Details
Description
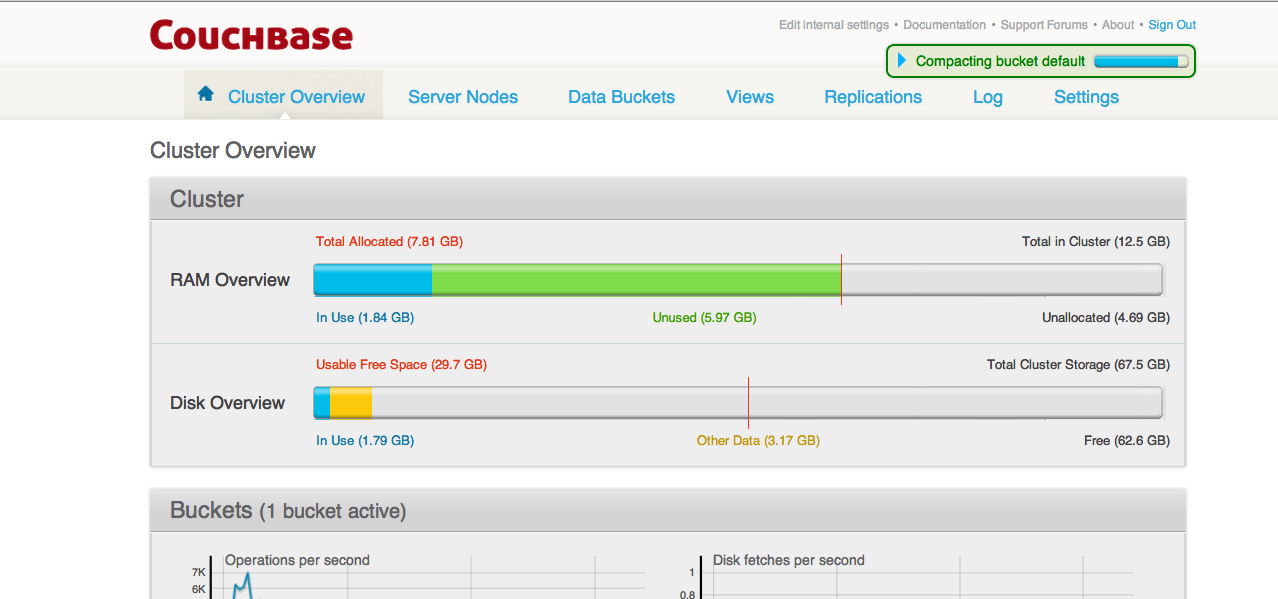
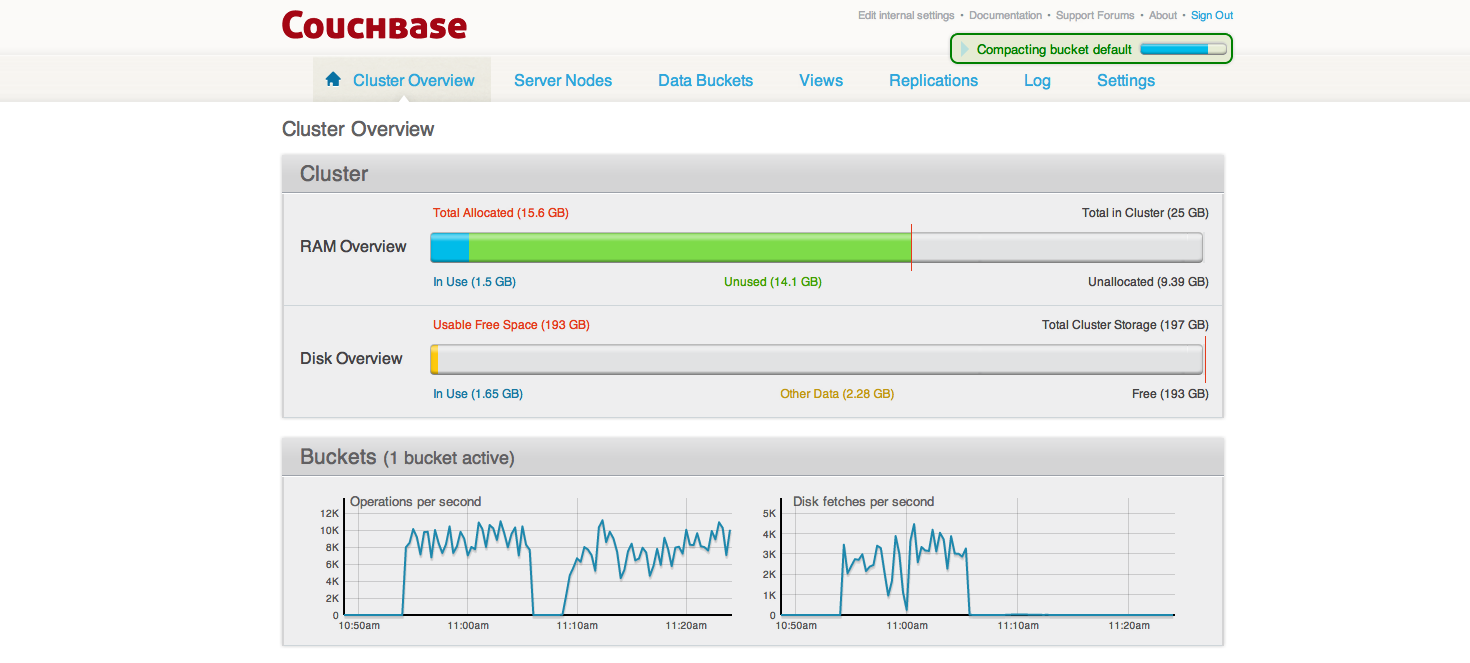
There is almost continuous compaction happening on source/ destination clusters during xdcr replication.
-Loaded 2M data on source, this data is being replicated to the destination cluster.
-Compaction setting is set to 30% database fragmenation [default setting]
Not sure why it is triggered atleast 5-6 times and almost ongoing continuously on source/destination clusters.
Are there any other stats/memory that I should check for this?
- Every time compaction kicks in, stats on destination become choppy and replication becomes slower, due to resource contention.
- XDCR by iteself has very high CPU utilization ~90% on source.
Screenshots of cluster overview on source and destination.