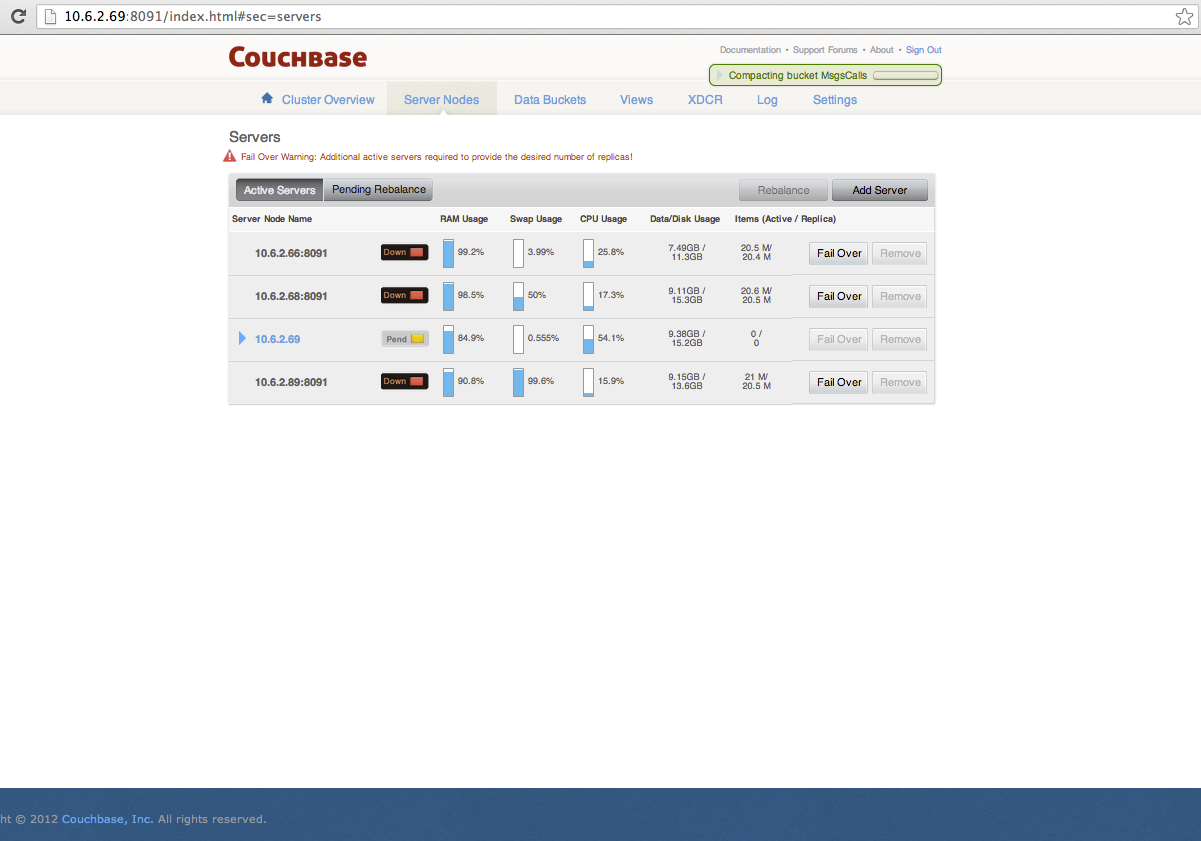
Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
2.0.1
-
Security Level: Public
-
None
-
2.0.1-160-rel
2 4-core-30G-SSDs + 2 8-core-30G-SSDs
Centos
4 buckets
Description
- Continuous load running on all 4 buckets
- Data Compaction running on one of the bucket 'MsgsCalls'
- Ran a curl post to purge deleted key information on all 4 buckets.
"curl -i -u Administrator:password -X POST http://<IP>:<PORT>/pools/default/buckets/<BUCKET_NAME>/controller/unsafePurgeBucket"
- Noticed 2 data compactions were running on 'MsgsCalls', and 1 each for the rest of the buckets.
- The entire cluster went down soon, with an OOM kill.
- High erlang usages on all nodes:
10.6.2.68
20641 couchbas 20 0 21.9g 20g 39m S 99.9 65.6 1556:01 beam.smp
10.6.2.66:
21770 couchbas 20 0 15.0g 13g 39m S 100.2 46.2 1618:29 beam.smp
10.6.2.69:
6783 couchbas 20 0 25.2g 23g 39m S 146.0 77.2 1361:58 beam.smp
10.6.2.89:
28802 couchbas 20 0 23.3g 21g 39m S 99.8 73.5 1579:18 beam.smp
From /var/log/messages on 10.6.2.69:
Feb 25 15:58:38 pine-11804 kernel: Out of memory: Kill process 6783 (beam.smp) score 716 or sacrifice child
Feb 25 15:58:38 pine-11804 kernel: Killed process 6819, UID 498, (memcached) total-vm:9476628kB, anon-rss:7074864kB, file-rss:988kB
cbcollect_info from all nodes:
https://s3.amazonaws.com/bugdb/MB~/10_6_2_66.zip
https://s3.amazonaws.com/bugdb/MB~/10_6_2_68.zip
https://s3.amazonaws.com/bugdb/MB~/10_6_2_69.zip
https://s3.amazonaws.com/bugdb/MB~/10_6_2_89.zip
Is the 2-data-compactors-running-over-the-same-bucket the reason why erlang usage shot up?
As per the UI, a total of 5 data compactions were running before the cluster went down.
Swap per node: 2064376k total
vm.swappiness = 0
- Rebooted the nodes:
All nodes came back up
However, beam.smp still has high memory consumption (up till 16G), even with the cluster idle right now..
Is it the garbage collector not kicking in that's causing the memory not to be freed?
- Couldn't find any message in the logs that compaction was killed.
- Live cluster (after the reboot) available at: http://10.6.2.68:8091