Details
-
Bug
-
Resolution: Not a Bug
-
 Critical
Critical
-
6.6.2
-
None
-
Untriaged
-
1
-
Unknown
Description
Steps to reproduce:
- Create 4 buckets
- Create indexes with replicas on each of the 4 buckets.
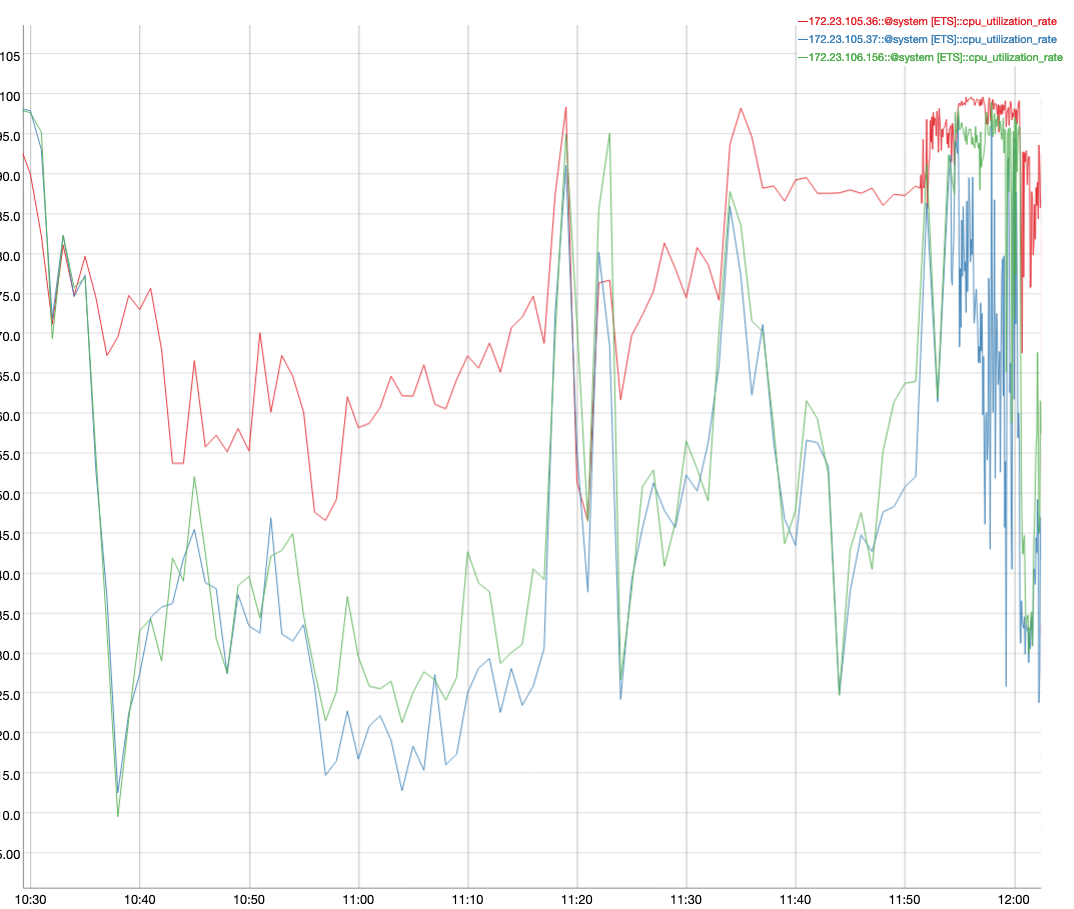
- Run pillowfight to continuously load data ((buckets have 1M, 1M , 1M and 3M items). The bucket RR needs to be under 10%. Load until then
- Run a shell script that runs the request_plus scans continuously.
- Run stress-ng with the params -> stress-ng --vm 4 --vm-bytes 1G --metrics-brief --vm-keep --vm-locked -m 4 --aggressive --vm-populate. (Adjust the --vm-bytes param depending upon the VM resources)
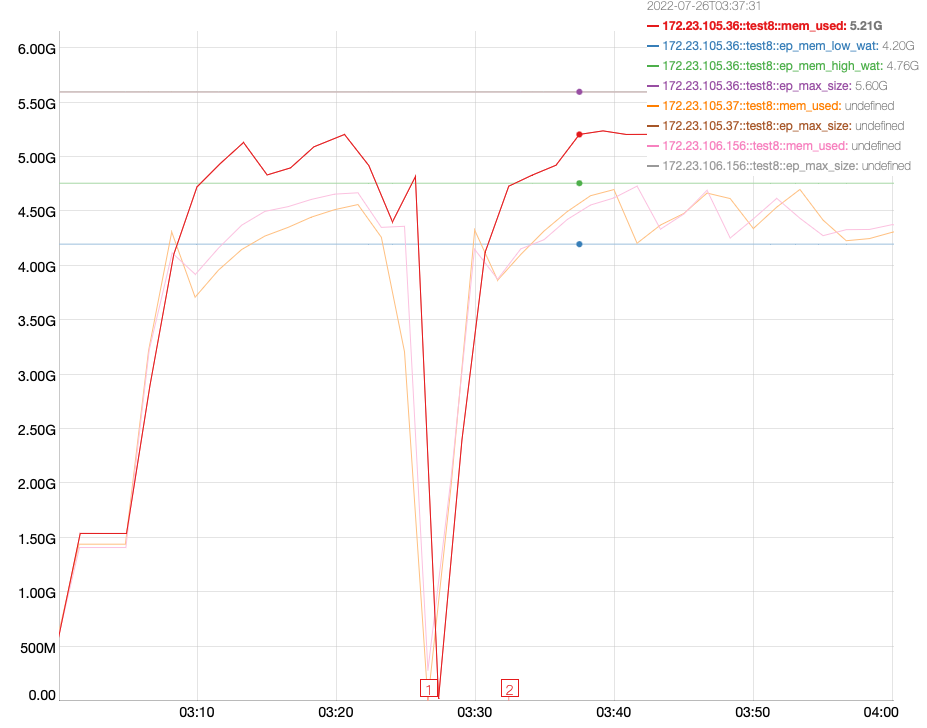
- Once you run enough stress-ng processes, OOM kill will kick in. This can be verified by checking the dmesg ( dmesg -T | egrep -i 'killed process' )
- There's a possibility that stress-ng gets spawned and killed since OOM kill is determined by a oom_score_adj factor. In order to make sure that memcached gets killed run this
echo 1000 > /proc/<memcached PID>/oom_score_adj |
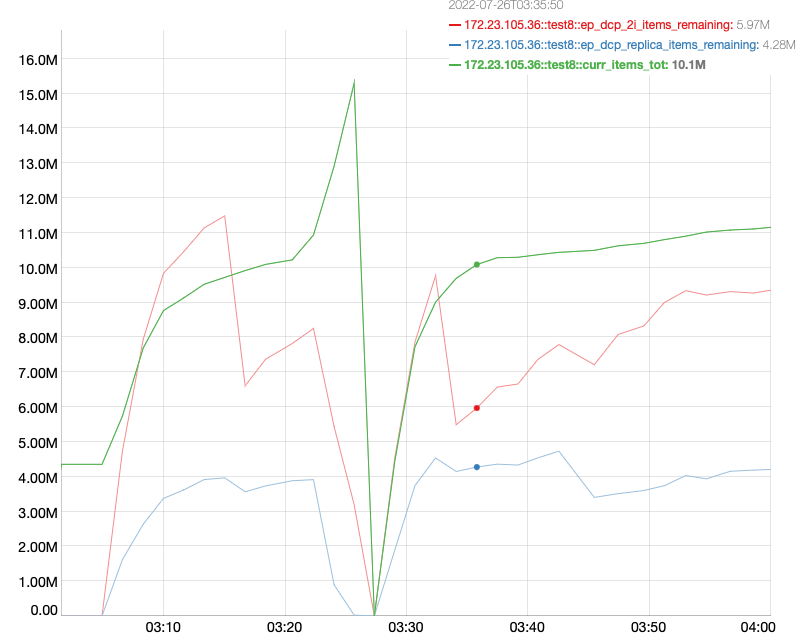
- Observe that the scans are timing out and that the index has rolled back to 0.
Logs and pcaps are attached. There were 2 instances of rollbacks observed. Please use these timestamps for analysis
Instance 1
Index node1 ( 172.23.106.159) |
2022-07-26T03:26:54.738-07:00 [Info] StorageMgr::rollbackAllToZero MAINT_STREAM test8 |
|
|
Index node2 ( 172.23.106.163) |
|
|
2022-07-26T03:26:58.186-07:00 [Info] StorageMgr::rollbackAllToZero MAINT_STREAM test8 |
Instance 2
Index node1 ( 172.23.106.159) |
|
|
2022-07-26T05:06:12.658-07:00 [Info] StorageMgr::rollbackAllToZero MAINT_STREAM test8 |
|
|
Index node2 ( 172.23.106.163) |
|
|
2022-07-26T05:06:10.805-07:00 [Info] StorageMgr::rollbackAllToZero MAINT_STREAM test8 |
Log bundles ->
s3://cb-customers-secure/cbse12279oomkil2/2022-07-26/collectinfo-2022-07-26t125548-ns_1@172.23.105.36.zip |
s3://cb-customers-secure/cbse12279oomkil2/2022-07-26/collectinfo-2022-07-26t125548-ns_1@172.23.105.37.zip |
s3://cb-customers-secure/cbse12279oomkil2/2022-07-26/collectinfo-2022-07-26t125548-ns_1@172.23.106.156.zip |
s3://cb-customers-secure/cbse12279oomkil2/2022-07-26/collectinfo-2022-07-26t125548-ns_1@172.23.106.159.zip |
s3://cb-customers-secure/cbse12279oomkil2/2022-07-26/collectinfo-2022-07-26t125548-ns_1@172.23.106.163.zip |
s3://cb-customers-secure/cbse12279oomkil2/2022-07-26/collectinfo-2022-07-26t125548-ns_1@172.23.106.204.zip |
I have the packet capture files too and can attach them if necessary.