Details
-
Improvement
-
Resolution: Fixed
-
 Major
Major
-
2.0.1
-
Security Level: Public
-
2.0.1.-160-rel
-
Release Note
Description
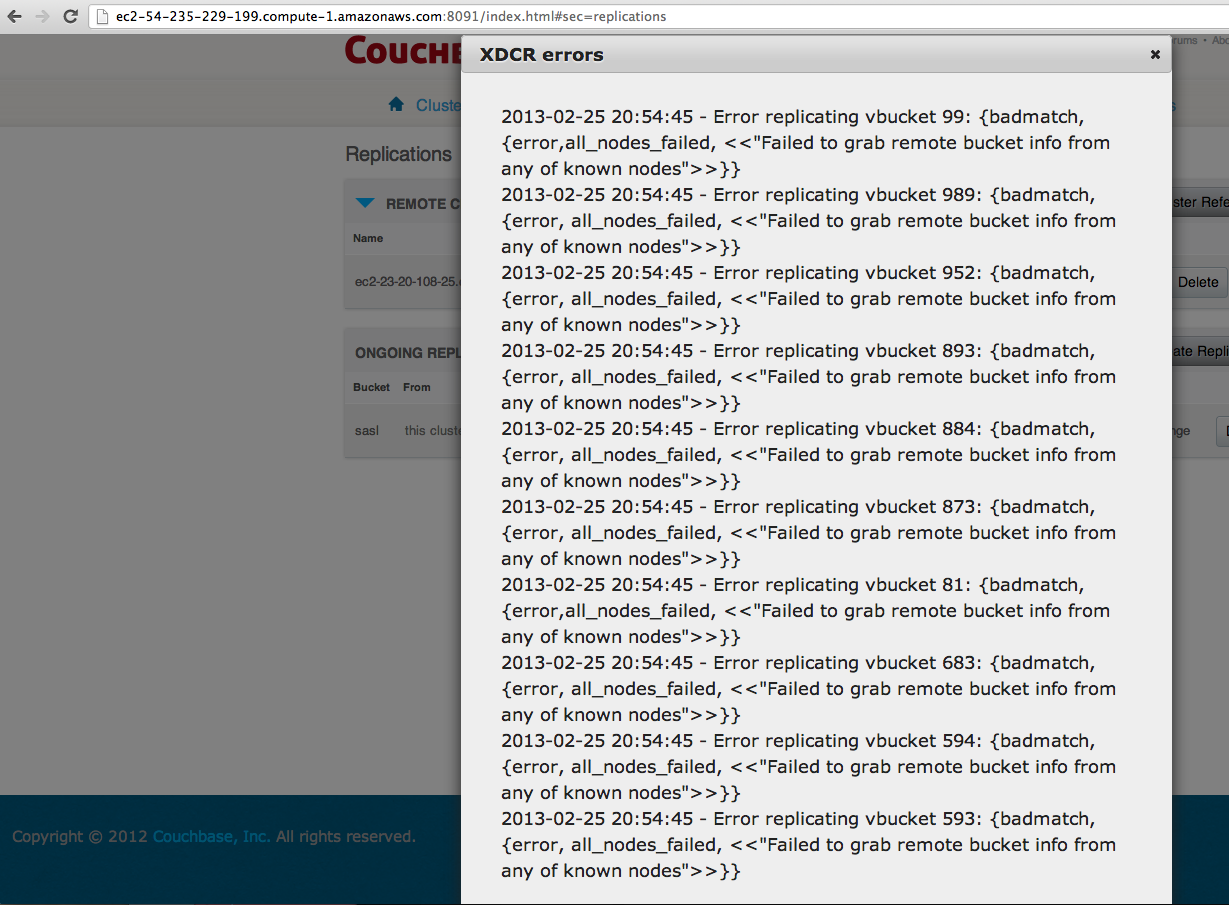
Seeing 2 issues when trying to setup replication for the first time between two clusters -
1.Frequently seeing error messages on creating the 1st time replication from cluster1 to cluster2.
"Failed to grab remote bucket info, vbucket.."
Both the buckets on source/destination are available for a long period of time, so it does not look like it is an issue w/ bucket not being ready.
I dont have logs on this currently, will add soon.
Seeing this across platforms - linux / windows and on most 2.0.1 runs.
2.Replication replicates data as expected, and these error messages persist for over an hour on the xdcr-last 10 errors. This gives user a wrong idea about the state of replication.
The intial Replication-call should either wait long enough to avoid these errors/ figure out if something else can be done here.
And also, how frequently do we clean up the xdcr-error messages on the console? Can we clear them sooner than current time?
Attachments
Issue Links
- is duplicated by
-
MB-7457 Spurious errors reported at startup of XDCR replication
-

- Closed
-