Details
Description
Scenario
-------------
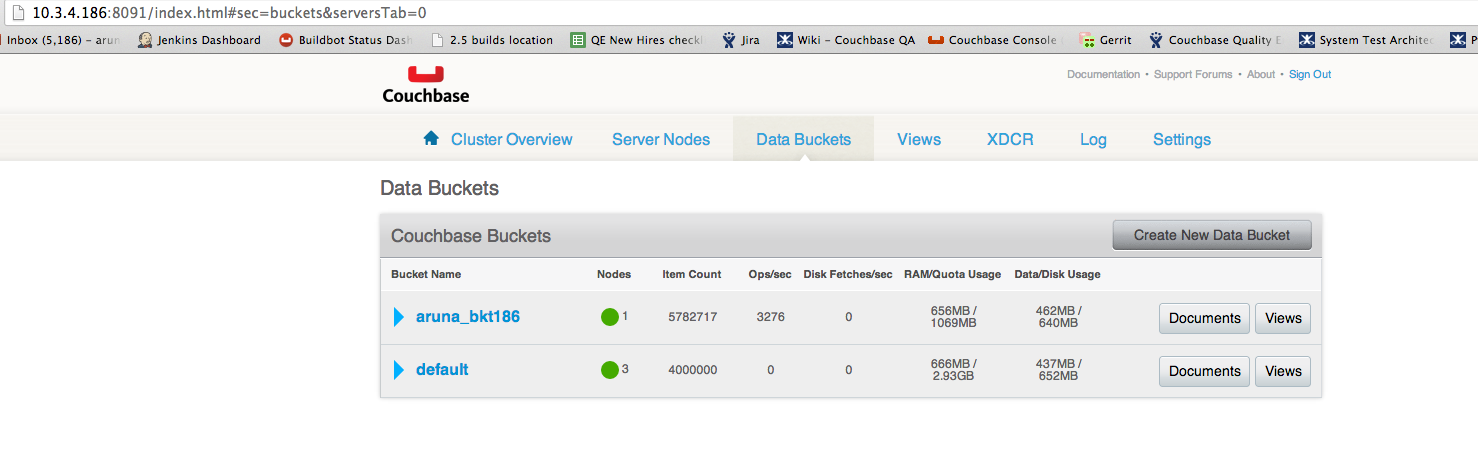
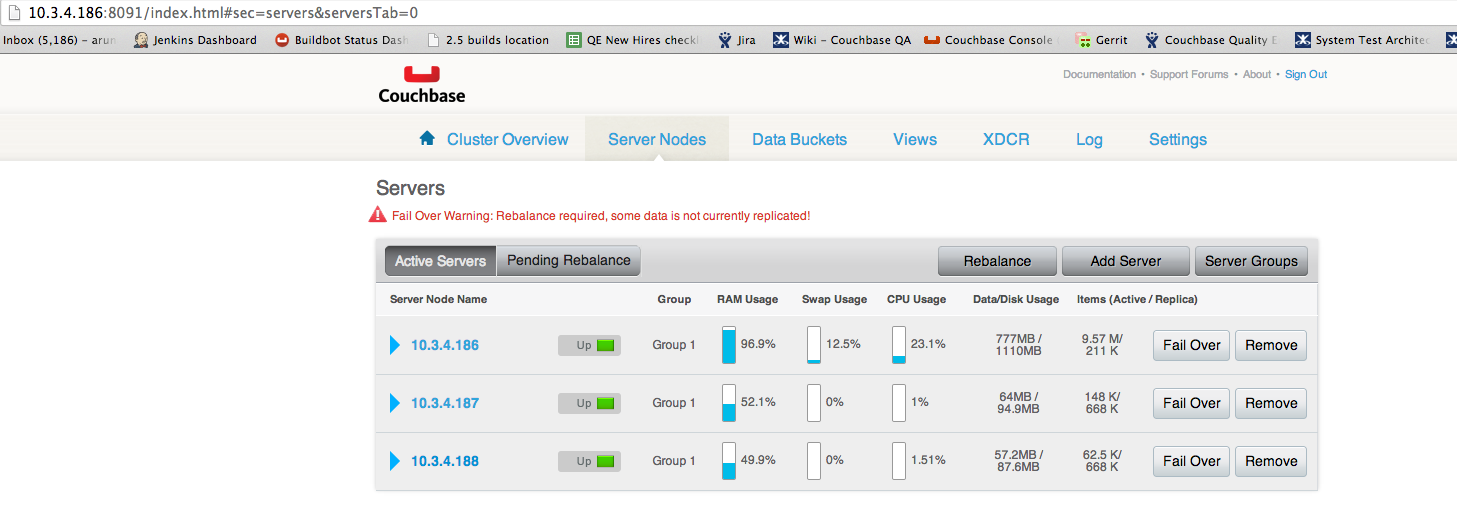
I have 2 clusters (3*3) with bidirectional XDCR setup. I pump data(3M items) simultaneously into both clusters. While data is getting loaded and replicated to other cluster, I rebalance out 2 nodes from cluster1. The performance dips, rebalance runs for a long time, but fails at the end of the operation. By that time, data has been loaded into the bucket aruna_bkt186. Now I try to rebalance out the same two nodes again. Rebalance-out again fails, but this time the data buckets tab shows aruna_bkt186 on 1 node but default bucket on 3 nodes. The disk usage on the rebalanced nodes also goes down greatly. Therefore, rebalance-out seems to fail before deleting default bucket from the 2 nodes. Also, the node we are transferring the data to (10.3.4.186) goes down, I'm not sure if it is because of its RAM usage. Screenshots of the server and data buckets are attached.
Error as seen in log-
------------------------------
Rebalance exited with reason {bulk_set_vbucket_state_failed,
[{'ns_1@10.3.4.186',
{'EXIT',
{{nodedown,'ns_1@10.3.4.186'},
{gen_server,call,
[
,
{if_rebalance,<0.3526.54>,
{update_vbucket_state,379,replica,
passive,undefined}},
infinity]}}}}]}
ns_orchestrator002
Node 'ns_1@10.3.4.188' saw that node 'ns_1@10.3.4.186' went down. Details: [
<0.31020.54> exited with {bulk_set_vbucket_state_failed,
[{'ns_1@10.3.4.186',
{'EXIT',
{{nodedown,'ns_1@10.3.4.186'},
{gen_server,call,
[{'janitor_agent-default','ns_1@10.3.4.186'},
{if_rebalance,<0.3526.54>,
{update_vbucket_state,379,replica,passive,
undefined}},
infinity]}}}}]} ns_vbucket_mover000
Node 'ns_1@10.3.4.187' saw that node 'ns_1@10.3.4.186' went down. Details: [{nodedown_reason, connection_closed}
] ns_node_disco005
Server error during processing: ["web request failed",
,
{type,exit},
{what,
{timeout,
{gen_server,call,
[
,
get_detailed_progress,10000]}}},
{trace,
[
,
{ns_rebalance_observer, get_detailed_progress,0},
{ns_doctor,get_detailed_progress,0},
{ns_doctor,do_build_tasks_list,4},
{menelaus_web,handle_tasks,2},
{request_throttler,do_request,3},
{menelaus_web,loop,3},
{mochiweb_http,headers,5}]}] menelaus_web019
Shutting down bucket "aruna_bkt186" on 'ns_1@10.3.4.188' for deletion
Shutting down bucket "aruna_bkt186" on 'ns_1@10.3.4.187' for deletion
Bucket "default" rebalance does not seem to be swap rebalance
Started rebalancing bucket default
Bucket "aruna_bkt186" rebalance does not seem to be swap rebalance ns_vbucket_mover000
Started rebalancing bucket aruna_bkt186
Starting rebalance, KeepNodes = ['ns_1@10.3.4.186'], EjectNodes = ['ns_1@10.3.4.188',
'ns_1@10.3.4.187']
XDCR info
----------------
3*2 bidirectional XDCR
[cluster1] - all nodes running 2.5.0-871
1:10.3.4.186
2.10.3.4.187
3.10.3.4.188
[cluster2] - all nodes running 2.2.0-821
1.10.3.4.189
2.10.3.4.190
3.10.3.4.191
Error is seen while trying to rebalance-out 10.3.4.187 and 10.3.4.188 from cluster1.
Bucket info
----------------
default and 1 SASL bucket(aruna_bkt186) on cluster1 bidirectionally replicated with default and aruna_bkt189on cluster2 respectively.
aruna_bkt186 --> aruna_bkt189 : replication protocol version2
aruna_bkt186 <-- aruna_bkt189 : v1
default on 10.3.4.186 --> default on 10.3.4.189 : v2
default on 10.3.4.186 <-- default on 10.3.4.189 : v1.
Cbcollect info attached.
Attachments
Issue Links
- relates to
-
MB-9209 Increasing beam memory usage over replication on source XDCR nodes
-

- Closed
-