Details
Description
Cluster set up:
c1 : c2 :: 10 : 10
sbucket: c1 -> c2
default: c2 -> c1
>> Replication set up with continuous front end load
>> Front end load for default = ~10K ops per sec
>> Front end load for sbucket = ~4-5K ops per sec
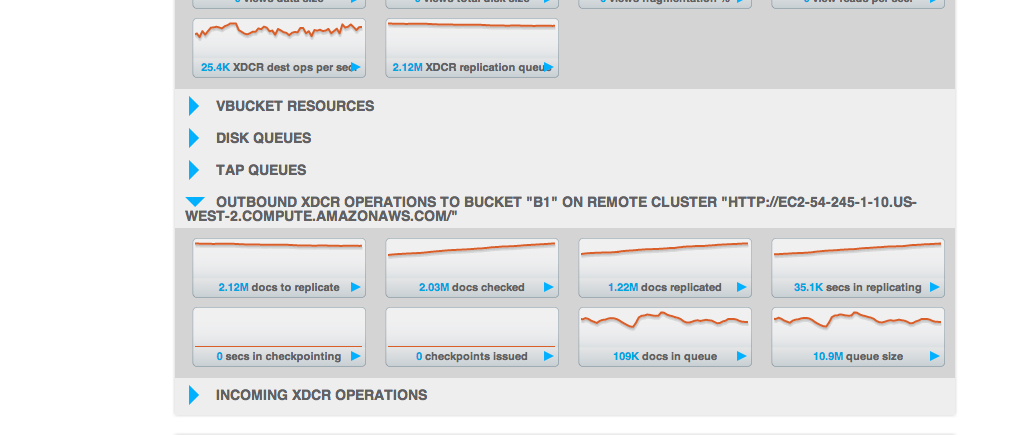
>> Average replication seen on c1 (for default): ~12-14K ops per sec
>> Average replication seen on c2 (for sbucket): ~15-18K ops per sec
At a particular snapshot, on C1:
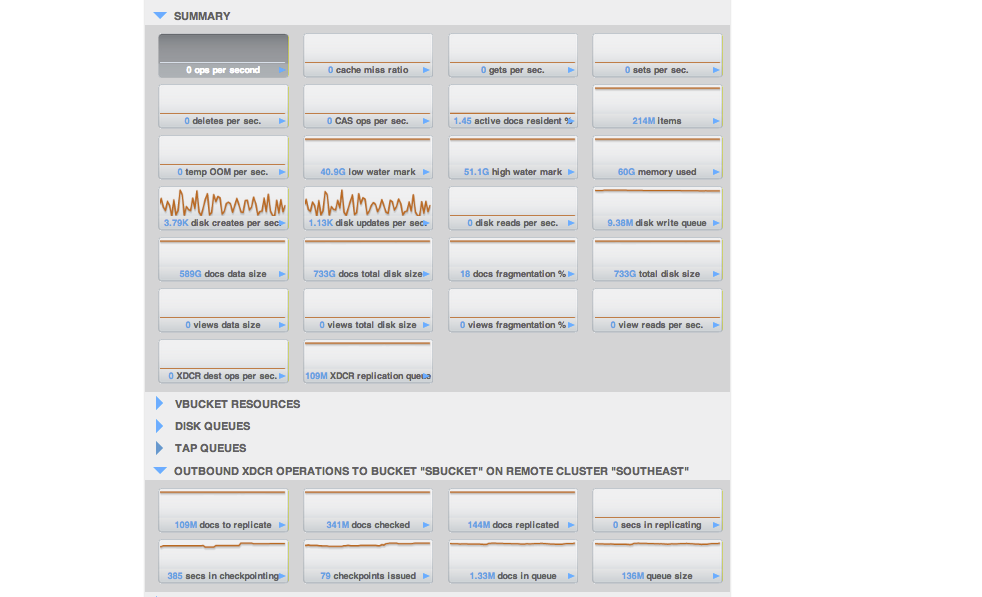
{With same amount of load (mixed), on bucket "sbucket"}No. of items: 214M
No. of items in replication queue: 136M (way too high)
Secs in replicating = 0 (!?)
Secs in checkpointing = 385 (!?)
Checkpoints issued = 79 (!?)
These stats being for a cluster that's been up running with continuous load and replication for ~65hrs.
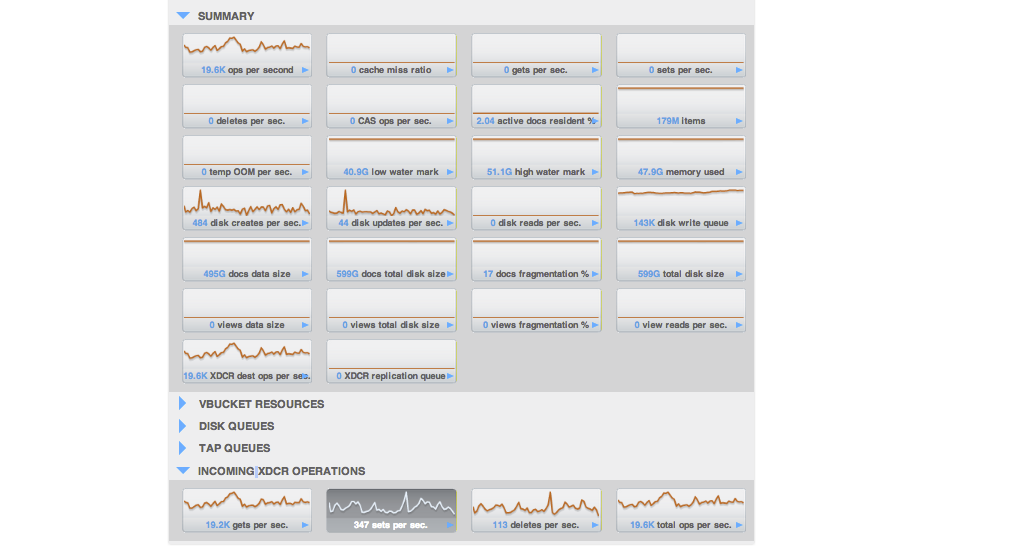
Also seen on the destination C2:
{on bucket "sbucket"}Gets per sec: 19.2K
Sets per sec: 347 (seems very low)
Also seeing a number of these errors on the XDCR tab on the source:
2012-10-15 19:17:50 - Error replicating vbucket 397: {http_request_failed, "POST", "http://Administrator:*****@ec2-175-41-177-173.ap-southeast-1.compute.amazonaws.com:8092/sbucket%2f397%3bc8731525718bcbdd0bf0382e420c453f/_revs_diff", {error,
{error,timeout}}}2012-10-15 19:17:50 - Error replicating vbucket 381: {http_request_failed, "POST", "http://Administrator:*****@ec2-175-41-177-173.ap-southeast-1.compute.amazonaws.com:8092/sbucket%2f381%3bc8731525718bcbdd0bf0382e420c453f/_revs_diff", {error,{error,timeout}
}}
....
Load on sbucket with mcsoda:
lib/perf_engines/mcsoda.py sbucket@ec2-50-18-140-172.us-west-1.compute.amazonaws.com:11211 vbuckets=1024 doc-gen=0 doc-cache=0 ratio-creates=1 ratio-sets=1 ratio-expirations=0.03 expiration=60 ratio-deletes=0.5 min-value-size=1000 threads=30 max-items=100000000 exit-after-creates=2 prefix=KEY1_ max-creates=100000000
Load on default with cbworkloadgen:
/opt/couchbase/bin/tools/cbworkloadgen -n ec2-54-251-5-97.ap-southeast-1.compute.amazonaws.com:8091 -r .7 -i 400000000 -s 128 -t 30 -p KEY3_
Killed the front end load on both the buckets right now, replication seen catching up.
Live clusters:
c1: http://ec2-50-18-140-172.us-west-1.compute.amazonaws.com:8091/
c2: http://ec2-54-251-5-97.ap-southeast-1.compute.amazonaws.com:8091/
Attached grabbed diags for the orchestrator on c1.
Attachments

| For Gerrit Dashboard: MB-6919 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 21613,6 | MB-6919: expose more XDCR stats to UI | master | ns_server | Status: MERGED | +2 | +1 |