Details
-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
2.1.0
-
Security Level: Public
-
None
-
linux, windows
Description
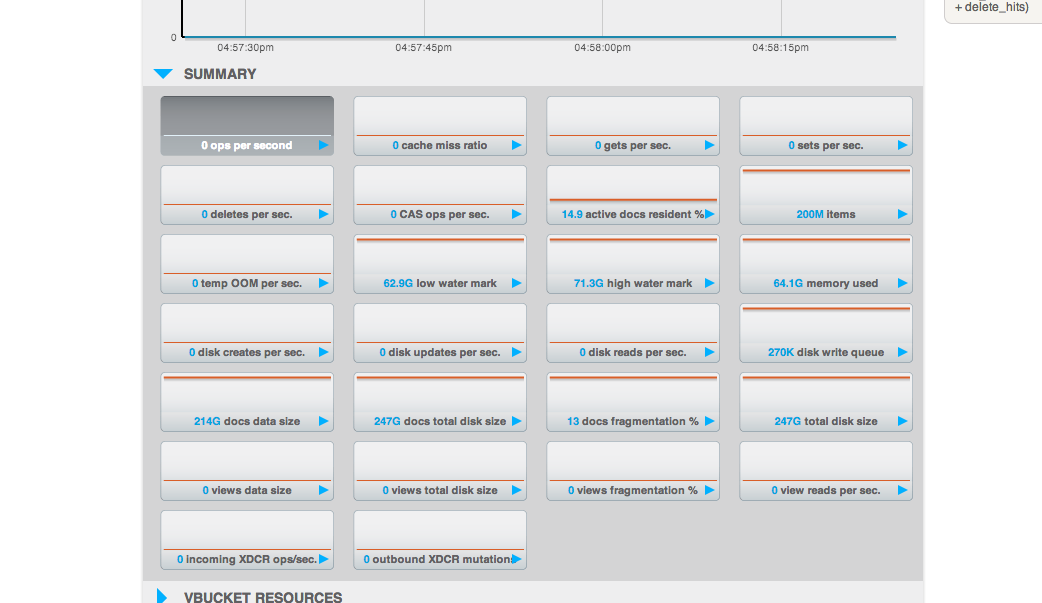
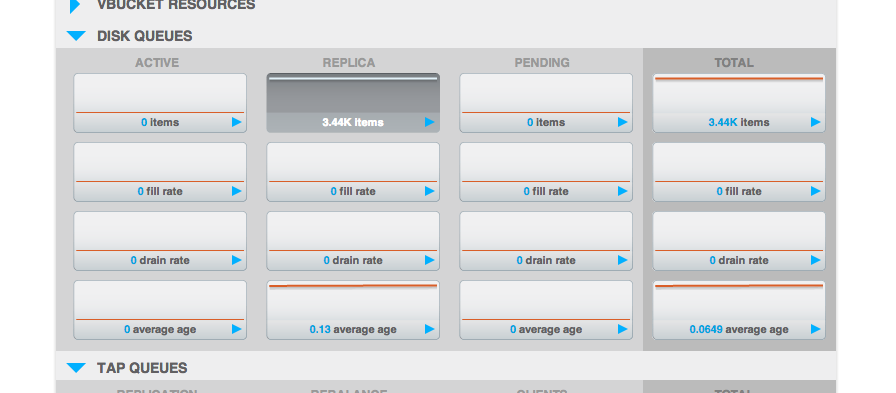
On the ec2 cluster I used for cbrecovery, the disk write queue didn't flush for a very long time. (this symptom was observed twice)
It's an xdcr dest cluster, no other ops rather than xdcr incoming traffic.
Fired as blocker, since it blocks the cbrecovery testing. The clusters are left intact as they are for developer to diagnose, please email back to me when the problem got resolved then I could continue the test. Thanks!
Ronnie
Destination:
http://ec2-184-169-190-197.us-west-1.compute.amazonaws.com:8091
And the source:
http://ec2-23-21-15-103.compute-1.amazonaws.com:8091
User: Administrator
Passwd: password
SSH:
user: root
passwd: couchbase
Now attach the original email thread with diagnosis from Jin and Junyi:
This should be a bug. There are a lot of crash in ns_server/baby_sitter and couchdb/writer process. Couchdb is unable to spawn writer process for some reasons.
I am not 100% sure which caused which but It should be unrelated to XDCR.
Please file a 2.0.2 bug and assign to Filipe to take first look. Thanks.
Junyi
On May 13, 2013, at 10:56 AM, Jin Lim wrote:
Logs from the ec2-184-169-190-197.us-west-1.compute.amazonaws.com. I see following error. After the error I see couch_db/updater kept crashing. I will wait until Junyi's quick looking at it from the xdcr side then figure out what is next.
Thanks,
Jin
[ns_server:info,2013-05-10T18:00:22.665,ns_1@ec2-184-169-190-197.us-west-1.compute.amazonaws.com:ns_config_log<0.562.0>:ns_config_log:handle_info:57]config change: rest_creds -> ********
[user:info,2013-05-10T18:00:22.718,ns_1@ec2-184-169-190-197.us-west-1.compute.amazonaws.com:<0.570.0>:ns_log:crash_consumption_loop:64]Port server moxi on node 'babysitter_of_ns_1@127.0.0.1' exited with status 0. Restarting. Messages: WARNING: curl error: transfer closed with outstanding read data remaining from: http://127.0.0.1:8091/pools/default/saslBucketsStreaming
WARNING: curl error: couldn't connect to host from: http://127.0.0.1:8091/pools/default/saslBucketsStreaming
ERROR: could not contact REST server(s): http://127.0.0.1:8091/pools/default/saslBucketsStreaming
EOL on stdin. Exiting
[user:info,2013-05-10T18:00:32.169,ns_1@ec2-184-169-190-197.us-west-1.compute.amazonaws.com:<0.570.0>:ns_log:crash_consumption_loop:64]Port server moxi on node 'babysitter_of_ns_1@127.0.0.1' exited with status 0. Restarting. Messages: 2013-05-10 18:00:22: (cproxy_config.c.317) env: MOXI_SASL_PLAIN_USR (13)
2013-05-10 18:00:22: (cproxy_config.c.326) env: MOXI_SASL_PLAIN_PWD (8)
On May 13, 2013, at 10:41 AM, Ronnie Sun wrote:
Hi Jin, Junyi
On the ec2 cluster I used for cbrecovery, the disk write queue didn't flush for a very long time. (this symptom was observed twice)
It's an xdcr dest cluster, no other ops rather than xdcr incoming traffic.
Everything looks normal, not sure if it's related to the recent reb regression. Would you please take a look at it, thanks!
Ronnie
Destination:
http://ec2-184-169-190-197.us-west-1.compute.amazonaws.com:8091
And the source:
http://ec2-23-21-15-103.compute-1.amazonaws.com:8091
User: Administrator
Passwd: password
SSH:
user: root
passwd: couchbase
Attachments
| For Gerrit Dashboard: MB-8259 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 26612,3 | MB-8259 Maintain a disk queue size stat per shard. | 2.0.2 | ep-engine | Status: ABANDONED | 0 | 0 |
| 26621,2 | MB-8259 Reflect checkpoint collasping impact on disk queue size. | 2.0.2 | ep-engine | Status: MERGED | +2 | +1 |