Details
-
Bug
-
Resolution: Cannot Reproduce
-
 Critical
Critical
-
2.0-beta-2
-
Security Level: Public
-
2.0.0-1721-rel
Centos 4G RAM 64-bit machines
1024 vbuckets
Description
- Created default buckets on a 2:2 cluster
[10.1.3.235, 10.1.3.236] : [10.1.3.237, 10.1.3.238] - Set up bidirectional replication for the bucket, ran load on both the buckets.
- Swap rebalanced a node on both clusters
[10.1.3.235, 10.3.2.54] : [10.1.3.237, 10.3.2.55] - Upon completion of rebalance, stopped load on default buckets.
- Created standard buckets on both the clusters.
- Set up unidirectional replication for the standard bucket from cluster 1 to cluster 2, ran load on cluster 1.
- Stopped load after a point.
- With replication still going on, Rebalance-in the removed nodes on each cluster (to make it 3:3)
[10.1.3.235, 10.3.2.54, 10.1.3.236] : [10.1.3.237, 10.3.2.55, 10.1.3.238] - During rebalance, load is not going on on either cluster, however replication is still going on.
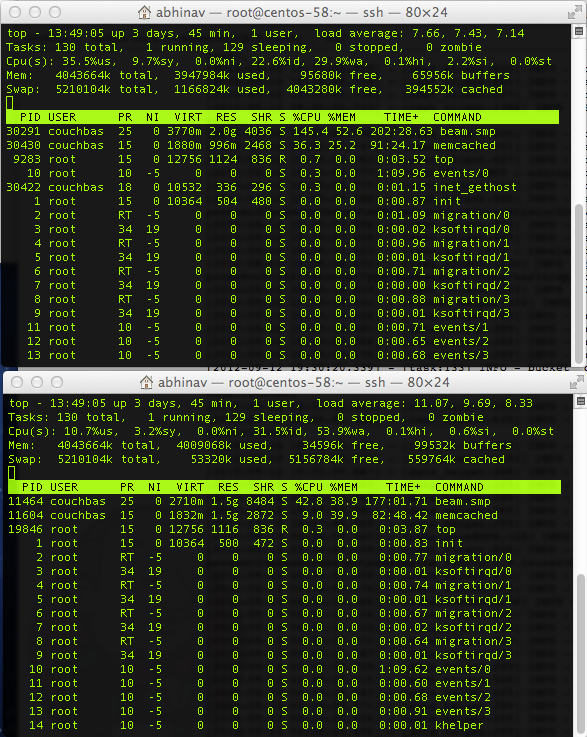
- Heavy swap on the orchestrators of both the clusters
- Erlang using up a lot of memory ( > 2.5G )
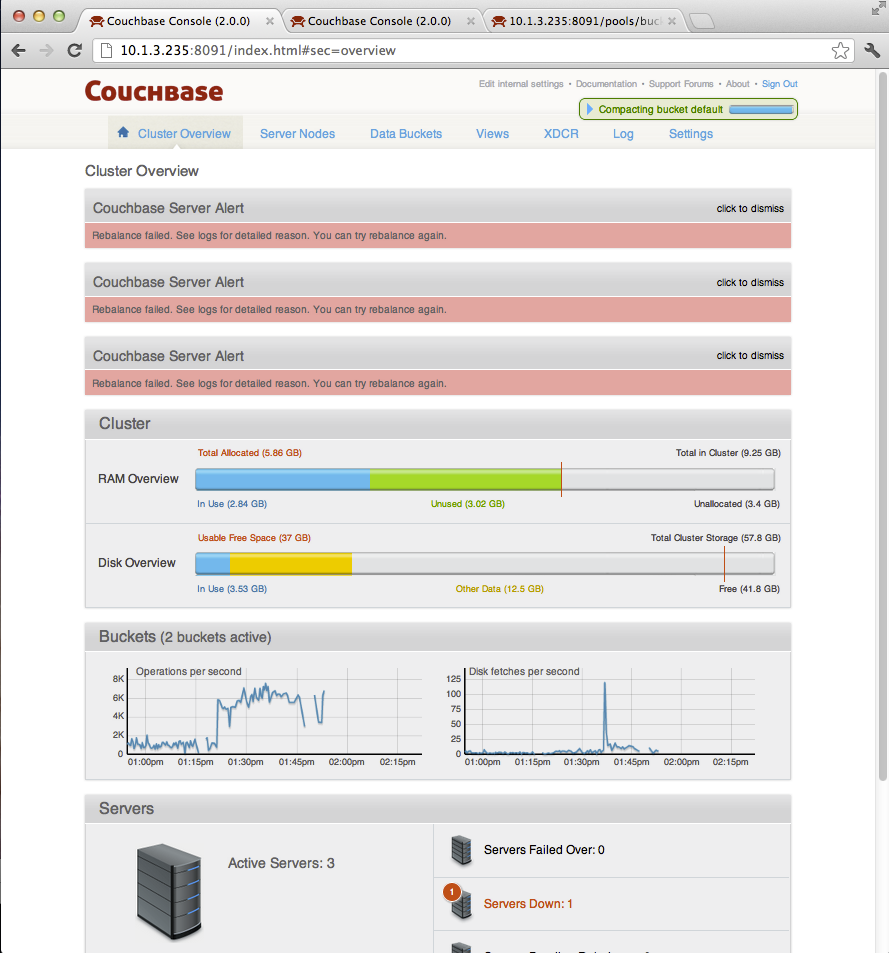
- Rebalance gradually completed on cluster 2.
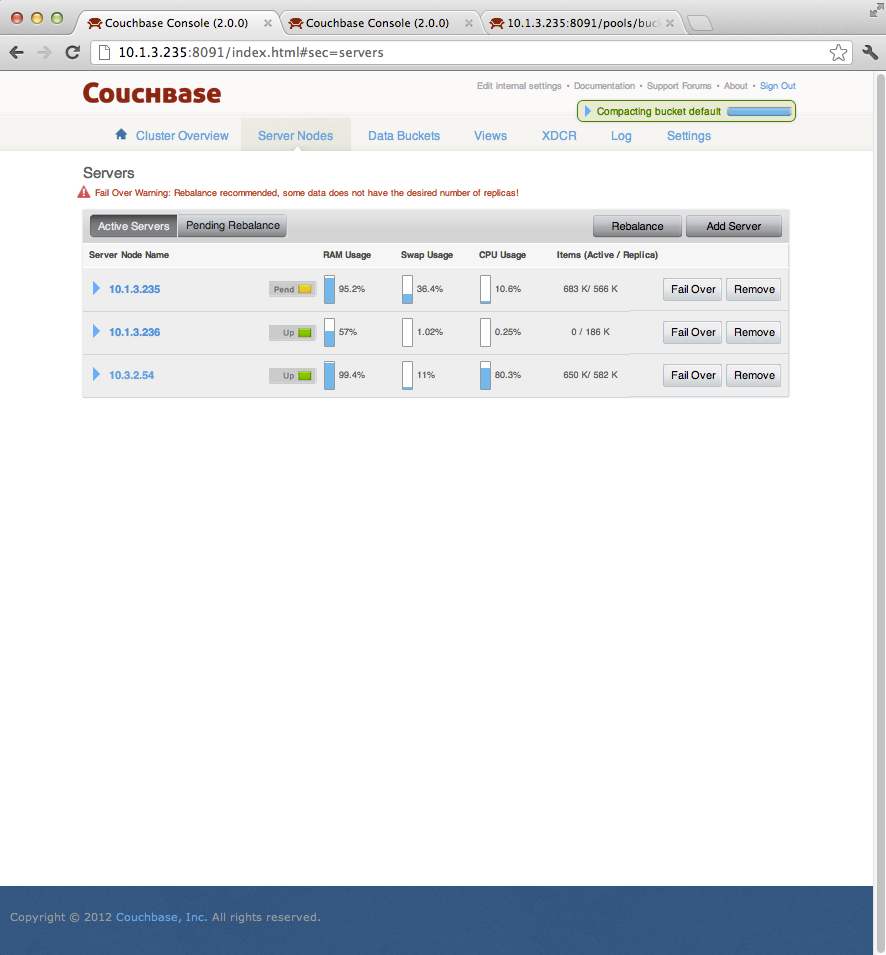
- Rebalance fails on cluster 1:
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Rebalance exited with reason badmatch,{error,timeout,Unknown macro: {gen_server,call,[{'ns_memcached-bucket','ns_1@10.1.3.235'},{get_vbucket,835},60000]}}
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- If tried to re-rebalance, rebalance fails again:
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Rebalance exited with reason {not_all_nodes_are_ready_yet,['ns_1@10.1.3.235']} - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- This is probably because, 10.1.3.235 is in "PEND" state on the UI.
- Uploading grabbed diags onto s3.
https://s3.amazonaws.com/bugdb/MB-6649/10.1.3.235-8091-diag.txt.gz
https://s3.amazonaws.com/bugdb/MB-6649/10.1.3.236-8091-diag.txt.gz
https://s3.amazonaws.com/bugdb/MB-6649/10.3.2.54-8091-diag.txt.gz
https://s3.amazonaws.com/bugdb/MB-6649/10.1.3.237-8091-diag.txt.gz
https://s3.amazonaws.com/bugdb/MB-6649/10.1.3.238-8091-diag.txt.gz
https://s3.amazonaws.com/bugdb/MB-6649/10.3.2.55-8091-diag.txt.gz