Details
-
Improvement
-
Resolution: Unresolved
-
 Major
Major
-
7.1.0
-
None
Description
Background
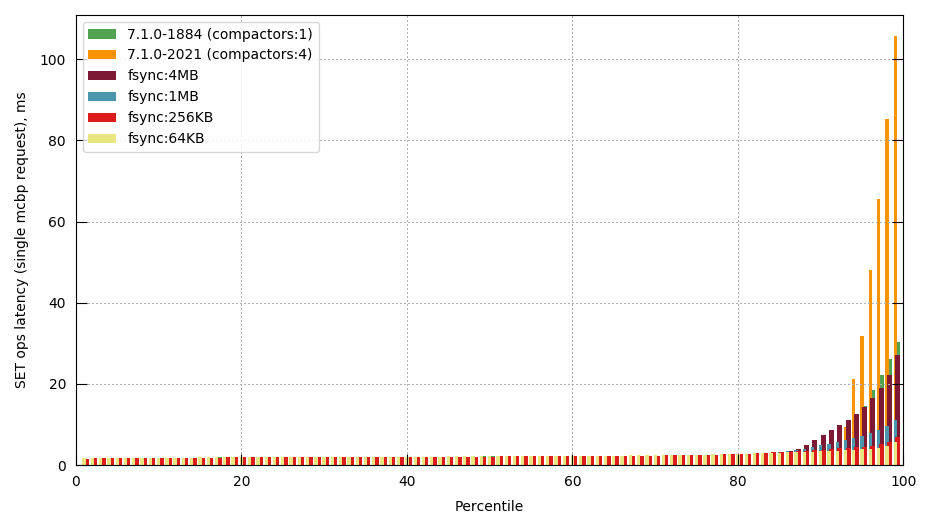
As seen in MB-50389, reducing the interval between periodic disk syncs during compaction has a significant improvement in tail latencies of disk write (and read) operations - in that MB reducing the interval from 16MB to 1MB resulted in a over a 7x reduction in p99.9 write latencies.
That MB also showed that even more frequent fsyncs (tested 256KB and 64KB) continued to improve tail latency, albeit at a smaller magnitude than compared with the 16MB -> 1MB change:
However, reducing sync interval to 256KB starts to have a non-negligible impact on compaction throughput - again from the same MB we saw the following runtimes to compact a given bucket at different sync intervals:
| sync interval | Compaction runtime (s) | Throughput vs 16MB |
|---|---|---|
| 16MB (default) | 88.2 | 1.0x |
| 1MB | 91.6 | 1.03x |
| 256 KB | 102.3 | 1.16x |
As such, current plan for MB-50389 is to reduce fsync down to 1MB, but no lower; to maintain compaction throughput.
fdatasync
Recall the main purpose of issuing periodic fdatasync is to avoid large amounts of modified buffer cache pages accumulating, and then eventually getting flushed to the medium at once, resulting in a large queue of outstanding requests and hence interferring with the (typically) smaller but latency sensitive reads/writes issued needed by front-end operations (BGFetches / SyncWrite flushes).
fdatasync achieves that, but not without a certain amount of overhead - datasync also performs the following operations which we don't actually need and can be costly:
- Blocks waiting for the the outstanding writes to be flushed from filesystem down to the disk
- Blocks waiting for the the disk's write cache to be flushed to the medium
- Blocks waiting for any relevant file metadata to be flushed to the medium
All we really want to do is to avoid the accumulation of modified buffer cache pages past some "reasonable" value so we see a "slow and steady" stream of writes to disk during compaction - enter file_sync_range...
file_sync_range
The Linux kernel supports an additional API to sync a file's state to disk - file_file_range man page. This allows more fine-grained control of how a file is flushed to disk, compared to the currently-used fdatasync:
- Only a subset of the file (offset + size) can be flushed
- Does not require the files's metadata is written to disk
- Does not requires the mediums's write cache is flushed.
- Specify whether the call is synchronous (blocking) or asynchronous (non-blocking)
(1) is of little interest to us given Couchstore always appends to files, however (2), (3) and (4) are of interest:
- We don't need metadata to be consistent until the entire file is written, doing it every 1MB (or less) is pointless
- We don't need the disk's write cache to be flushed (assuming the disk can handle having cached writes outstanding and still service other read/writes)
- We don't need to actually block waiting for modified pages to be written, we just want to initiate their write.
In theory we could recover some of the lost throughout from reducing the sync interval by using file_sync_range instead - the expectation being that if we can avoid the blocking wait on the sync, then we can pipeline userspace compacted file building and kernel-space writing of that data out; and hopefully can maintain similar compaction throughput as seen before.
We might even see better throughput (at the same sync interval), given we are not forcing writes down to the medium, and are letting the disk manage that itself; additionally we are not updating the filesystem metadata on every sync.
For reference, a number of other DBs are using file_sync_range in this manner - and both use a default of syncing every 1MB written:
- [RocksDB] Optionally wait on bytes_per_sync to smooth I/O - https://github.com/facebook/rocksdb/pull/5183
- [PostgreSQL] Increase distance between flush requests during bulk file copies - https://github.com/postgres/postgres/commit/643c27e36ff38f40d256c2a05b51a14ae2b26077 and checkpointer continuous flushing - https://www.postgresql.org/message-id/flat/alpine.DEB.2.10.1506011320000.28433@sto