Details
-
Bug
-
Resolution: Duplicate
-
 Major
Major
-
2.1.0
-
Security Level: Public
-
None
-
7 node cluster with buil 2.0.2-809-rel on Win2008R2
-
Windows 64-bit
Description
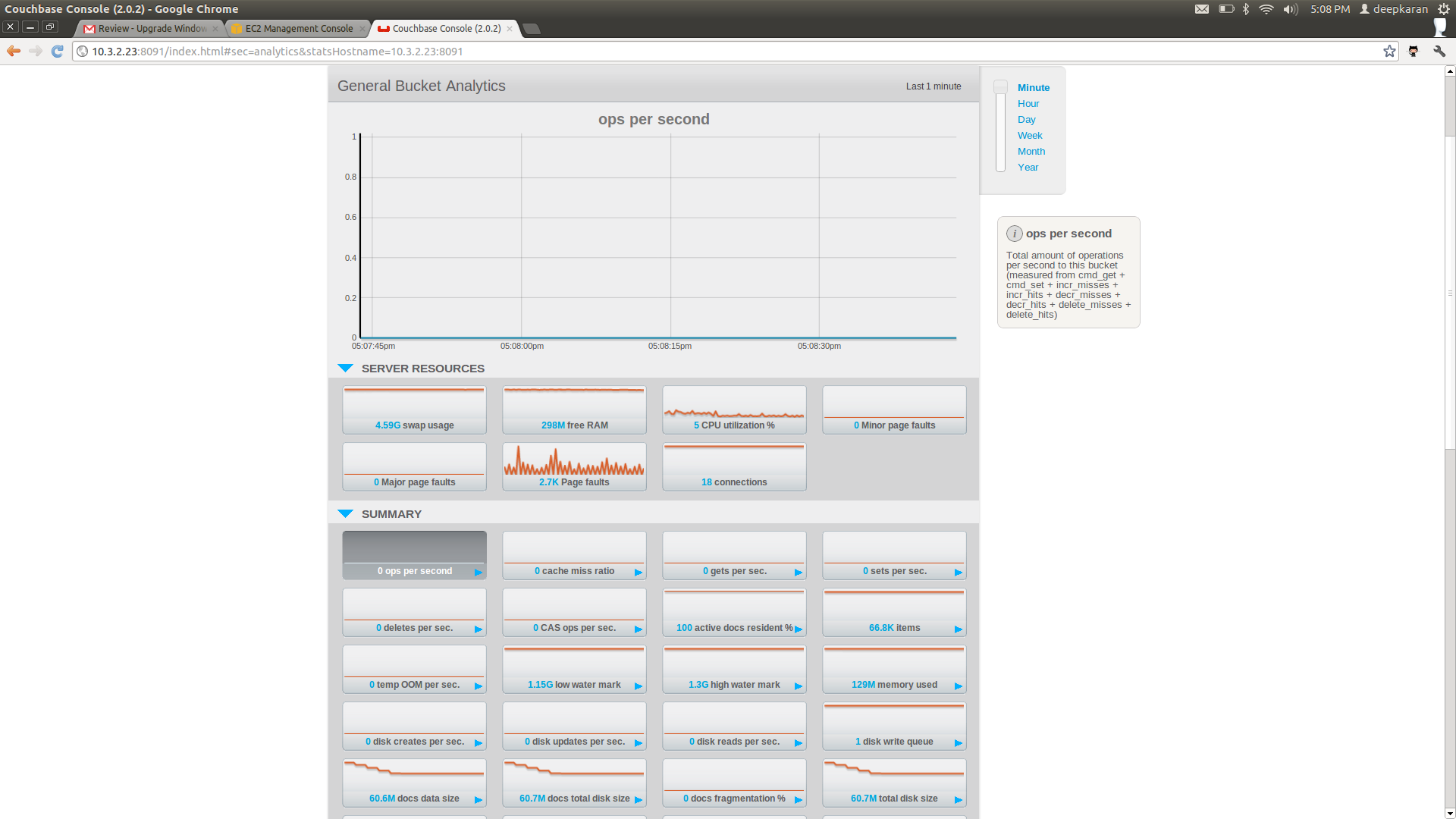
Disk Write Queue doesn't drain completely after rebalancing out some nodes from the cluster
Test to reproduce:
./testrunner -i vm-4win.ini -t rebalance.rebalanceout.RebalanceOutTests.incremental_rebalance_out_with_ops,replicas=2,items=100000,max_verify=100000,doc_ops=create
The test creates a 7 node cluster and then keeps rebalancing out 2 nodes at a time while data loading is in progress.
After rebalance is done, one of the nodes in the cluster has ep_queue_size=1 and doesn't drain for > 150 seconds.
Please see attached screenshot, all data activity is finished and compaction also completed, but DWQ is still 1.
Reproducible on both internal VMs and EC2 consistently.
Diagnostics are attached.