Details
Description
- Setup a bidirectional replication between two 8:8 clusters on bucket b1.
- Setup a small front end load on cluster1 and cluster2 , 4K op/sec and 6K ops/sec.
[Load contains creates, updates, deletes]
- For the first 40M items, the replication is working as expected, the replication lag is small.
- Delete the replication from cluster2 to cluster1, recreate the replication.
[ Expected behaviour - Stop/Start replication.]
We expect that XDC will stop/start replication with the above step.
The last committed checkpoint will be checked and replication will continue from the last commited checkpoint.
Noticing a huge number of gets ~ 30K ops/sec and fewer sets - 2-3k ops/sec on the other cluster.
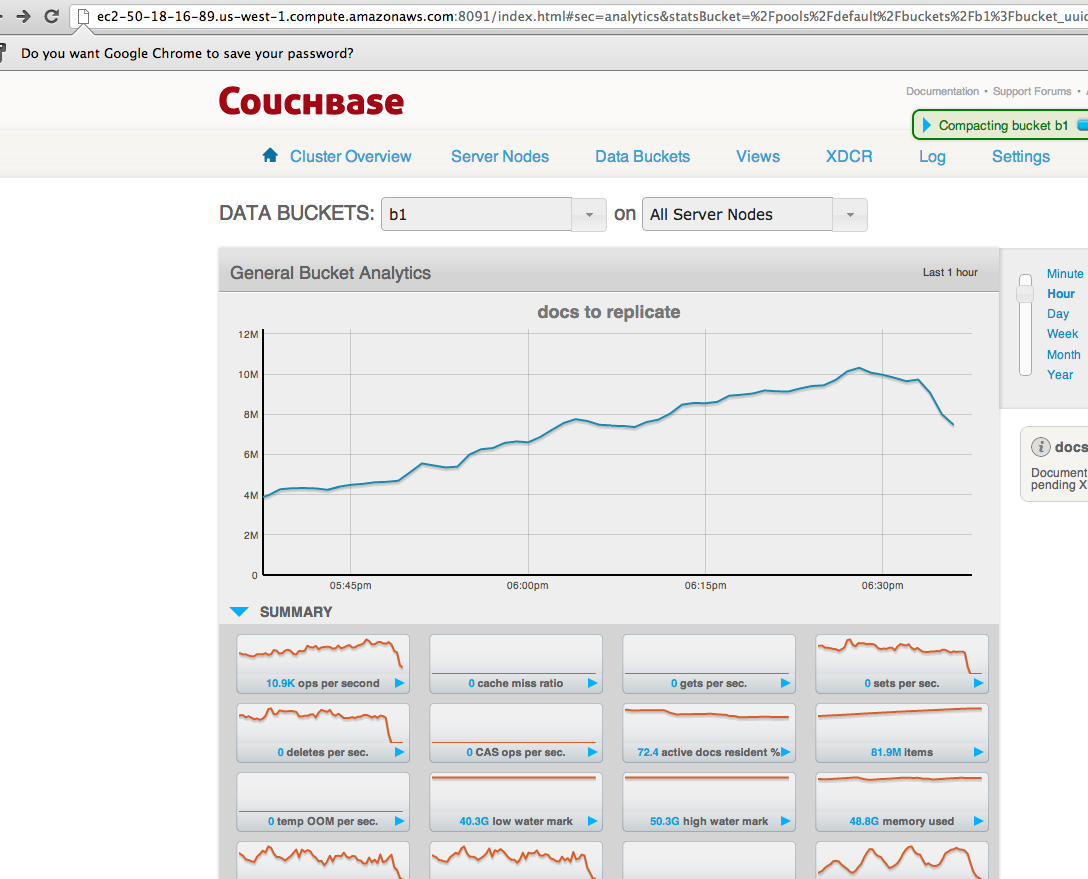
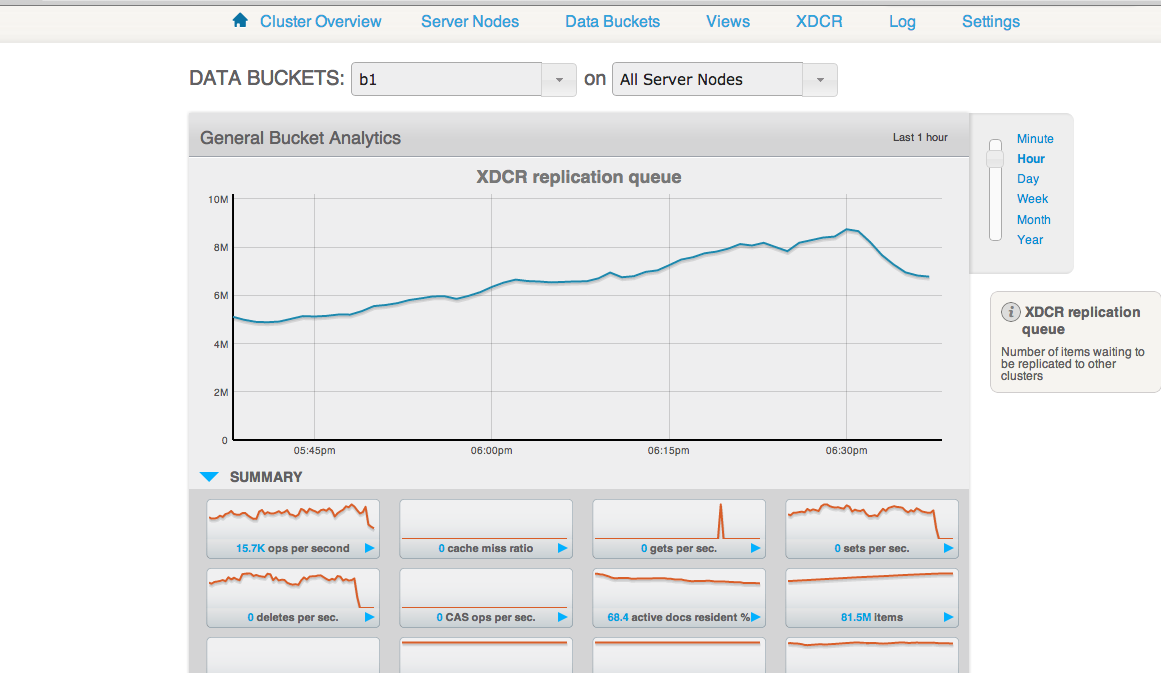
-The XDC queue is continuously growing, from < 500k to nearly 7M over a period of 2-3 hours.
- Seeing continous checkpoint_failures on both the XDC queues.
The Disk write queue on cluster1, is high ~ 2-3M. The drain rate however is fairly small ~ 30K.
The items are not drained fast enough and the disk-write-queue is getting filled up faster.
Adding screenshots from both the clusters.
The default values currently are -
XDCR_CHECKPOINT_INTERVAL:300
XDCR_CAPI_CHECKPOINT_TIMEOUT:10
@Junyi: I ve stopped the front end load on both the clusters now and I have passed on the cluster access.
Let me know if you need additional information.
Attachments
| For Gerrit Dashboard: MB-6939 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 21730,3 | MB-6939: use priority checkpointing in ensure_full_commit | master | ns_server | Status: MERGED | +2 | +1 |
| 21799,4 | MB-6939: increase XDCR checkpoint interval to 30 min | master | ns_server | Status: MERGED | +2 | +1 |