Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
None
-
3.0.1
-
None
-
1
-
SDK48: FTS Score/Incl, Docs., SDK51: FLEpt1, Txns Test Compl, SDK2: FLEpt2, TxnsTest, SDK4: 3.1GA,Ruby3.1,TxnTst,FLE
Description
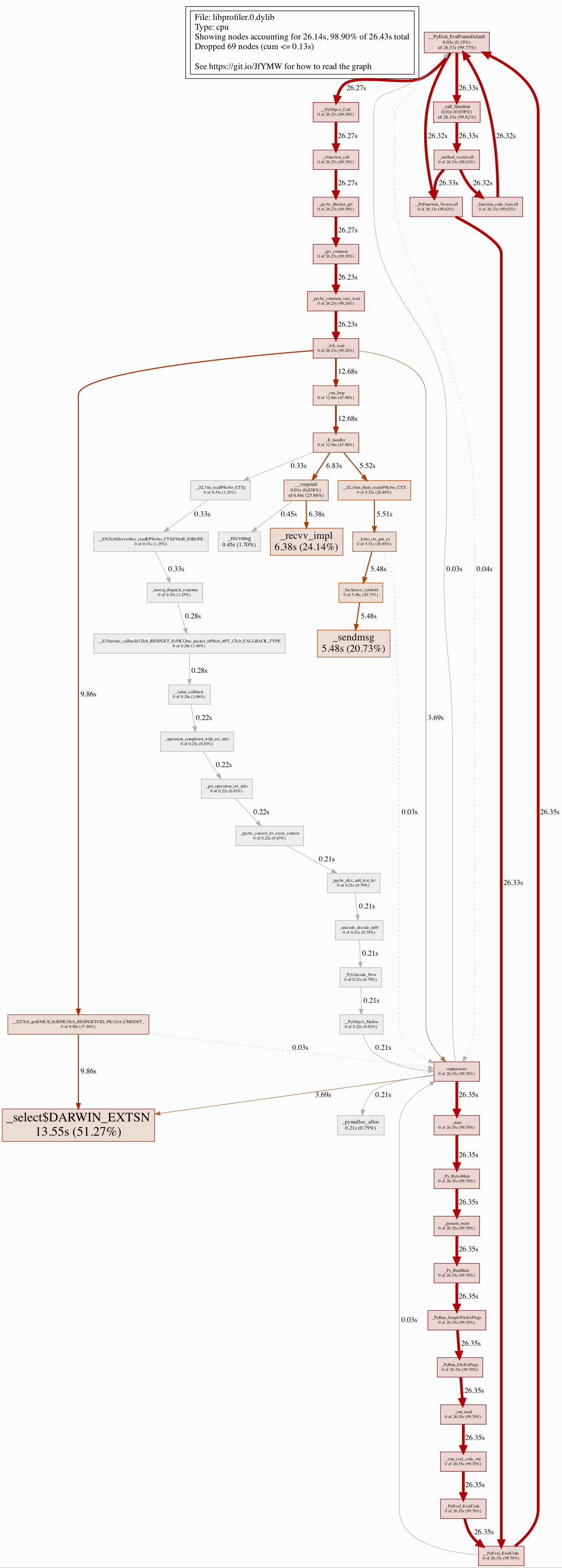
Comparing SDK3 to SDK2 kv get/set latency, we see that across all latency percentiles, SDK3 is ~20-30% higher than SDK2. Here are the two tests for comparison:
SDK 2.5.0 - 24 workers:
http://perf.jenkins.couchbase.com/job/ares/17051/
SDK 3 - 24 workers:
http://perf.jenkins.couchbase.com/job/ares/17049/
In both tests, kv ops are against default scope/collection.
SDK3 is this patch: git+http://review.couchbase.org/couchbase-python-client@refs/changes/91/135991/3
Here is a comparison graph:
The only difference in these tests, other than sdk version, cur_connections to bucket and ESTABILSHED connections to master node 172.23.133.13. Perhaps these "extra" connections are causing the slow down as the "extra" connections is around 30% more than sdk2 which corresponds to the increase in latency
Workaround
Remove any externally installed libcouchbase releases from the system. When run with the built-in libcouchbase, the higher latency is not observed.