Details
-
Bug
-
Resolution: Cannot Reproduce
-
 Blocker
Blocker
-
2.0.1
-
Security Level: Public
-
couchbase-2.0.1-144-rel on Centos 5.4 on both source and destination
-
Release Note
Description
linux cluster
22-node-ec2-10GB-Linux
source Cluster ( 15 Nodes)
create default bucket -3.5 GB per node
sasl bucket - 2.0 GB per node
destination Cluster ( 7 Nodes)
create default bucket - 3.5 GB per node
sasl bucket - 2.0 GB per node
**Loading phase
Source cluster:
Default bucket
define a workload that loads 40 M json items , key size 128-512 bytes to default bucket.
The workload should push the system into a light dgm ( active resident ratio at 90 percent)
**Access Phase:
Source cluster:
Default bucket
create:5%, uupdate:10%, get:80%, delete:5% with cache miss:5%, opsPerSec:30000, running for 8 hours
Then start replication:
set a bi-directional XDCR on default bucket
Source cluster:
default bucket
create:5%, uupdate:10%, get:80%, delete:5% with cache miss:5%, opsPerSec:30000, running for 2 hours
Destination cluster:
default bucket
define a workload that loads 30 M json items(non-conflicting key-sets) , key size 128-512 bytes to default bucket.
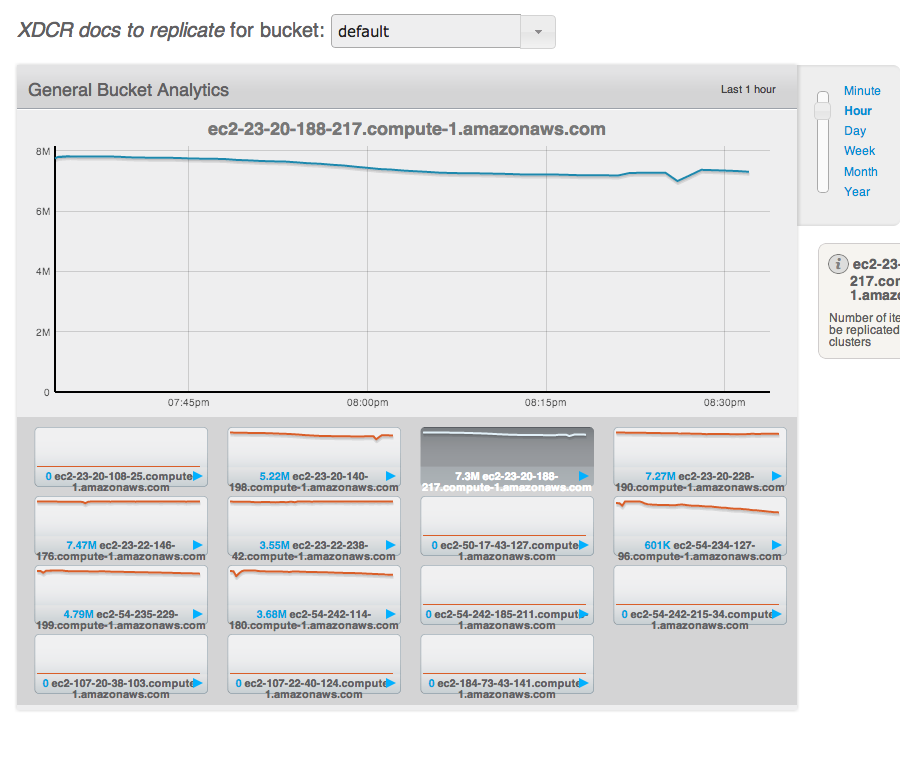
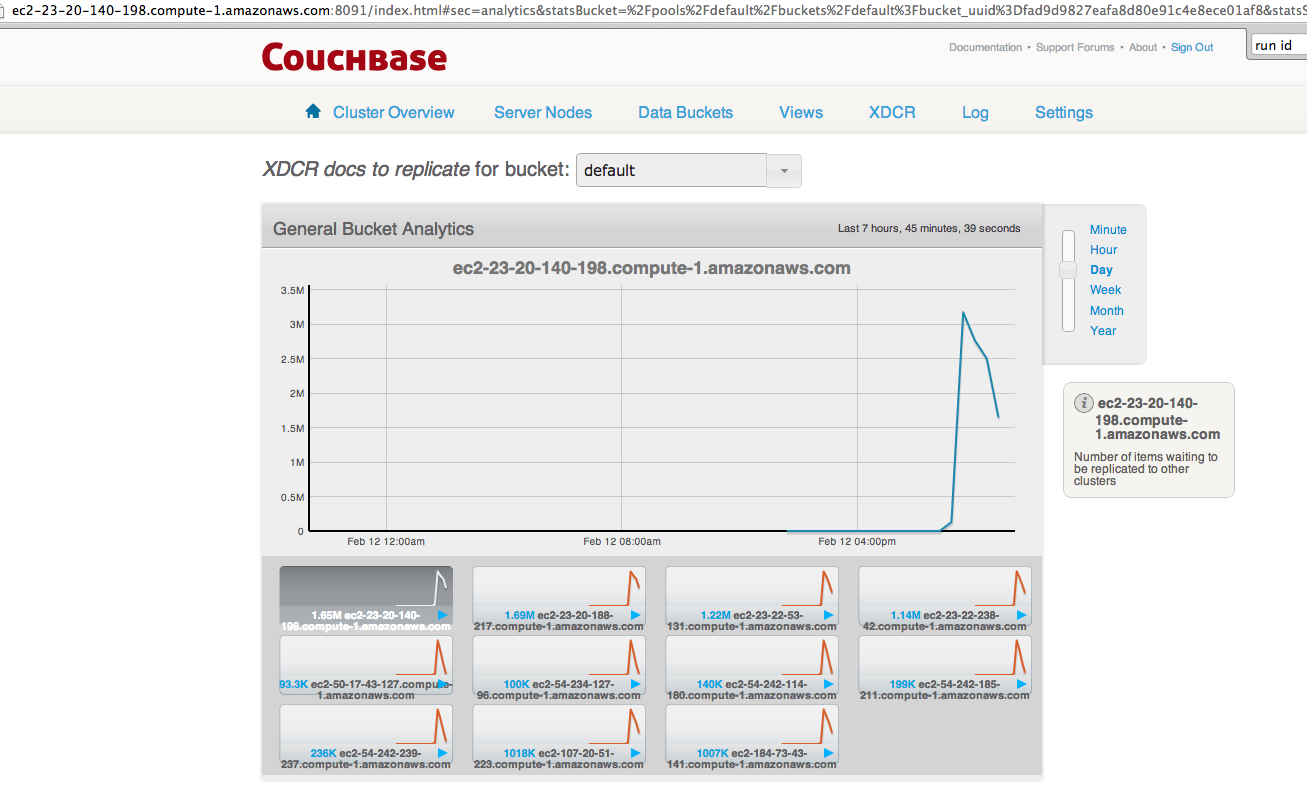
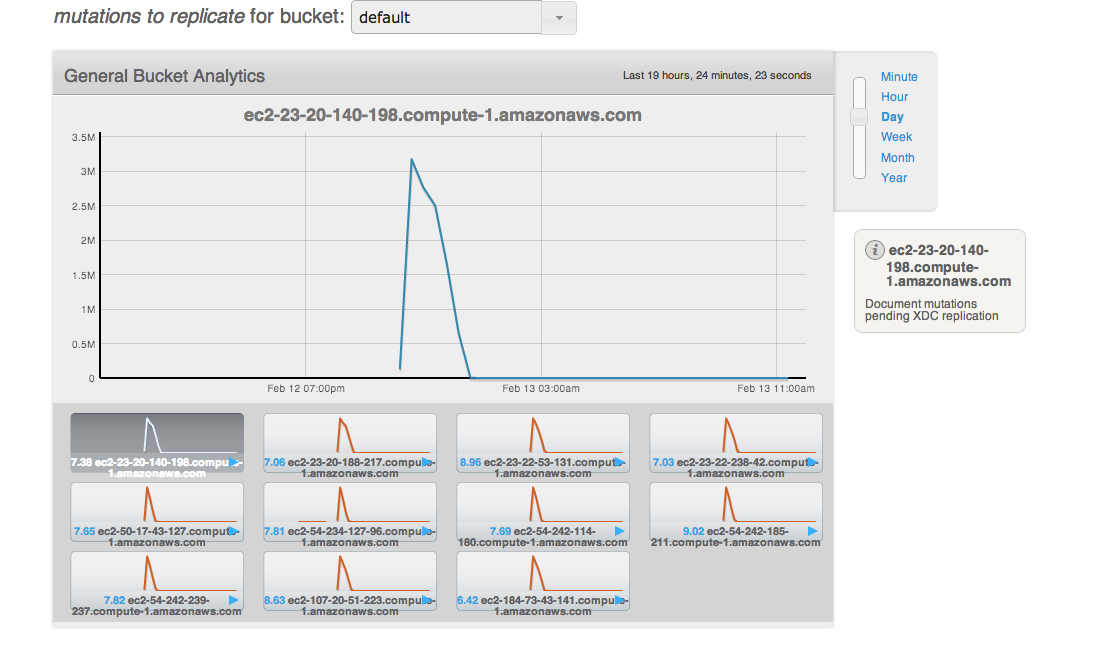
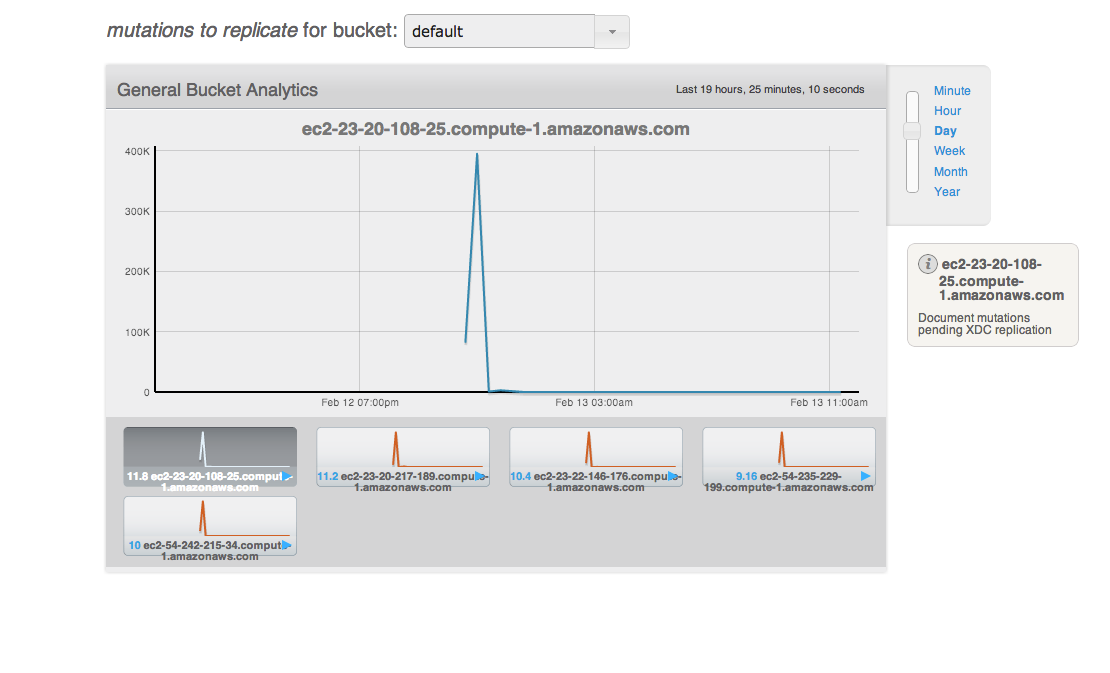
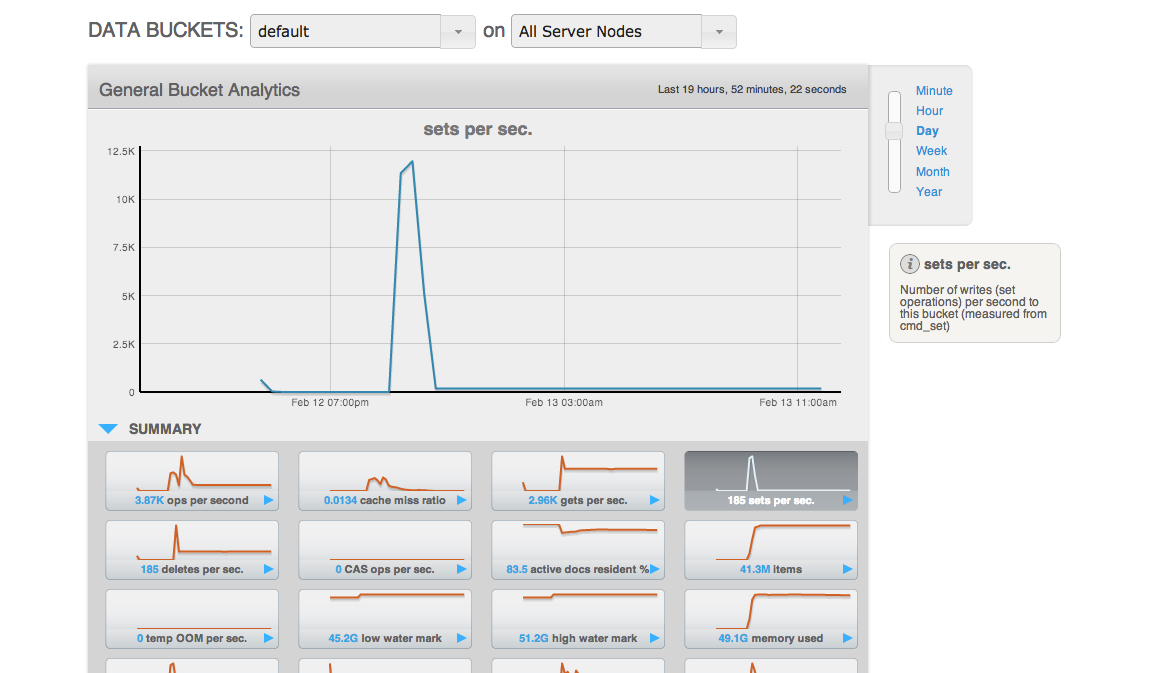
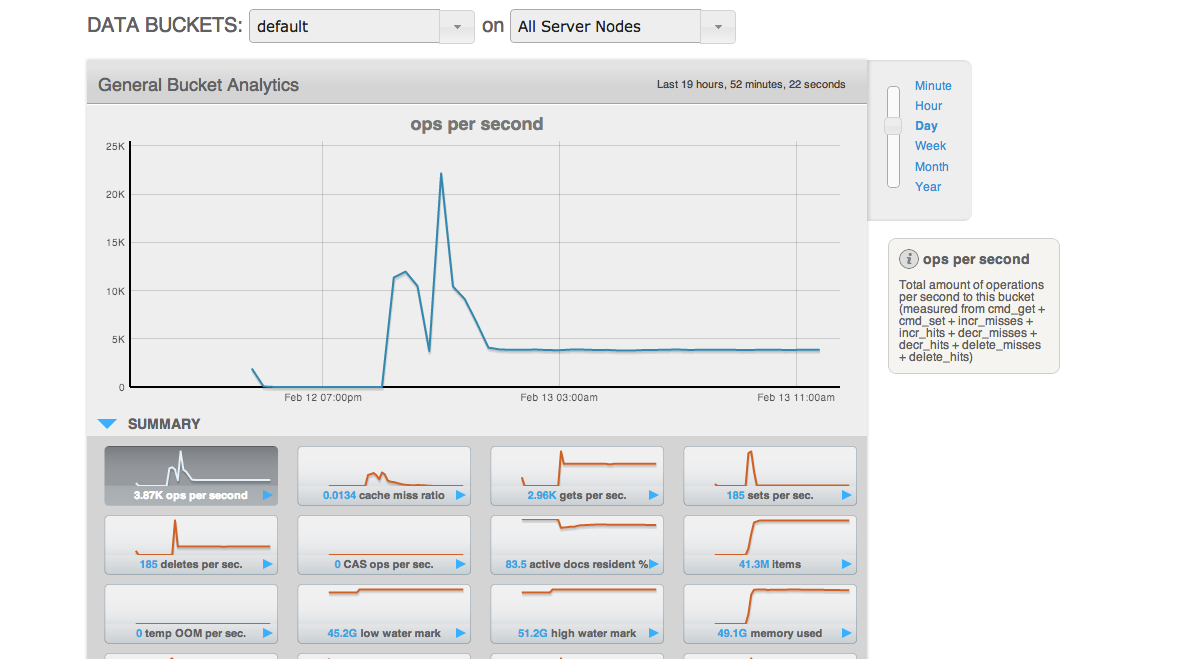
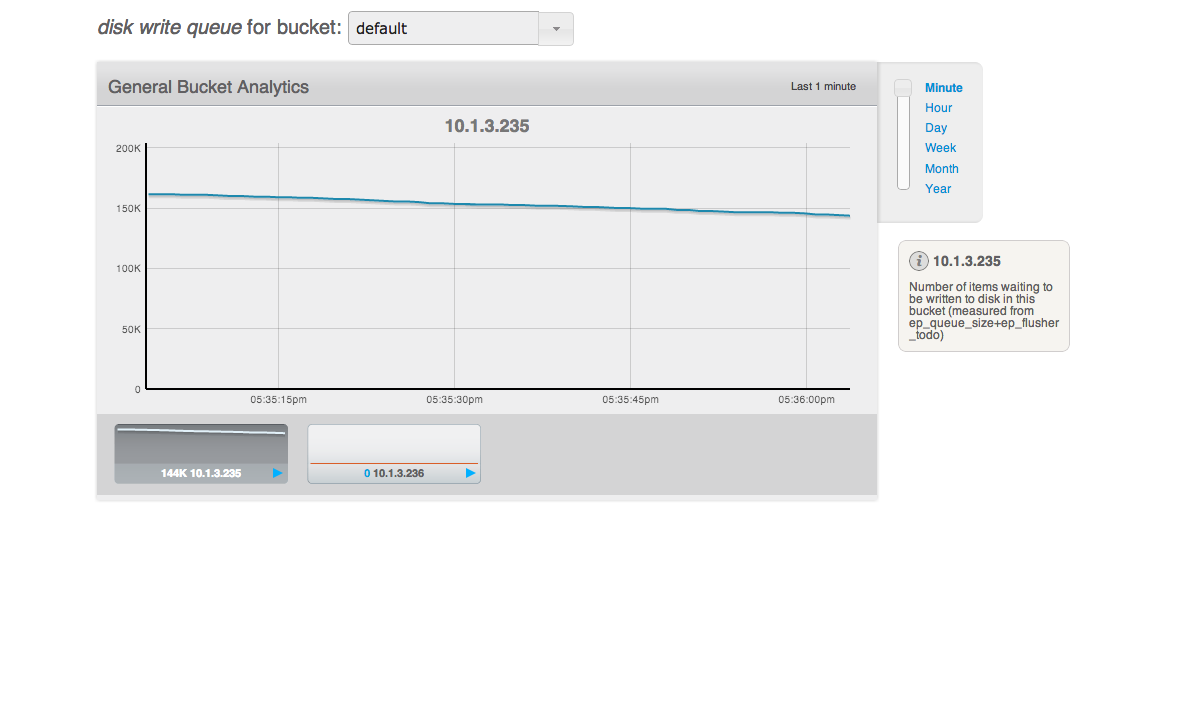
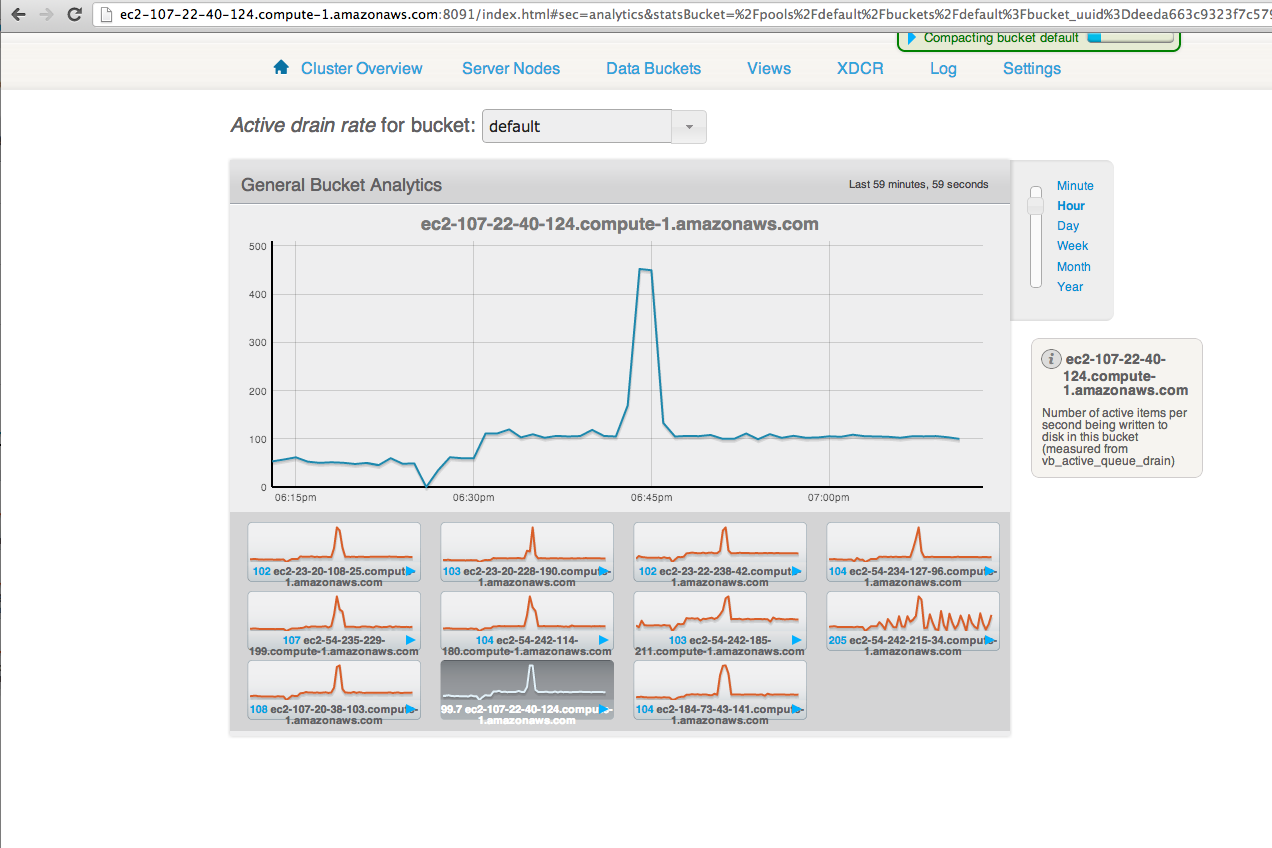
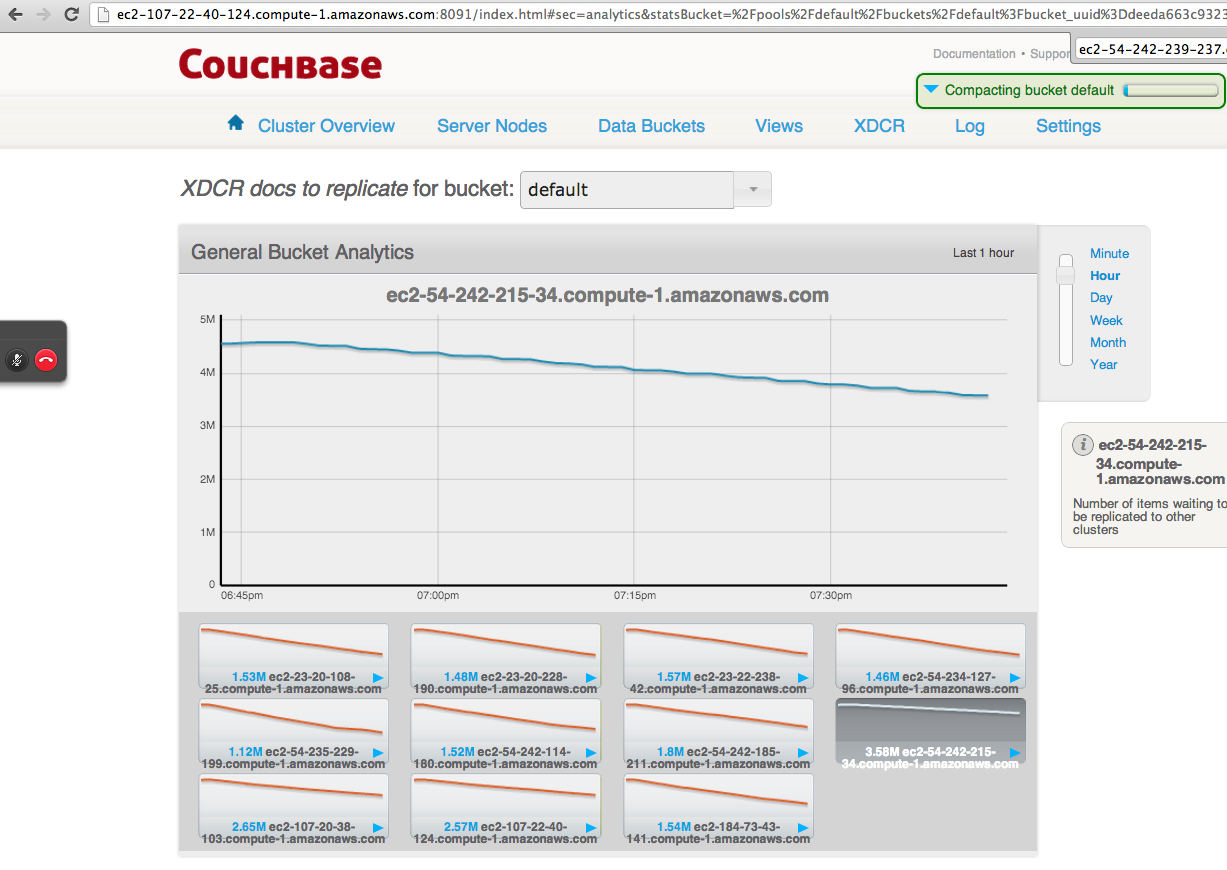
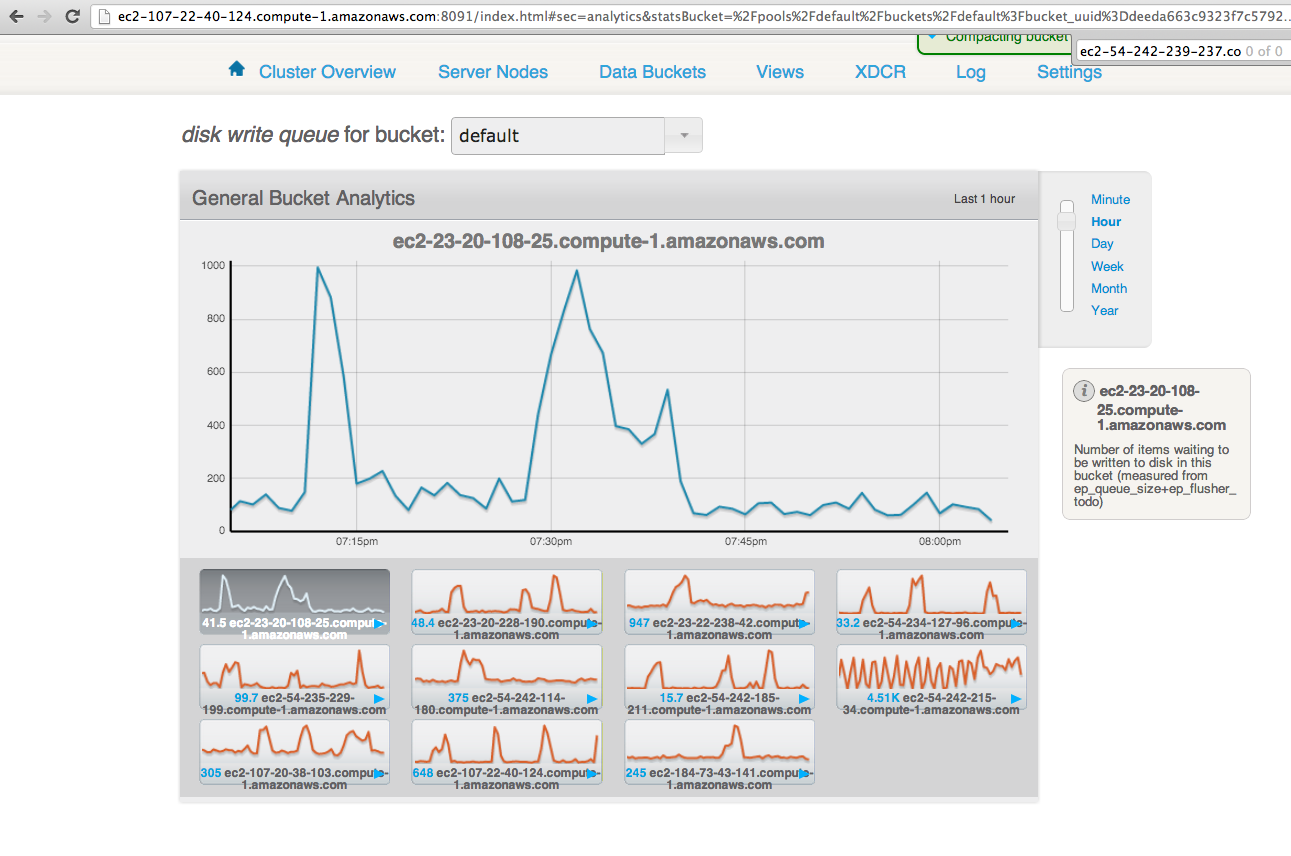
After all the loads on both clusters stop, wait for "XDCR docs to replicate for bucket" drops. But really slow.
Saw XDCR docs to replicate for bucket queue is draining unevenly on default bucket on source
The screen shot is from source cluster.