Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.1.0
-
Enterprise Edition 7.1.0 build 1694 ‧
-
Triaged
-
Centos 64-bit
-
1
-
No
-
KV 2021-Dec, KV 2022-Feb, KV March-22
Description
Script to Repro
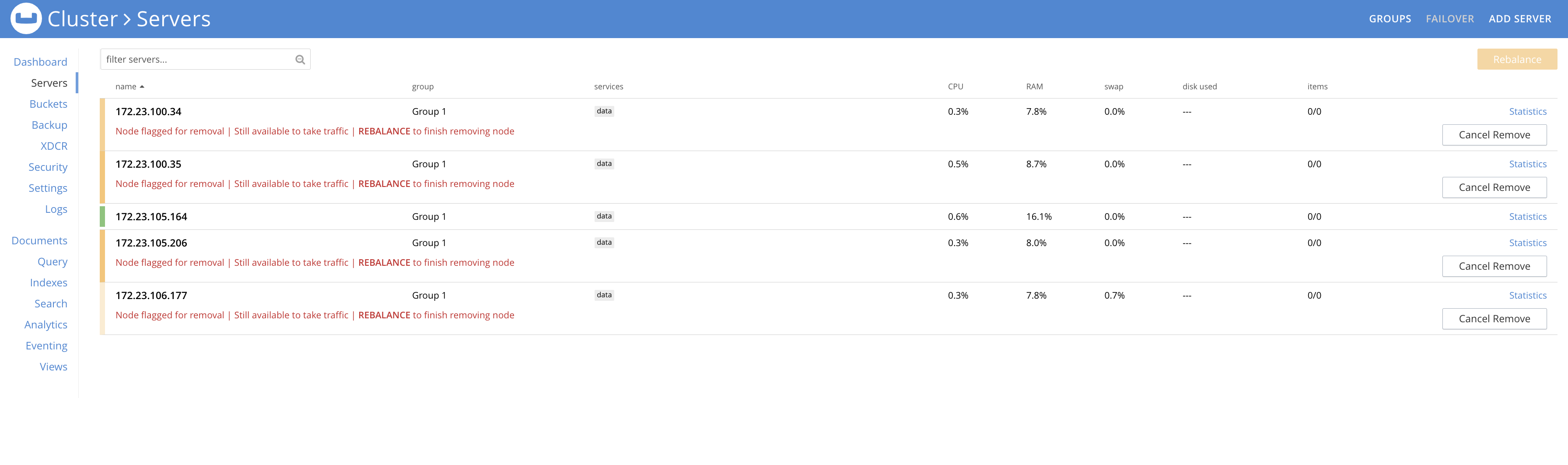
This can happen in the tearDown part of the any test. So, in tearDown method we drop all the buckets and remove all the nodes in the cluster. This fails as shown below.
|
172.23.120.206 10:05:03 PM 11 Nov, 2021 ( 2021-11-11T22:05:03.228-08:00 )
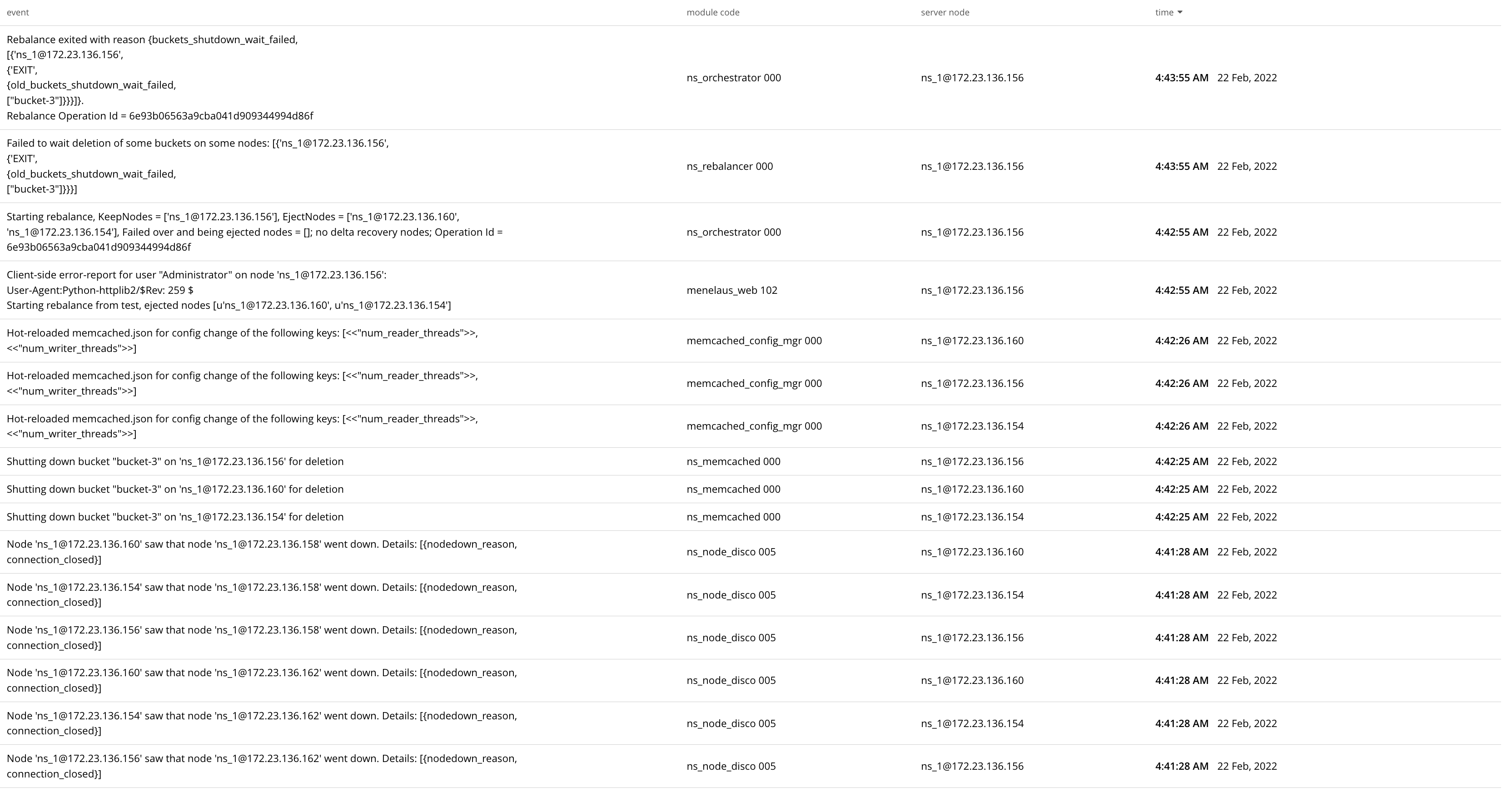
Rebalance exited with reason {buckets_shutdown_wait_failed,
|
[{'ns_1@172.23.120.206',
|
{'EXIT',
|
{old_buckets_shutdown_wait_failed,
|
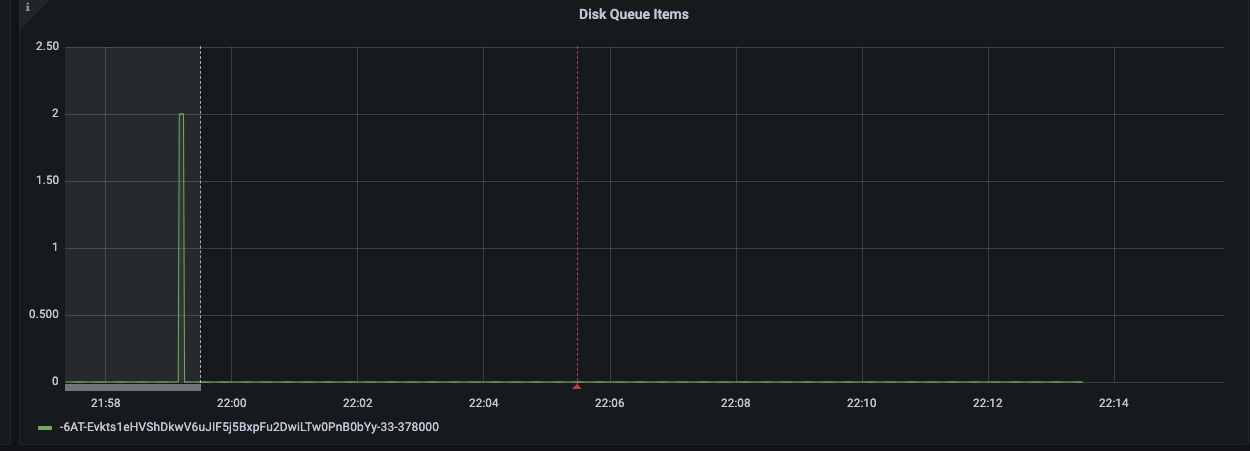
["-6AT-Evkts1eHVShDkwV6uJIF5j5BxpFu2DwiLTw0PnB0bYy-33-378000"]}}}]}.
|
Rebalance Operation Id = dbb8d76ebc02c654f2c23fbbabac68e9
|
Even retried rebalance failed.
172.23.120.206 10:06:28 PM 11 Nov, 2021
Rebalance exited with reason {buckets_shutdown_wait_failed,
|
[{'ns_1@172.23.120.206',
|
{'EXIT',
|
{old_buckets_shutdown_wait_failed,
|
["-6AT-Evkts1eHVShDkwV6uJIF5j5BxpFu2DwiLTw0PnB0bYy-33-378000"]}}}]}.
|
Rebalance Operation Id = 1754a1e783a53551c9f546338cebb3d7
|
Based on the failures it does look like the previously dropped bucket too longer than expected to get deleted.
172.23.104.186 10:03:32 PM 11 Nov, 2021
Shutting down bucket "-6AT-Evkts1eHVShDkwV6uJIF5j5BxpFu2DwiLTw0PnB0bYy-33-378000" on 'ns_1@172.23.104.186' for deletion
|
Maybe we need to figure out a way to disable the rebalance button until the bucket is fully deleted.
cbcollect_info attached.
Attachments
Issue Links
| For Gerrit Dashboard: MB-49512 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 170364,5 | MB-49512: Folly executor subclass weirdness | master | kv_engine | Status: NEW | 0 | -1 |