Details
-
Task
-
Resolution: Unresolved
-
 Major
Major
-
7.1.0
-
None
-
1
Description
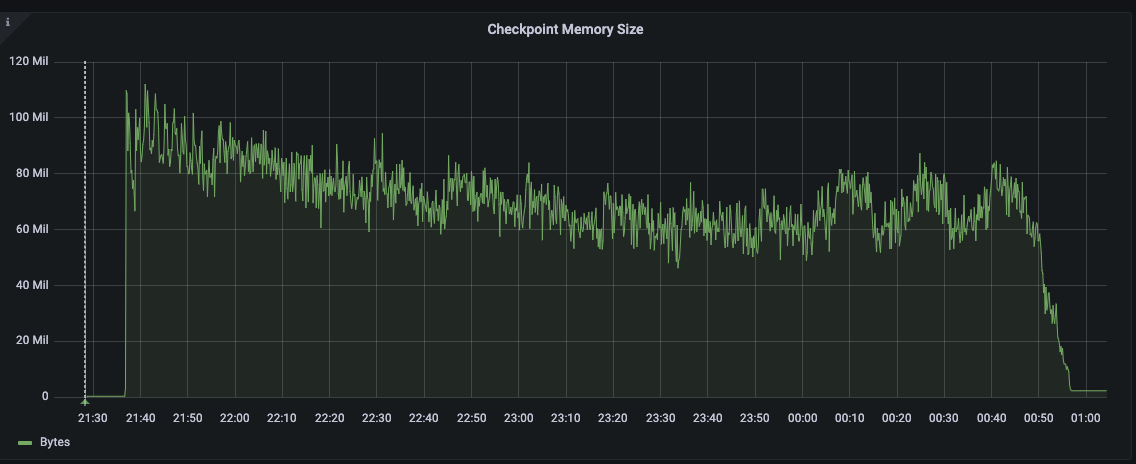
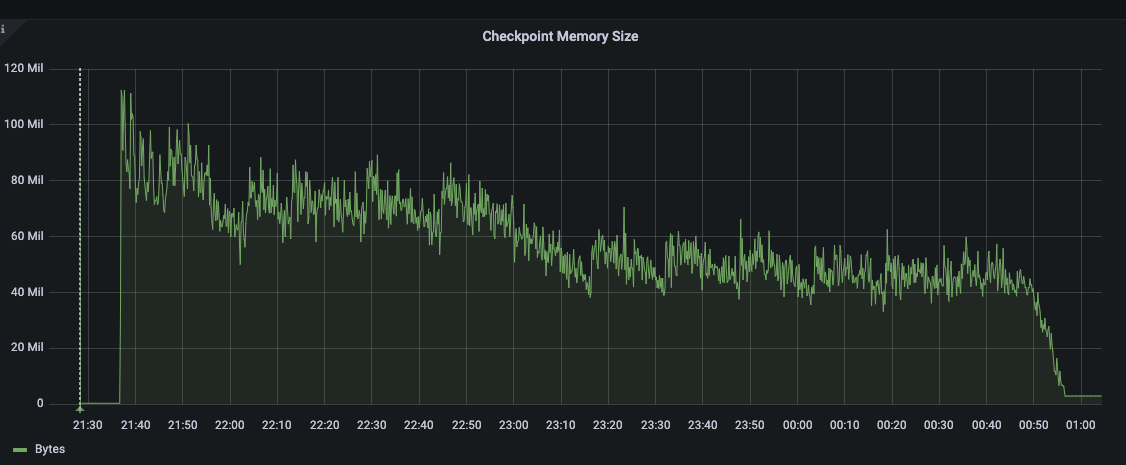
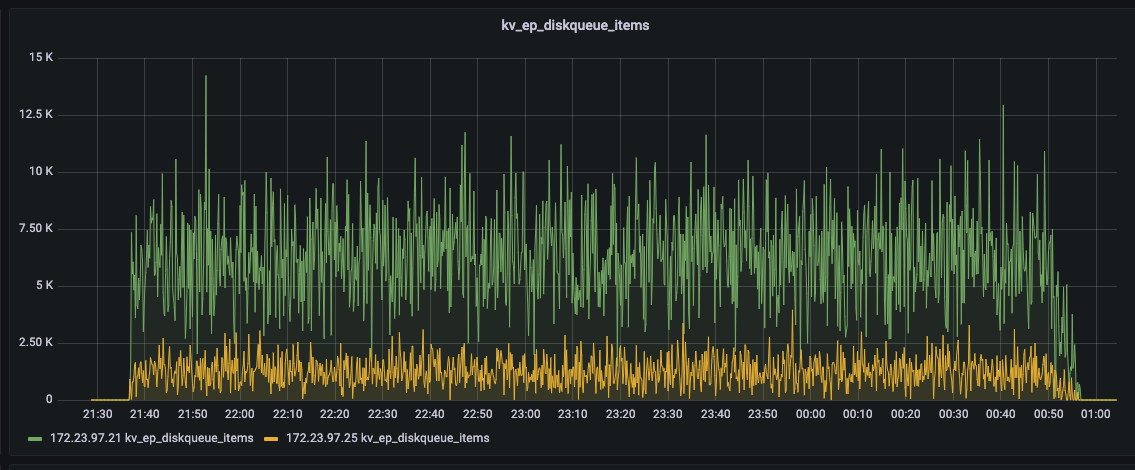
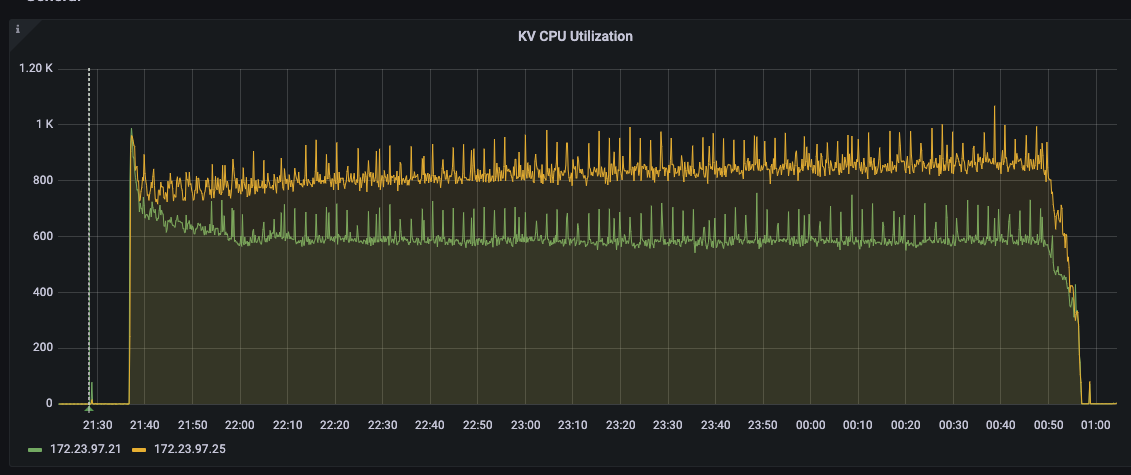
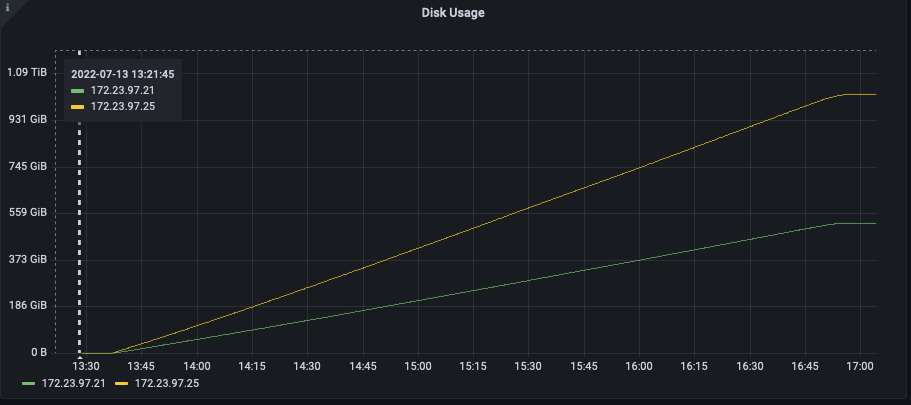
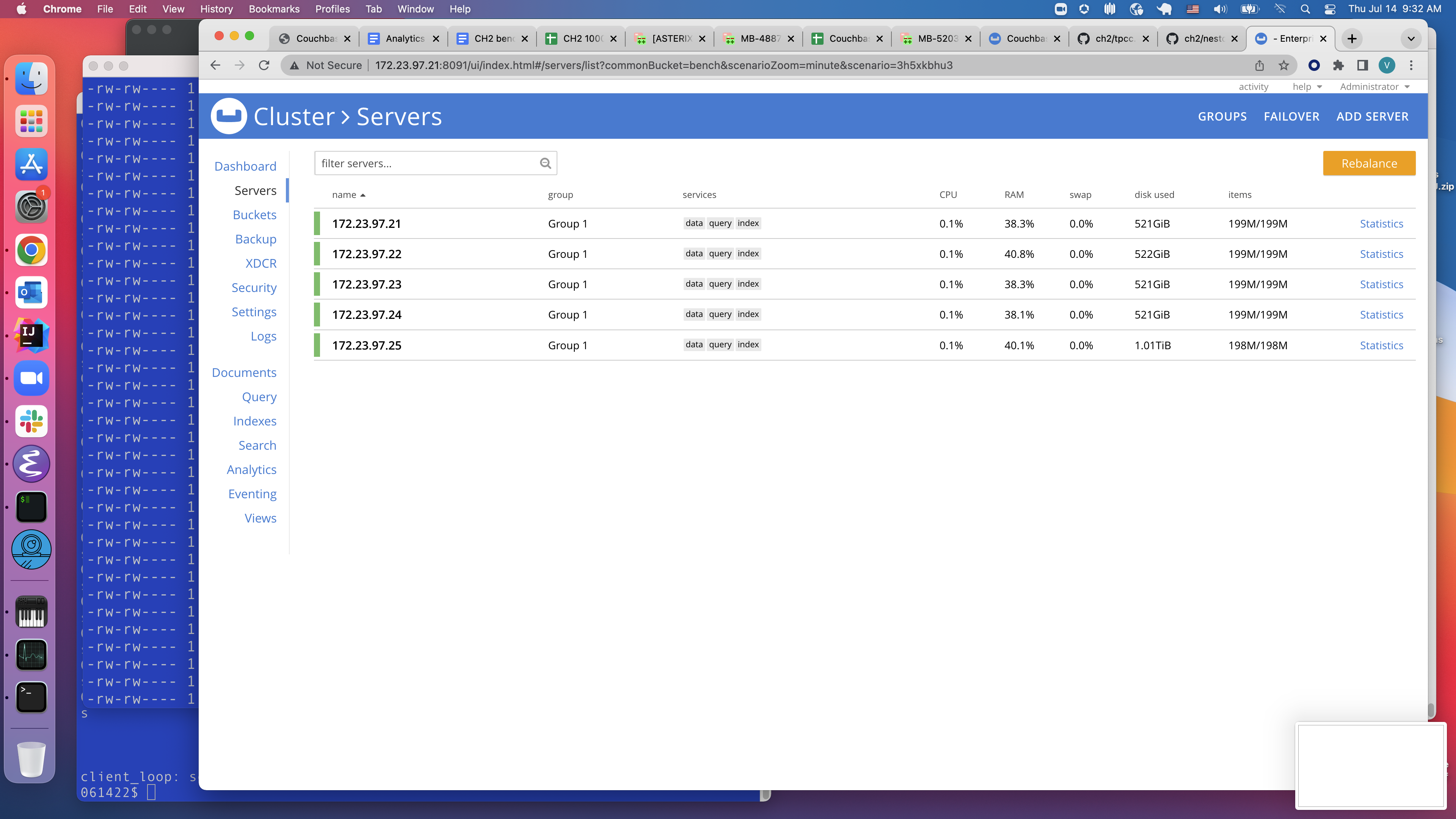
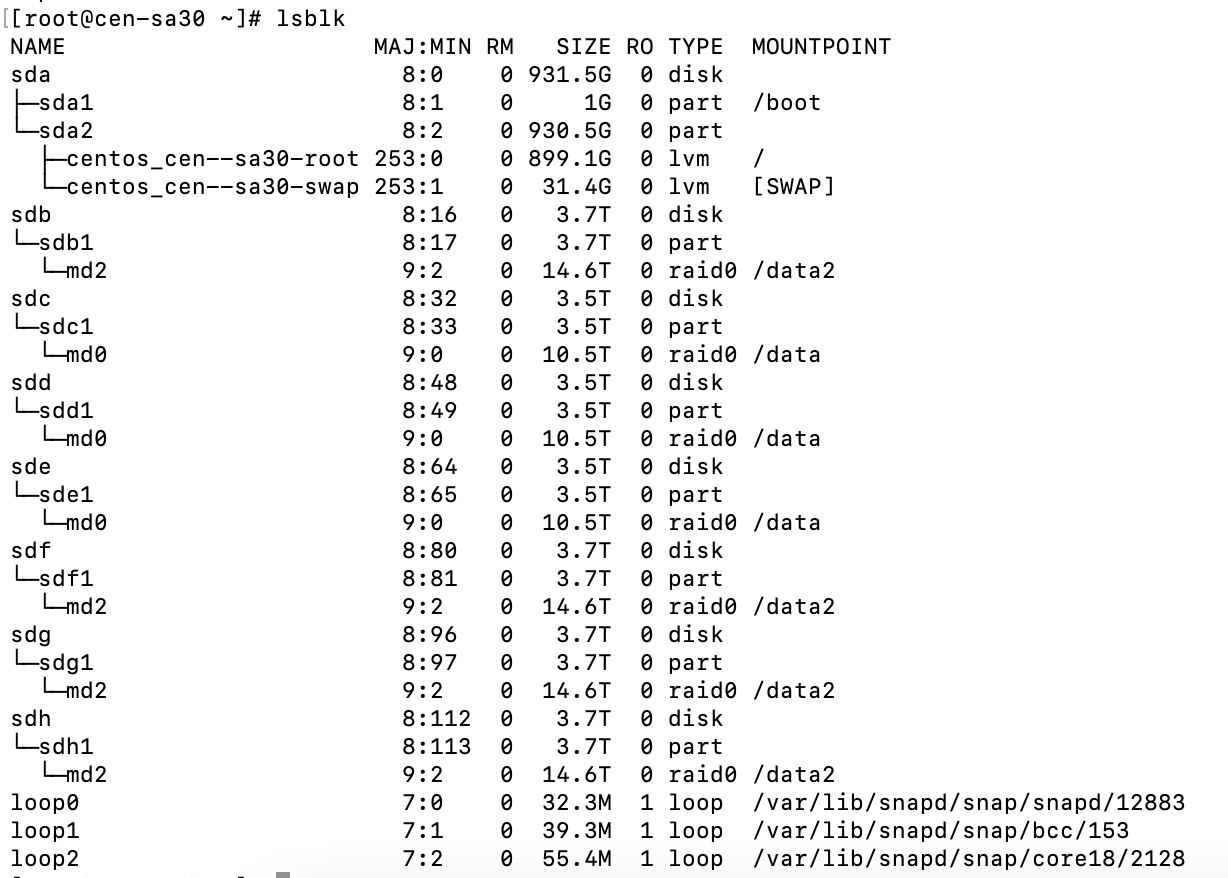
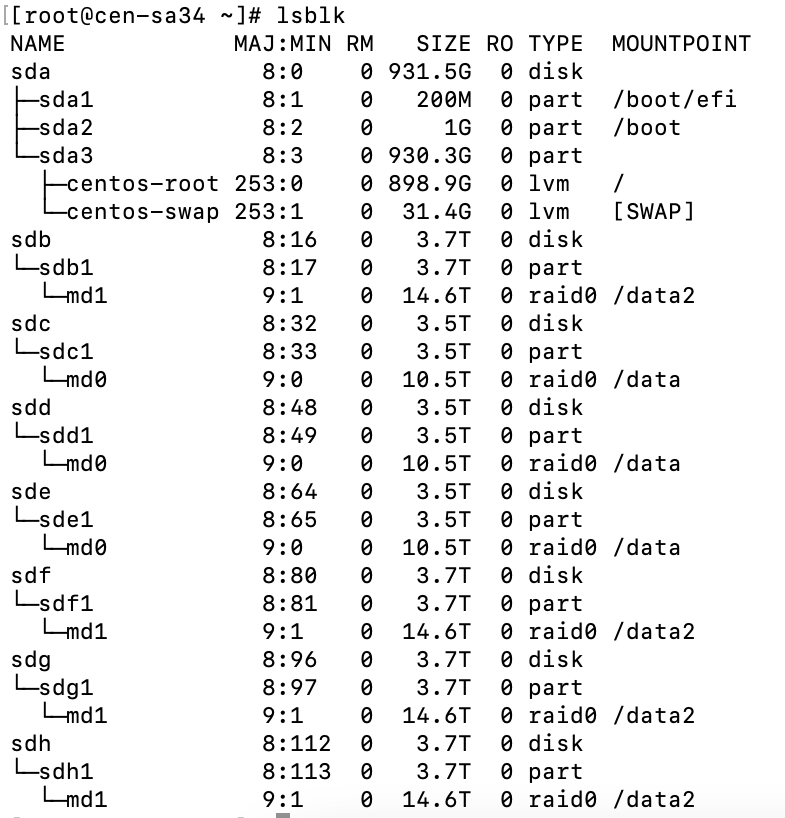
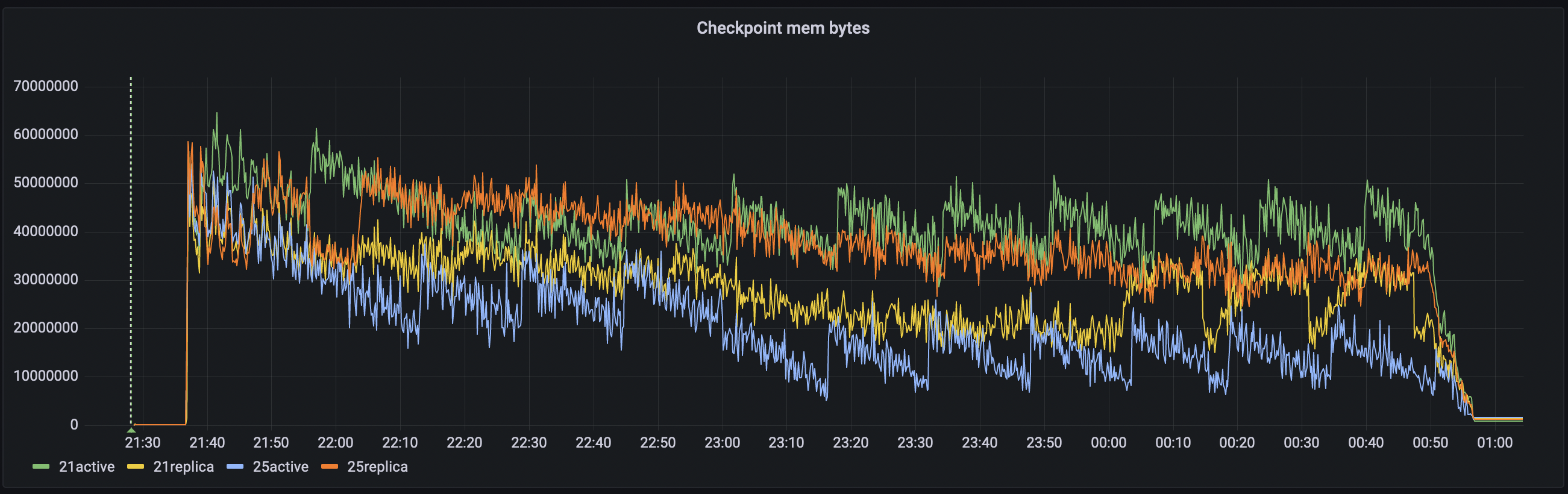
I am using the python SDK 4.0.2 to bulk load data directly into KV using the upsert_multi() API. I am loading 5000 warehouses of ch2 (tpcc based) data into a five data node cluster. 5000w is approximately 500GB of data, with one replica it is about 1TB. What we are seeing is that one node has consistently higher disk usage than the other four nodes (see attached screenshot).
Also, when I look at the UI metrics, the bucket shows about 3.05TB of disk utilization, but the scope shows 493GB (this seems correct for 0 replicas) of disk utilization. How are these numbers reported, and how do I interpret them? The bucket has only one scope.
This is on Enterprise Edition 7.1.0 build 2556.
Server node: 172.23.97.21
Cluster logs are here:
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2022-07-13T235935-ns_1%40172.23.97.21.zip
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2022-07-13T235935-ns_1%40172.23.97.22.zip
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2022-07-13T235935-ns_1%40172.23.97.23.zip
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2022-07-13T235935-ns_1%40172.23.97.24.zip
https://s3.amazonaws.com/bugdb/jira/qe/collectinfo-2022-07-13T235935-ns_1%40172.23.97.25.zip