Details
-
Bug
-
Resolution: Unresolved
-
 Critical
Critical
-
7.1.0
-
EE 7.1.0-2383
-
Untriaged
-
Centos 64-bit
-
-
1
-
Unknown
Description
Build: 7.1.0-2383
Scenario:
- 5 node cluster with all nodes running (kv, index, n1ql, fts) services
- Enable auto-failover with max_count=1, timeout=30
- Couchbase bucket with replicas=3
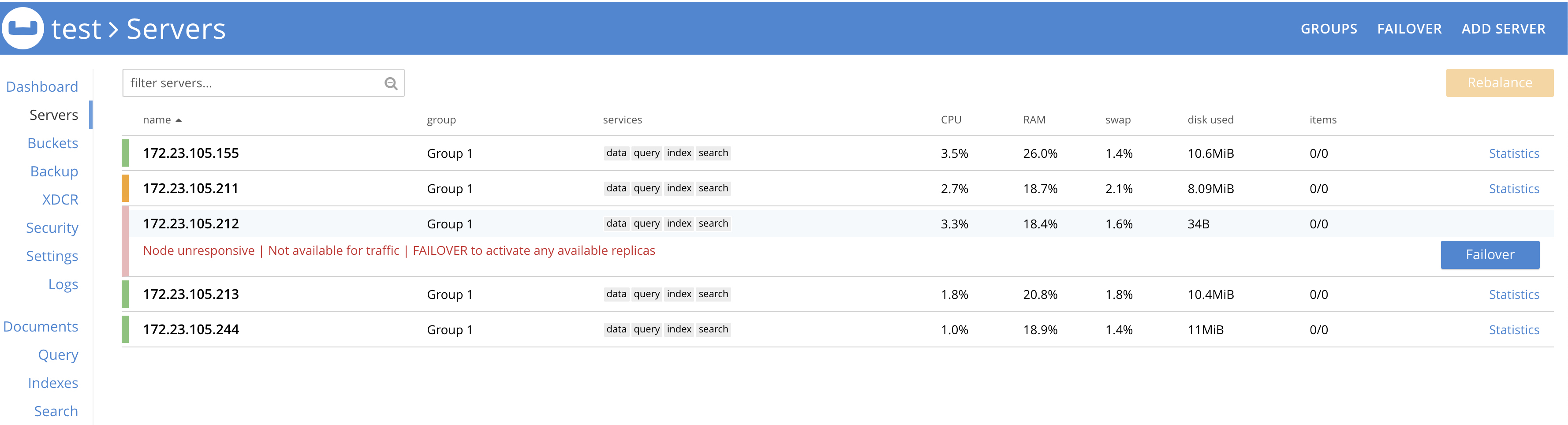
- Bring down two nodes .211 and .212 simultaneously
- Failover didn't happen (OK)
- Bring up one of the node (.211)
Observation:
Node .211 was stuck in warmup state.
Memcached came up but DCP streams were not established.
2022-02-25T07:41:26.144609-08:00 WARNING (default) Slow runtime for 'Warmup - key dump shard 0' on thread ReaderPool3: 10 ms
|
2022-02-25T07:41:26.146487-08:00 WARNING (default) Slow runtime for 'Warmup - key dump shard 2' on thread ReaderPool1: 12 ms
|
2022-02-25T07:41:26.156564-08:00 INFO (default) metadata loaded in 163 ms
|
2022-02-25T07:41:26.156581-08:00 INFO (default) Enough number of items loaded to enable traffic (value eviction): warmedUpValues(0) >= (warmedUpKeys(0) * warmupNumReadCap(1))
|
2022-02-25T07:41:26.156640-08:00 INFO (default) Access Scanner task enabled
|
2022-02-25T07:41:26.157024-08:00 INFO (default) Warmup completed: 0 keys and 0 values loaded in 163 ms (0 keys/s), mem_used now at 10.66124 MB (65.49618166041056 MB/s)
|
2022-02-25T07:41:26.391319-08:00 INFO 72: Client {"ip":"127.0.0.1","port":56906} authenticated as <ud>@ns_server</ud>
|
2022-02-25T07:41:26.391856-08:00 INFO 72: HELO [regular] [ {"ip":"127.0.0.1","port":56906} - {"ip":"127.0.0.1","port":11209} (System, <ud>@ns_server</ud>) ]
|
2022-02-25T07:41:26.451539-08:00 INFO 74: Client {"ip":"127.0.0.1","port":56908} authenticated as <ud>@ns_server</ud>
|
2022-02-25T07:41:26.452122-08:00 INFO 74: HELO [regular] [ {"ip":"127.0.0.1","port":56908} - {"ip":"127.0.0.1","port":11209} (System, <ud>@ns_server</ud>) ]
|
2022-02-25T07:41:26.455464-08:00 INFO TLS configuration changed to: {"CA file":"/opt/couchbase/var/lib/couchbase/config/certs/ca.pem","certificate chain":"/opt/couchbase/var/lib/couchbase/config/certs/chain.pem","cipher list":{"TLS 1.2":"HIGH","TLS 1.3":"TLS_AES_256_GCM_SHA384:TLS_AES_128_GCM_SHA256:TLS_CHACHA20_POLY1305_SHA256"},"cipher order":true,"client cert auth":"disabled","minimum version":"TLS 1.2","password":"not set","private key":"/opt/couchbase/var/lib/couchbase/config/certs/pkey.pem"}
|
Expected behavior:
After .211 coming up it should turn green and go-ahead to failover the other node .212
Attachments
Gerrit Reviews
| For Gerrit Dashboard: MB-51219 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 187957,15 | test_MB_51219 | master | TAF | Status: NEW | 0 | +1 |