Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.1.0
-
Untriaged
-
-
1
-
Unknown
-
KV 2021-Dec, KV 2022-Jan
Description
Summary
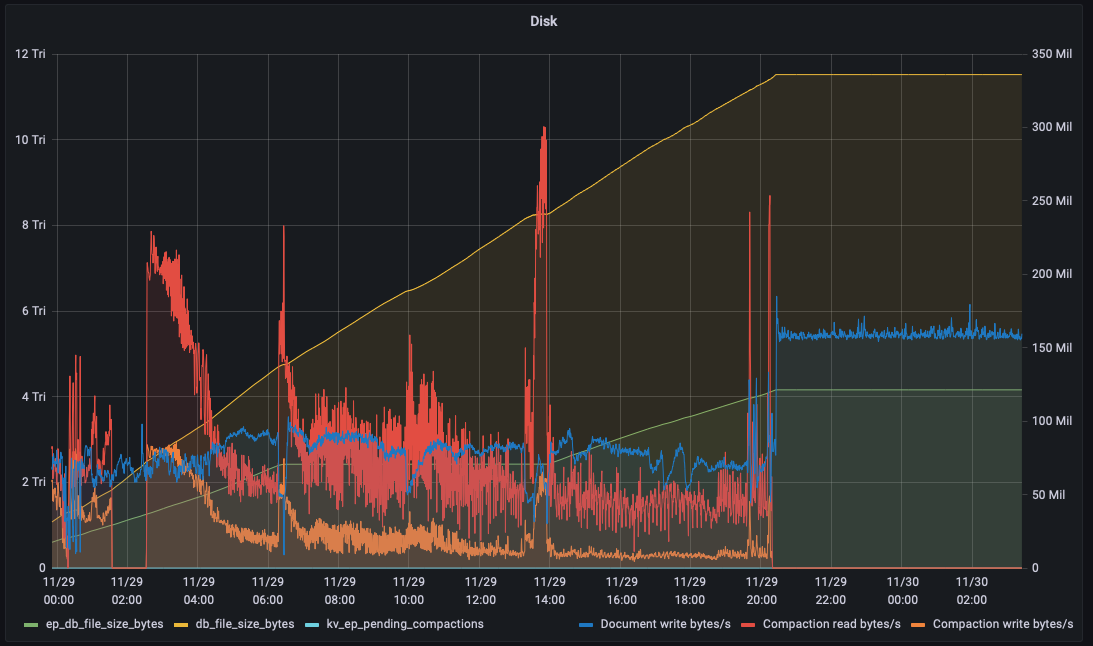
As seen during MB-49702, the single compaction task cannot keep up with large numbers of Flusher (disk writer) tasks under a high throughput workload with a large number of shard / writer threads. Ultimately this results in the available disk space being exceeded and disk writes failing. (MB-49702 had 10TB disk space per node, ~5TB data and fragmentation was set to 50%).
Background
Up until version 4.5.0, 3 vBuckets could be compacted concurrently for a given vBucket. However, this caused a number of issues with front-end write latency, and as part of MB-18426 (included in v4.5.1) this was reduced to 1 vBucket at a time. Quoting from the commit message which changed this:
MB-18426: Reduce compaction_number_of_kv_workers from 4 to 1There have been a number of instances where the IO cost of compaction has had a detremental effect on normal "front-end" KV operations - see
MB-18426for full details, but as one example:In a heavy write use case where a document is written to once, read once and then deleted. The documents are only stored in the bucket until they are processed, so in a normal state a document only exists for a few minutes. It was noted that when the 3 (see note) compactors ran the disk would become fully saturated and this would cause huge spikes in the disk queues up to 36 million. When the compaction_number_of_kv_workers was reduced, it had the following impacts:
- Reduce the disk queue to ten of thousands from 36 million, which also reduce the amount of memory the bucket was using.
- Reduce the disk IO.
- Most surprisingly reducing the disk space required from 280GB to 40GB. I suspect this was because the deletes were being blocked on the disk write queue.
- The fragmentation percentages fluctuates a lot more.
Similar results have been reported in 2 other customer enviroments.
This patch reduces the default number down to 1 - it can still be overridden if necessary via diag/eval.
Note: While the value of compaction_number_of_kv_workers was previously 4, we would normally only see 3 compactors run in parallel in ep-engine due to not scheduling more than num_shards/2 + 1 compactors at once - see EventuallyPersistentStore::compactDB.
While this change did improve the aforementioned issues, it was arguably not addressing the root cause of what compaction was interfering with front-end writes and reads.
The more direct cause of those issues was identified via MB-25509, which found that it was the large disk writes during compaction being flushed to the underlying filesystem / disk which could monopolise the disk bandwidth. Of note - this didn't just affect the vBucket file(s) being flushed, but other files also as it is the underlying disk which became saturated.
This issue was addressed by having compaction (and the flusher) call fsync() every N bytes instead of waiting until the entire file was written performing one fsync at file close - again quoting from the commit message:
MB-25509: Support calling fsync() periodically during compactionAdd a new config param 'fsync_after_every_n_bytes_written'. When set to a non-null value, configures couchstore to issue a sync() after every N bytes of compaction data is written.
The default value has been set at 16MB - local testing with 1.5GB vBucket files suggests this is a good tradeoff between bg fetch latency and compaction write throughput:
avg_bg_wait_time (no compaction): 50-100μs
avg_bg_wait_time (compaction, 16MB): 50-200μsFor comparision, when run with no automatic sync():
avg_bg_wait_time (compactionB): 100,000-300,000μs
This change was included in v5.5.0. At this point, having only a single compactor running didn't appear to be an issue - I'm not aware of any issues where compaction couldn't keep up with the flusher. This was likely due to the fact that we only split a Bucket into 4 shards, and hence there was a maximum of 4 vBuckets which could be flushed concurrently - which would drop to 3 concurrent flushers when compaction is running (compaction and flushing of a vBucket are exclusive).
Problem
However, as of v6.5.0 we:
- Changed the default number of shards from 4 to number_of_logical_CPU_cores, and
- Exposed settings in the UI to increase the number of Writer threads from 4 to number_of_logical_CPU_cores by selecting "Disk I/O Optimised" Writers, or even greater numbers if manually selected.
These changes we made to improve SyncWrite persistence latencies, so we could exploit more of the underlying IO concurrency on larger capacity machines - 4 concurrent writer was typically insufficient.
However, this changed the flusher / compaction "balance of power" - on large machines (for example the 72 core machine used in MB-49702), with Writer Threads set to "Disk IO Optimised" we can have up to 72 vBuckets being flushed concurrently, while we still only have 1 compactor task. One compactor is insufficient to keep up with the write throughput (and hence fragmentation increase) of 72 writer threads, assuming there is sufficient front-end load performing mutations.
The result is that compaction is running constantly - compacting 1 vBucket after another sequentially but once it has compacted the last vBucket the overall fragmentation has already grown greater than it was when compaction started. Fragmentation does not have a net reduction (to below the compaction threshold), and as such disk space usage grows and eventually fills the disk.
I believe this issue has been present since 6.5.0, however a couple of factors have highlighted it in newer releases (7.0.0 / Neo):
- We are now more aggressively testing larger volumes of data, at lower residency ratios.
- As a consequence, less of the vBucket file data is in OS buffer cache (as there's much smaller percentage of buffer cache relative to file size), and hence compaction is relatively speaking slower (reading the existing valid data to then write back the compacted file will be hitting the actual disk medium a higher percentage of the time).
- Additionally, the machines used for larger volumes of data are being configured with more writer threads (to more quickly flush that data to disk) - for example while a 72 core machine will only have 4 writer threads by default, changing to "Disk IO Optimised" will create 72 and hence up to 72 vBuckets can be flushed concurrently.
- As of 7.0.0 we allow concurrent flushing and compaction for couchstore (
MB-38428). That means that while compaction has a much lower impact on flush latency (we only block the flusher at the very end of compaction to "catch up" with any mutations made since the last compaction iteration started), it means that one more flusher can be running concurrently with compaction compared to previously.
I don't know how much each of these two factors contributes to higher fragmentation in the above scenario - it would be reasonable to assume (1) is the larger issue, however (2) could also be significant, given that compaction has to do more work now (as it's playing catch-up with the flusher) and hence can take a bit longer to compact a vBucket.
Attachments

Issue Links
| For Gerrit Dashboard: MB-49858 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 167376,3 | MB-49858: BloomFilter tidy up | master | kv_engine | Status: MERGED | +2 | +1 |
| 167377,8 | MB-49858: Add bloom_filter_memory stat | master | kv_engine | Status: MERGED | +2 | +1 |
| 167490,3 | MB-49858: Compaction throttle: account for #writer threads | master | kv_engine | Status: MERGED | +2 | +1 |
| 169640,3 | MB-50389: Move CompactVBucketTask from Writer to AuxIO thread pool | master | kv_engine | Status: MERGED | +2 | +1 |