Details
Description
Setup
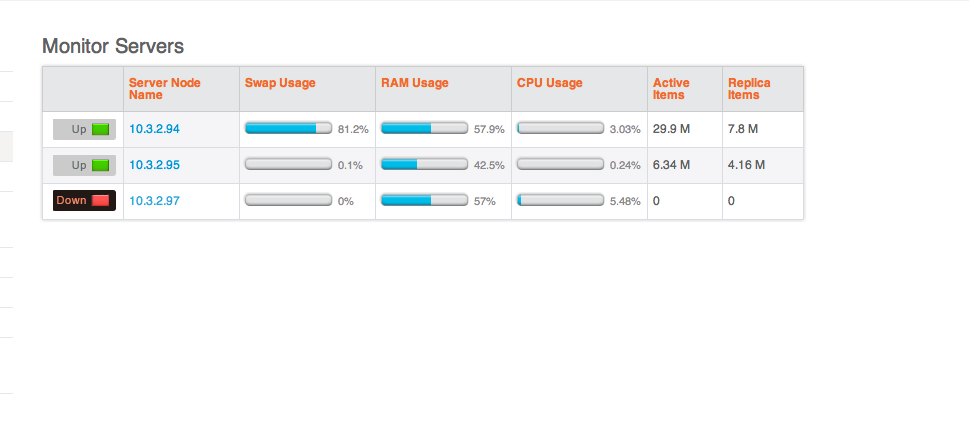
1.Cluster(nodes 94, 95) has 25.1M items per bucket.
2. Mutate items with much large value, causing fragmentation.
3. Node 94 is in heavy swap - 84%.
4. Resident ratio on node 95 has dropped to < 1 percent.
5. Restart node 95.
6. Issue rebalance - add node 97.
7. Stop rebalance
Seeing the following output messages
Port server moxi on node 'ns_1@10.3.2.97' exited with status 137. Restarting. Messages: 2012-06-20 16:12:14: (cproxy_config.c.317) env: MOXI_SASL_PLAIN_USR (13)
2012-06-20 16:12:14: (cproxy_config.c.326) env: MOXI_SASL_PLAIN_PWD (8)
Port server memcached on node 'ns_1@10.3.2.97' exited with status 137. Restarting. Messages: TAP (Producer) eq_tapq:rebalance_483 - Clear the tap queues by force
On re-issuing rebalance, with remove node94. Rebalance fails with
Rebalance exited with reason
{wait_for_memcached_failed,"bucket2", ['ns_1@10.3.2.97']}Attaching the logs from all the nodes https://s3.amazonaws.com/bugdb/jira/bug-cluster-swap/bug.tar
Attached the current screenshot
The live cluster can be accessed at http://10.3.2.94:8091/index.html#sec=log&serversTab=0
Attachments
| For Gerrit Dashboard: MB-5630 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 17620,3 | MB-5630 Notify change_vb_filter completion to the client side. | master | ep-engine | Status: MERGED | +2 | +1 |