Details
-
Task
-
Resolution: Unresolved
-
 Major
Major
-
7.1.0
-
1
Description
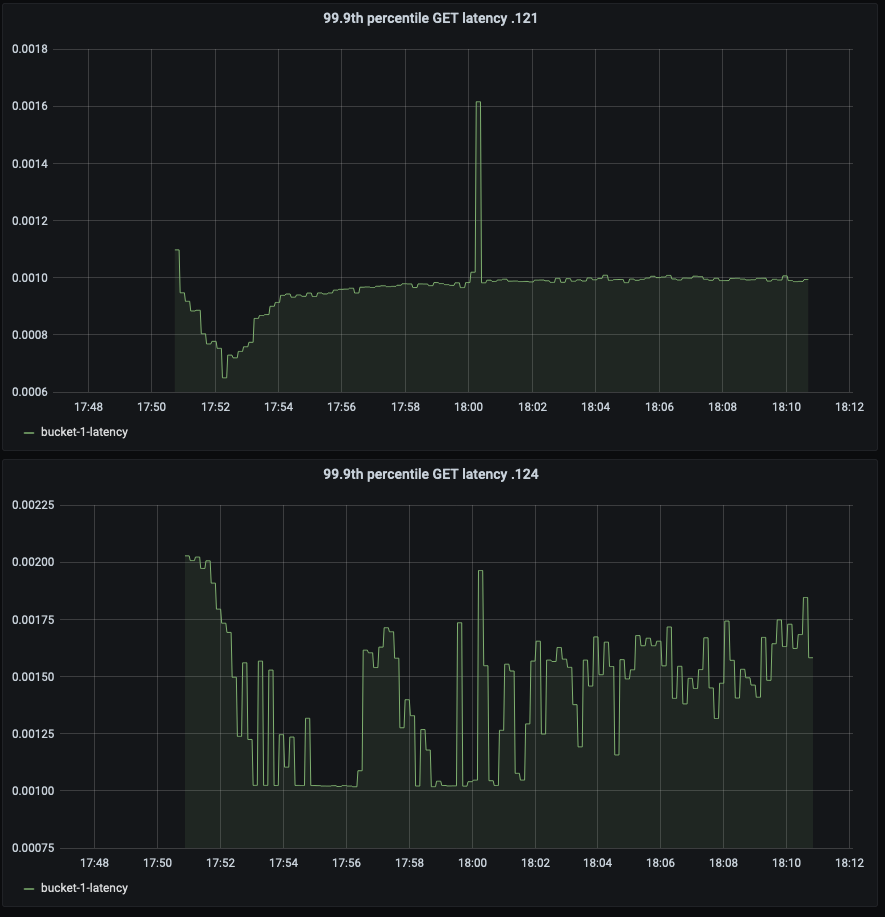
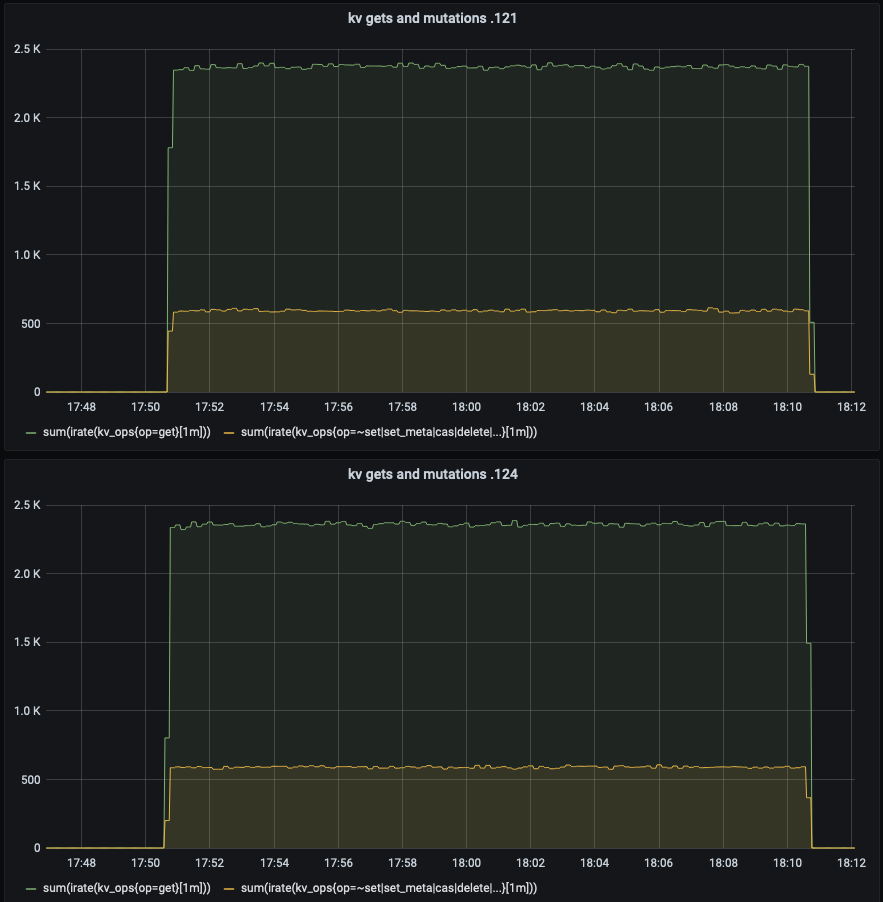
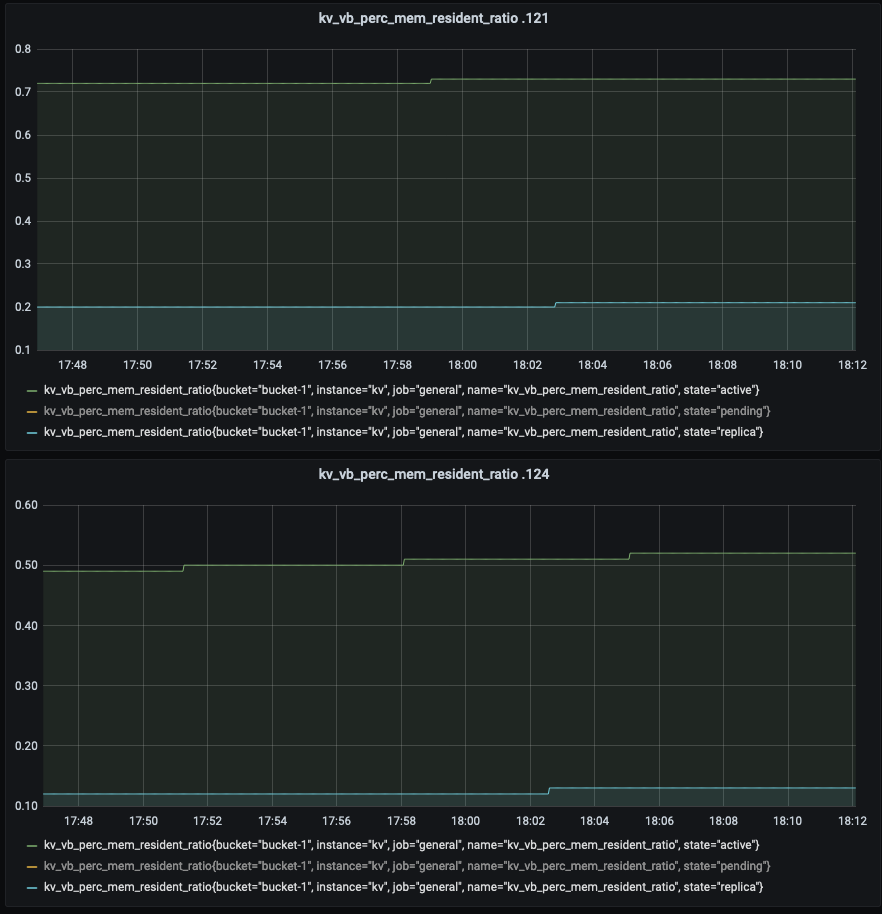
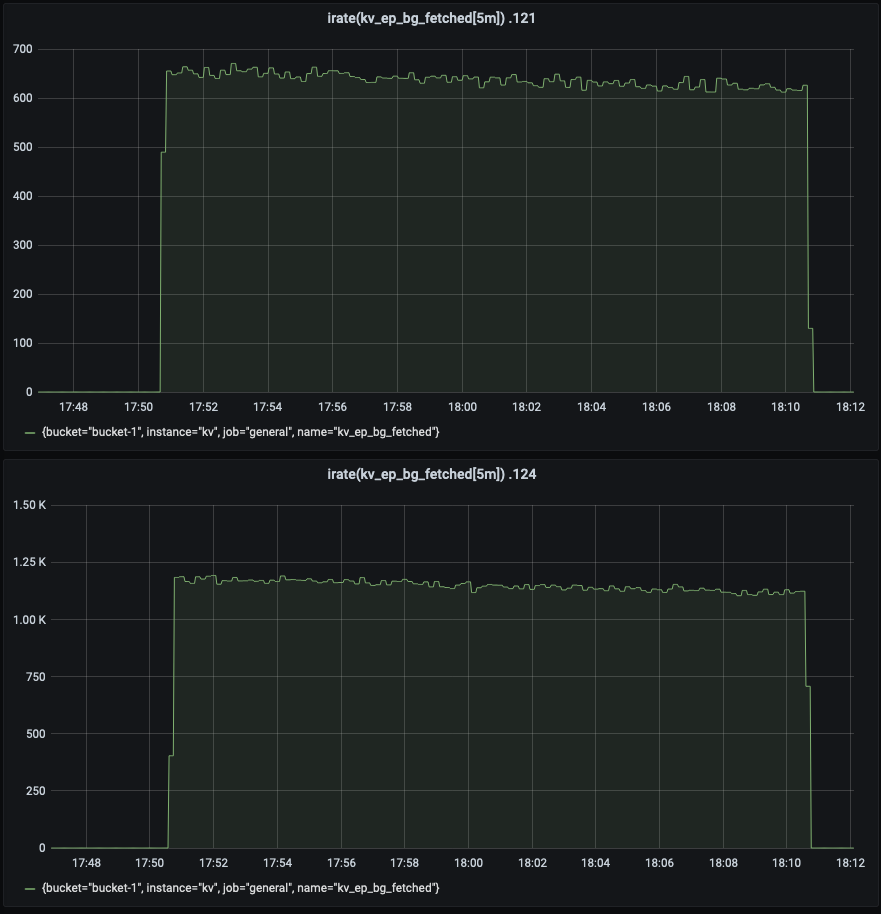
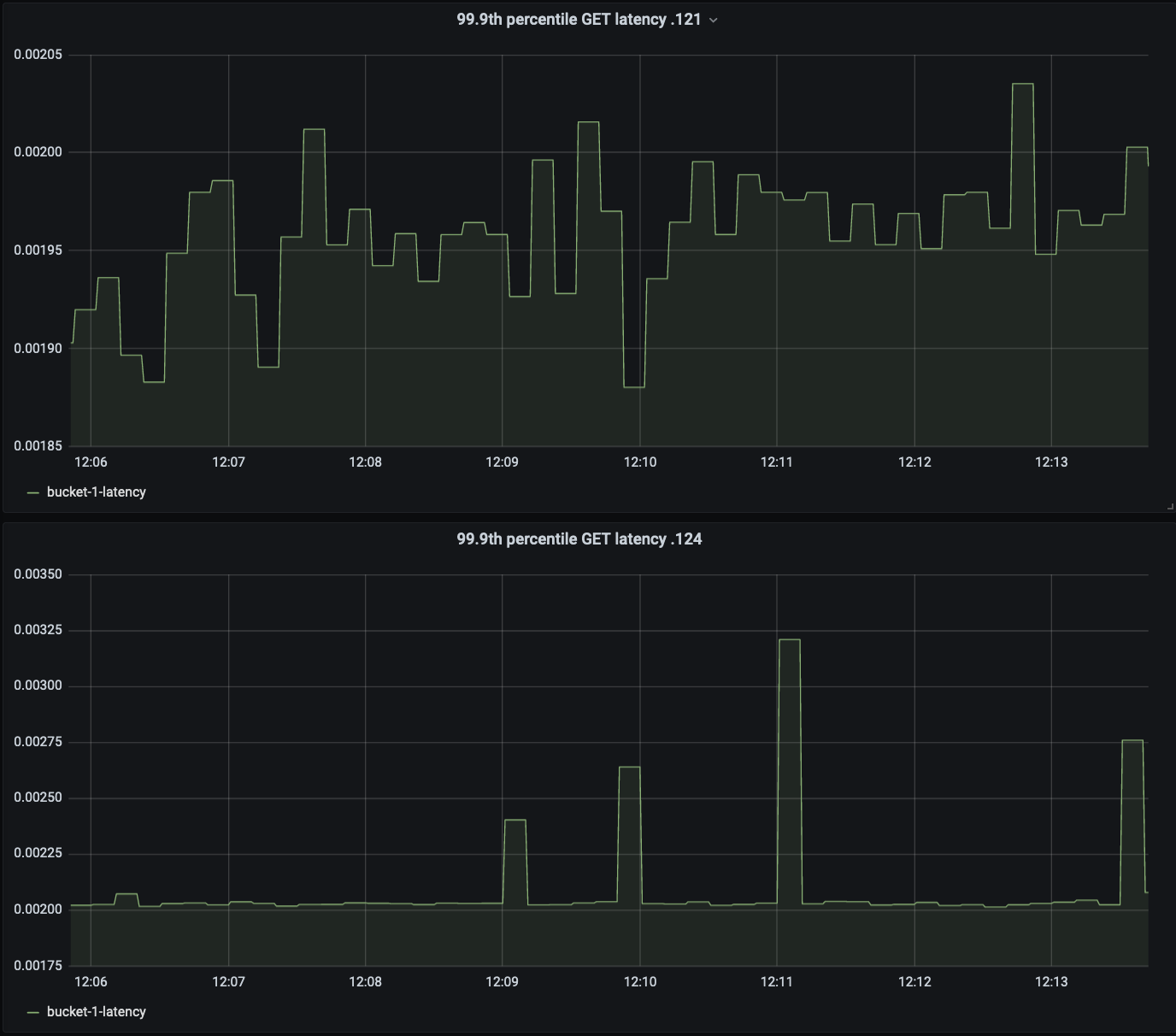
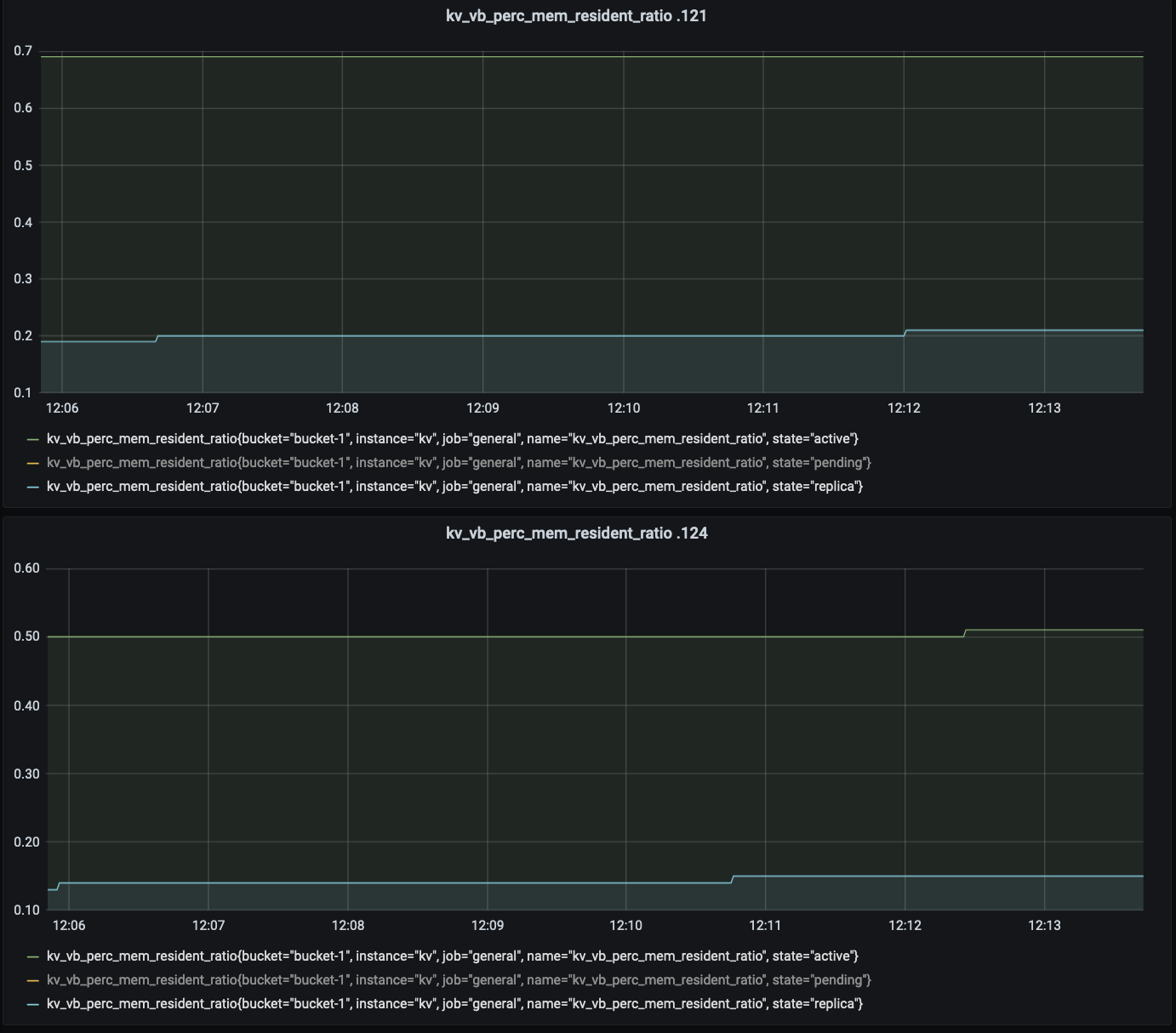
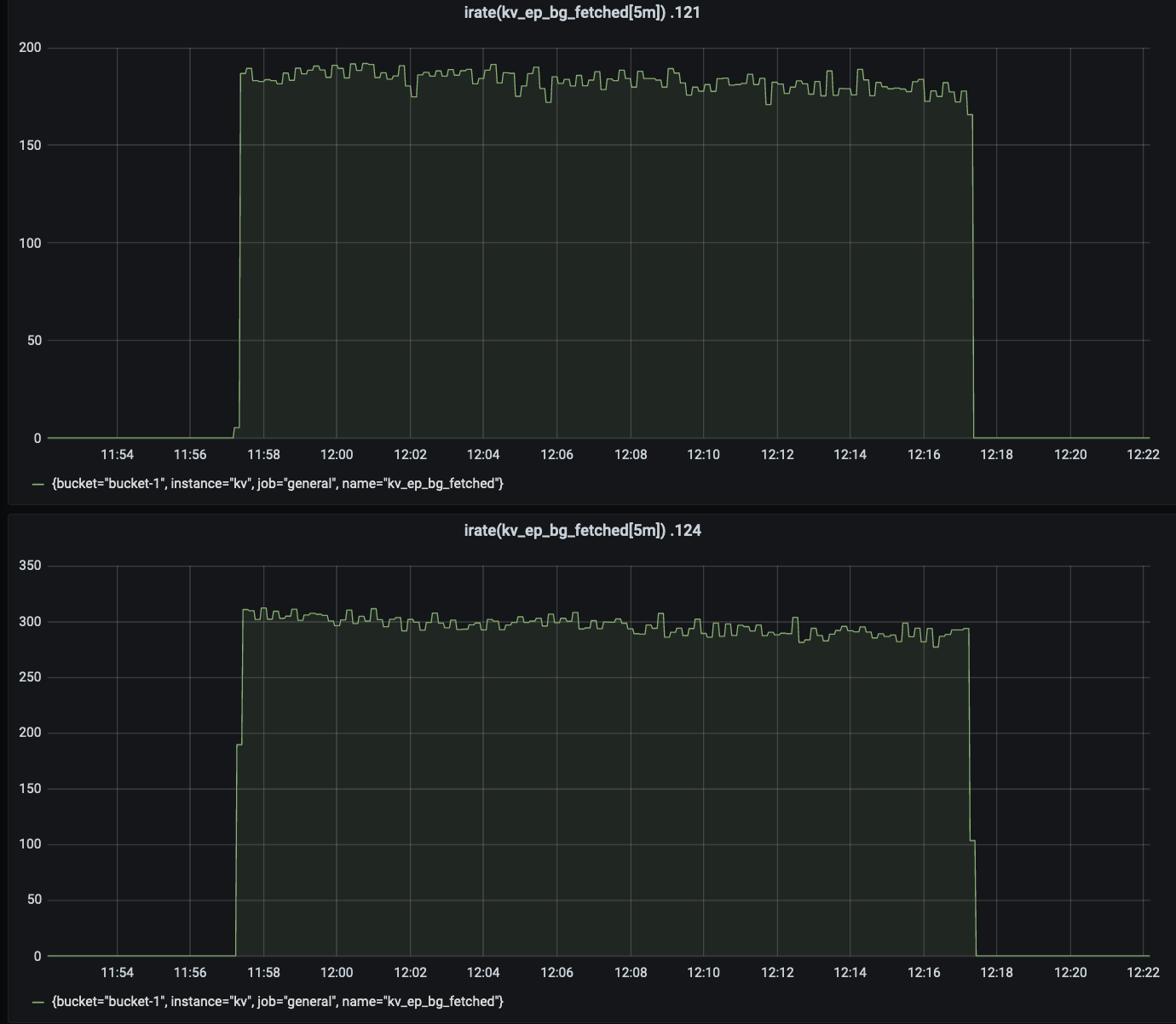
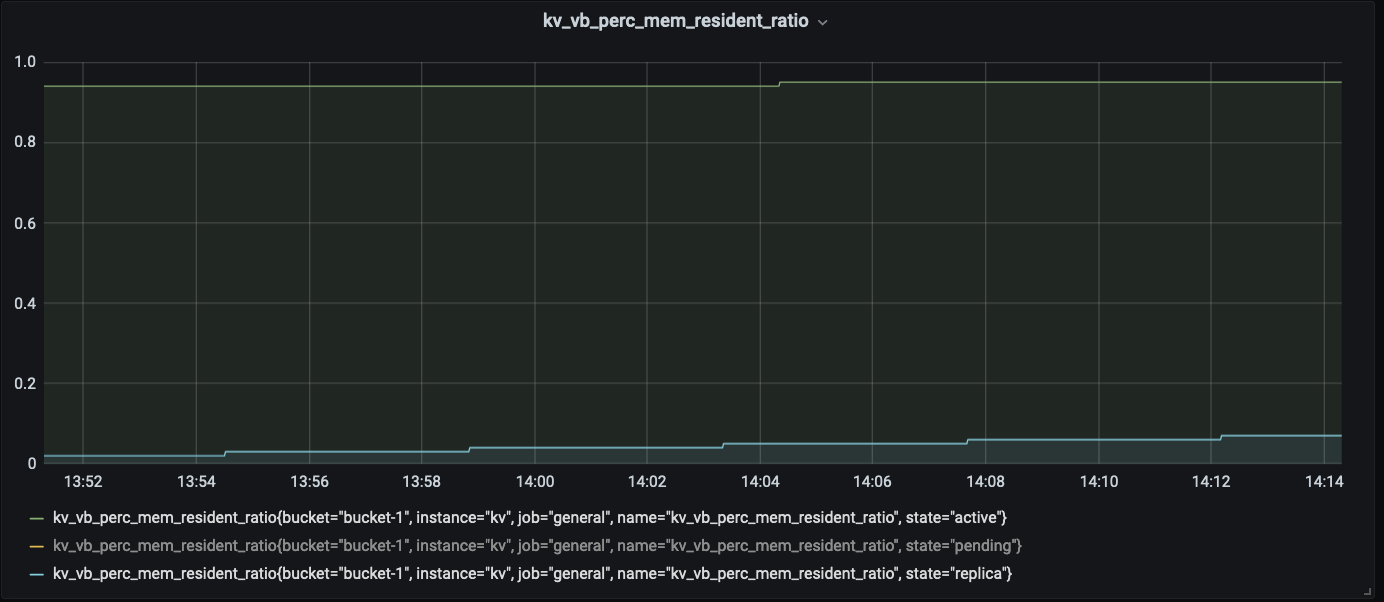
Compared to balanced server group, the 99.9th percentile read latency is increased by 30-40% in unbalance server group.
Read Heavy (80/20 Read/Update)
| Number of Nodes | Number of server groups | 99.9th percentile latency | Job |
|---|---|---|---|
| 6 | 2 (3 nodes + 3 nodes) | GET latency (ms): 0.95 SET latency (ms): 0.79 |
http://perf.jenkins.couchbase.com/job/hercules-dev/72/ |
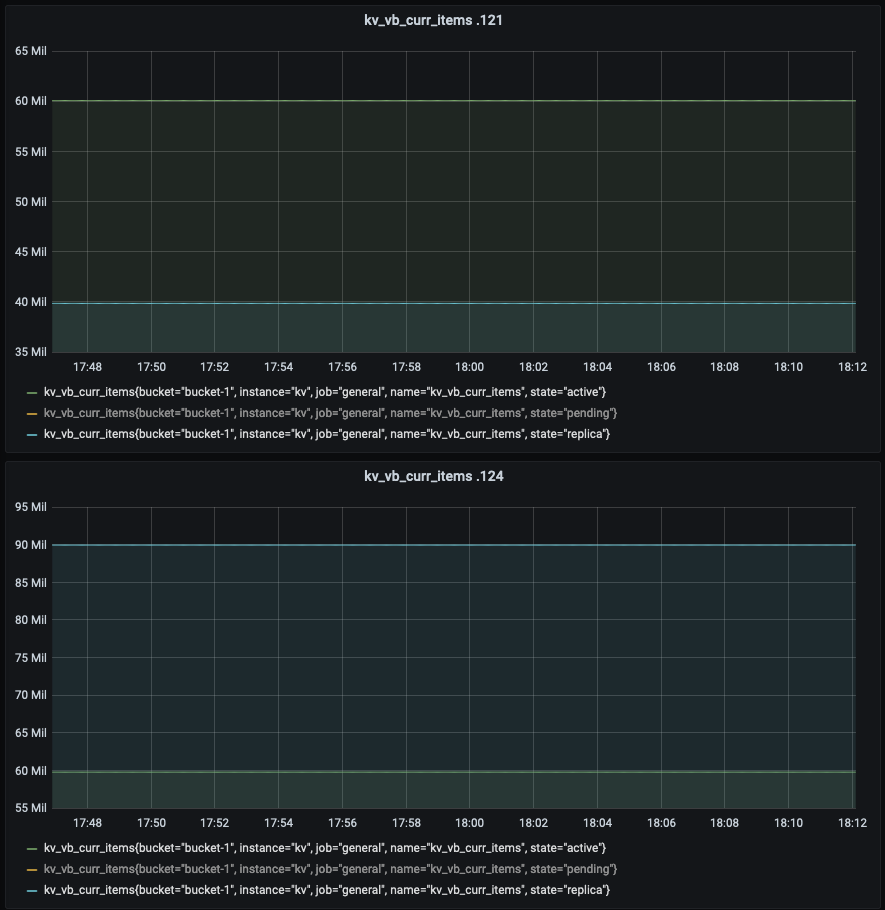
| 5 | 2 (3 nodes + 2 nodes) | GET latency (ms): 1.36 SET latency (ms): 0.66 |
http://perf.jenkins.couchbase.com/job/hercules-dev/71/ |
Write Heavy (20/80 Read/Update)
| Number of Nodes | Number of server groups | 99.9th percentile latency | Job |
|---|---|---|---|
| 6 | 2 (3 nodes + 3 nodes) | GET latency (ms): 1.45 SET latency (ms): 0.56 |
http://perf.jenkins.couchbase.com/job/hercules-dev/76/ |
| 5 | 2 (3 nodes + 2 nodes) | GET latency (ms): 1.85 SET latency (ms): 0.53 |
http://perf.jenkins.couchbase.com/job/hercules-dev/75/ |