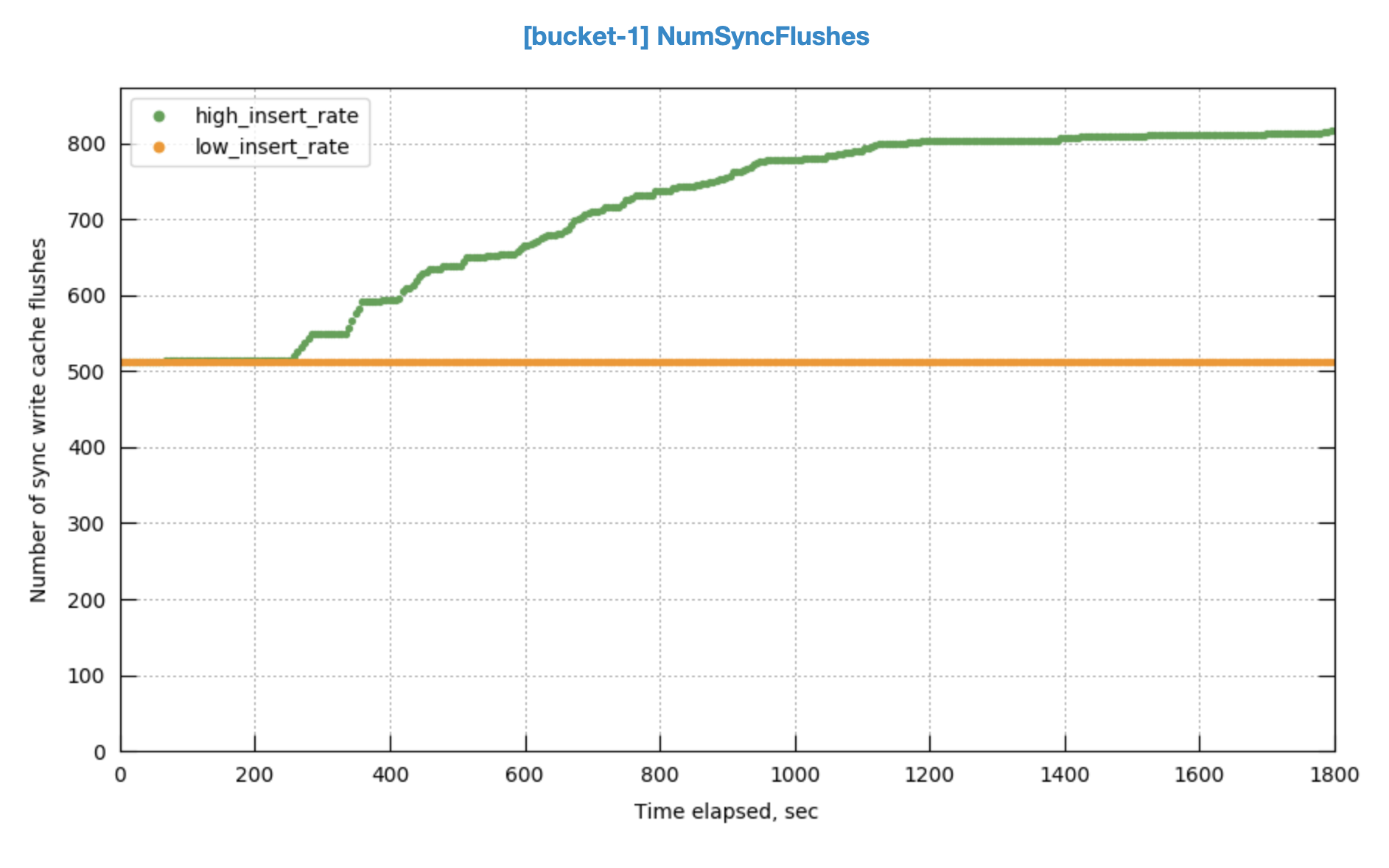
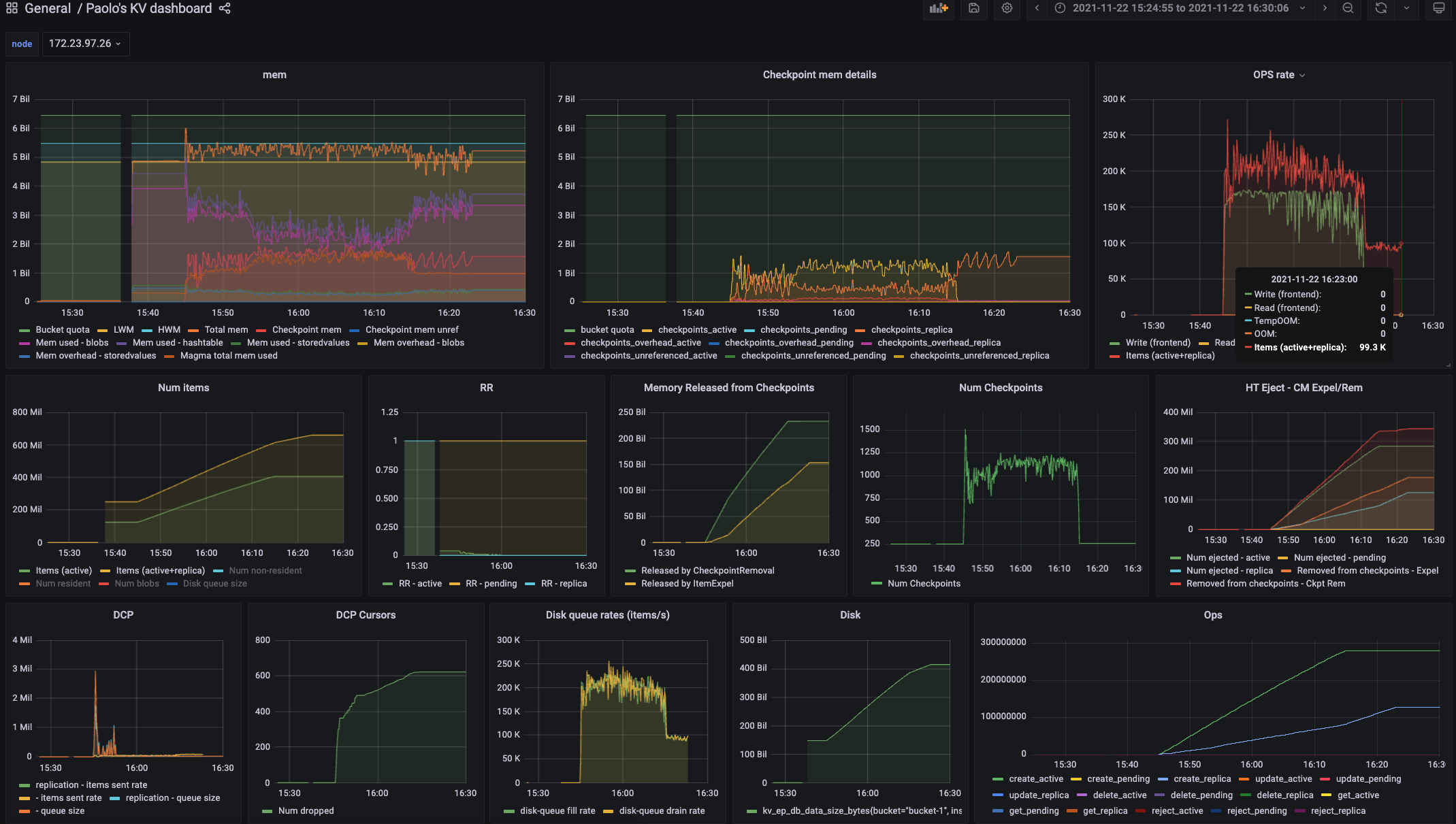
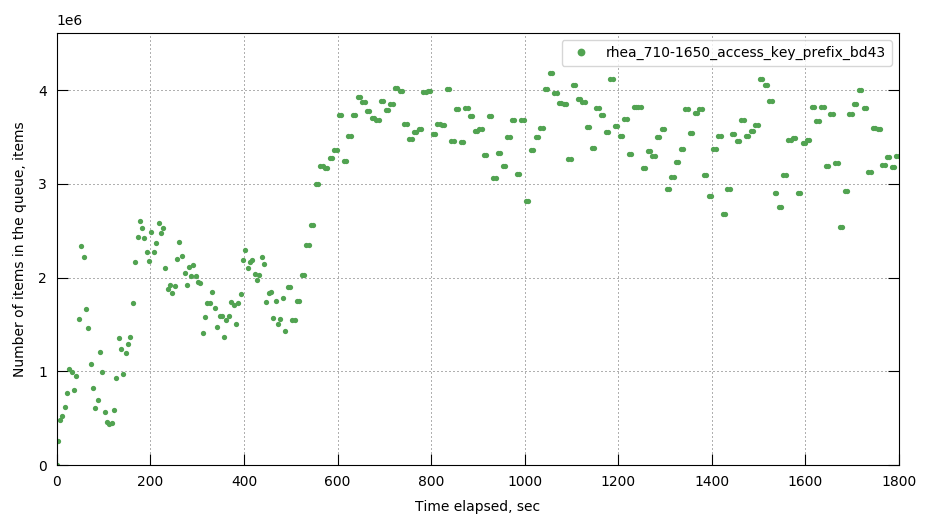
In the run having higher throughput, replica sync rate can't catch up.
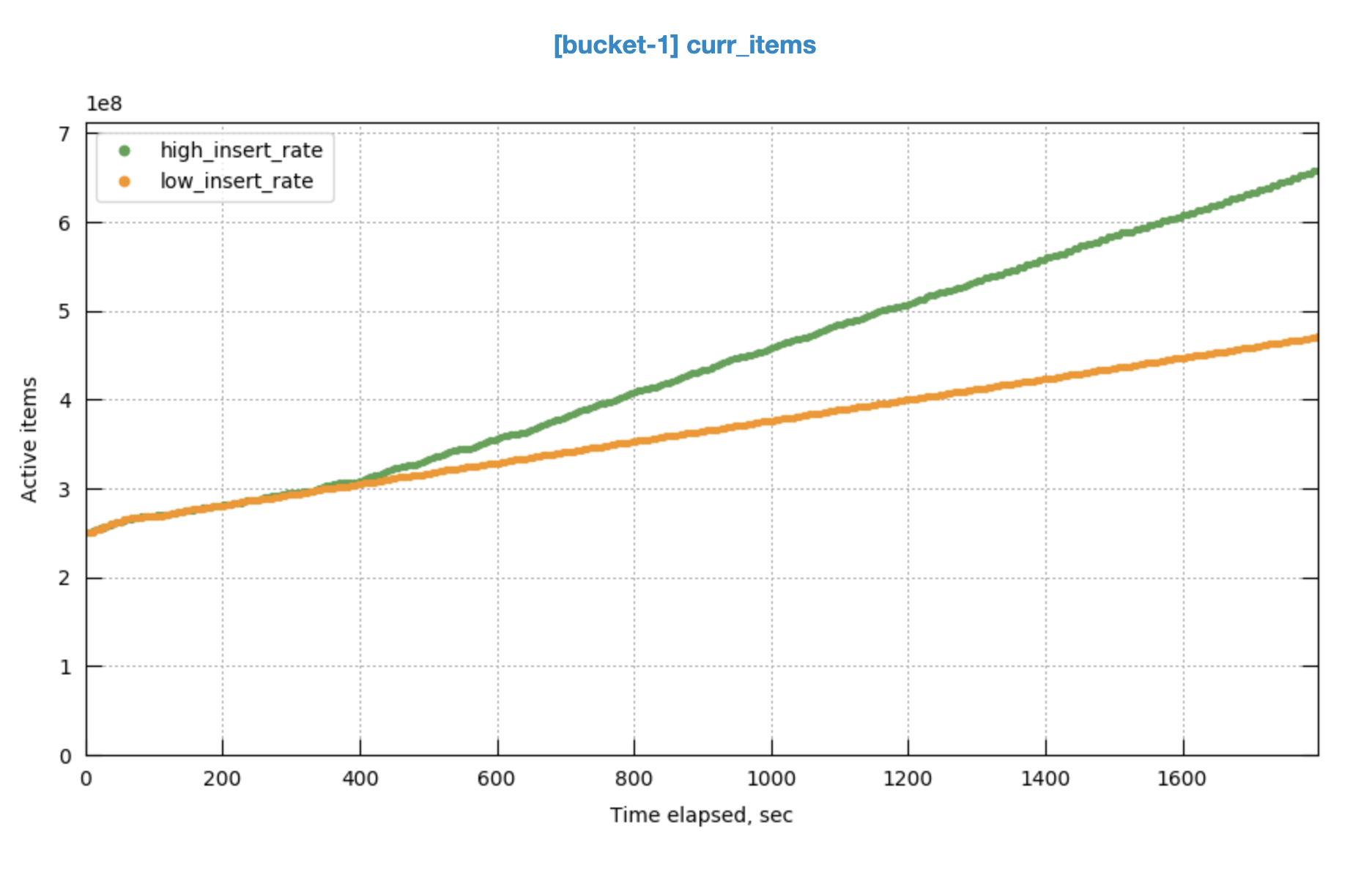
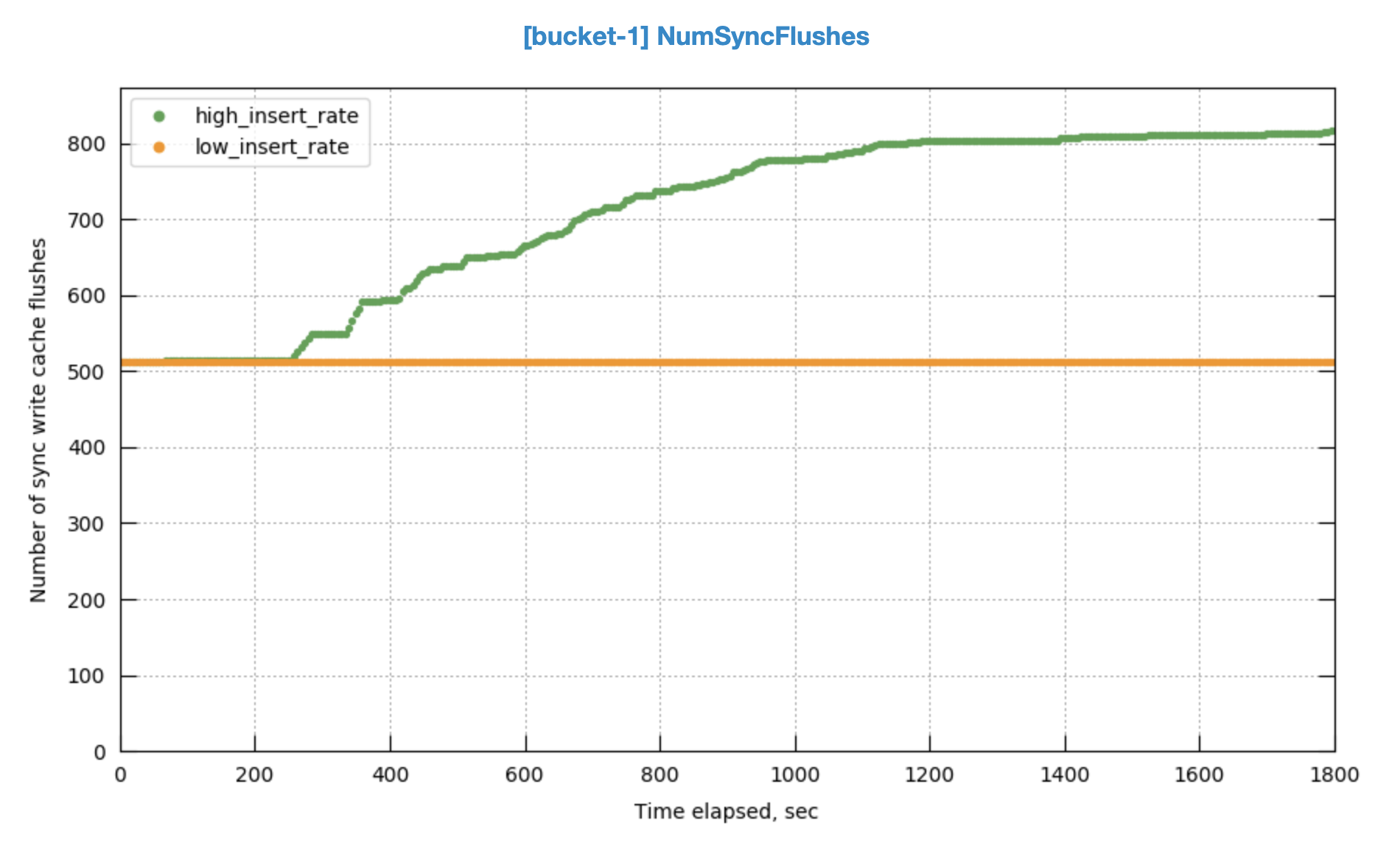
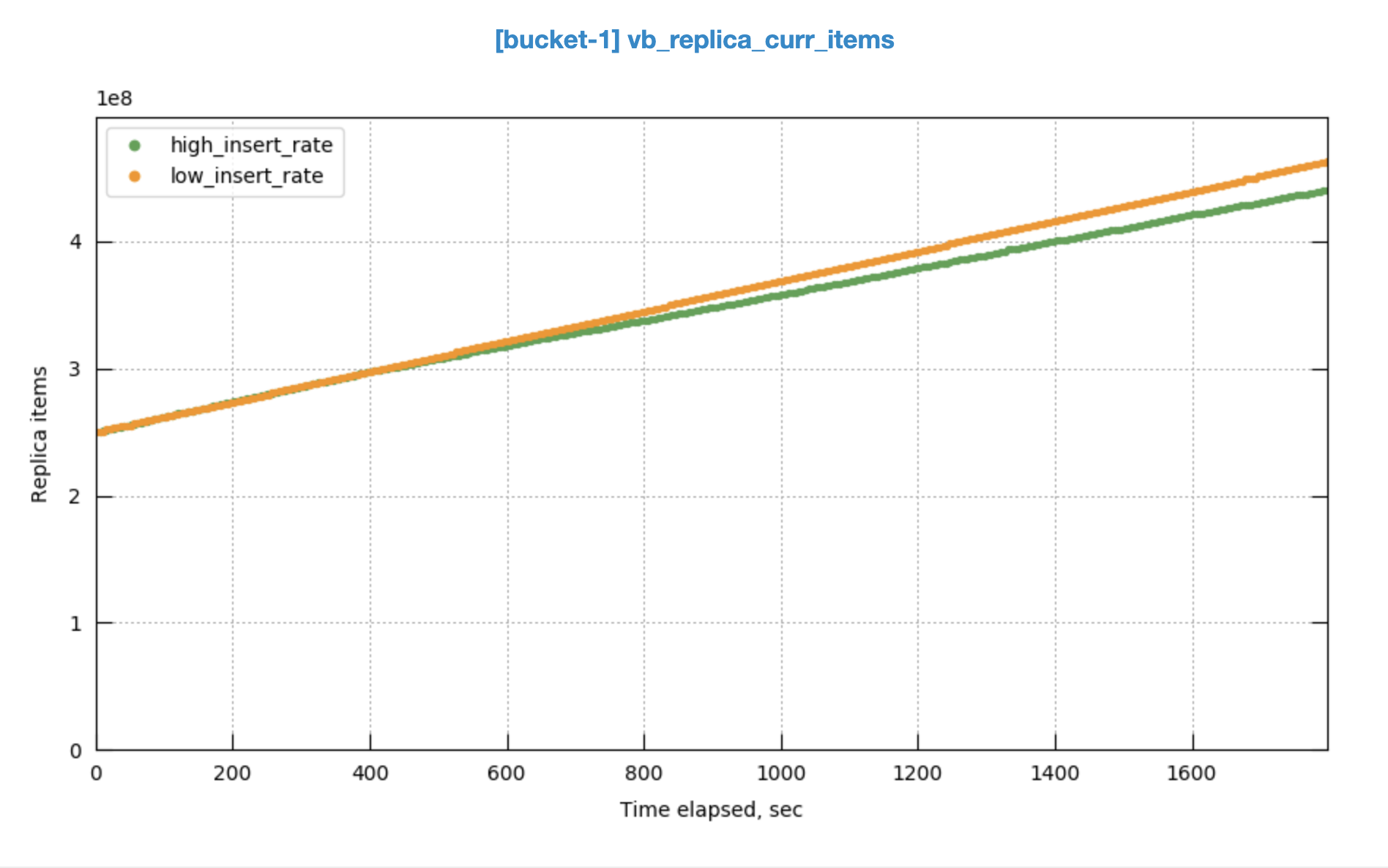 There are more sync write flushes after a certain point.
There are more sync write flushes after a certain point.
Sarath Lakshman
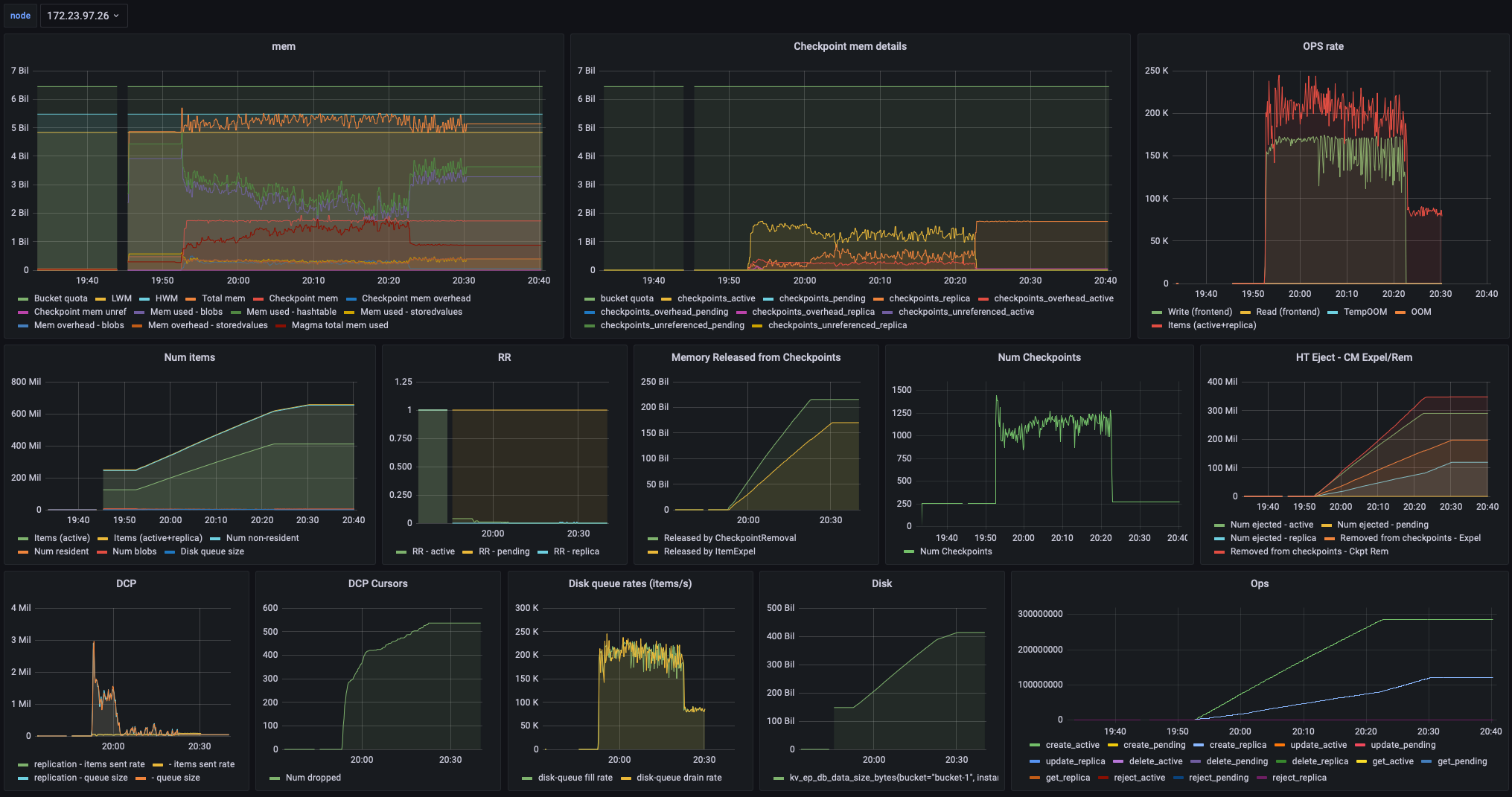
Please take a look. Is there a way we can change checkpoint settings? It looks like the runs can go to different modes (or code paths), even with the same build.
Attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Issue Links
- relates to
-
-
- Closed
-