Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
2.7.3
-
None
-
None
-
Linux ip-10-0-129-240 4.4.11-23.53.amzn1.x86_64 #1 SMP Wed Jun 1 22:22:50 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Description
When running cbc-pillowfight, if a node is stopped, and a failover triggered, cbc-pillowfight does not recover.
Version tested as failing: 2.7.3
Version tested as working: 2.6.4
Steps to reproduce:
Note also, brief video showing reproduction steps here:
https://drive.google.com/open?id=0Bz1warxYkSR1REpGSEhWell6eVk
- Create 3 node cluster, 1 bucket
- From a separate application server, run cbc-pillowfight
- One one node in the cluster run:
- service couchbase-server stop
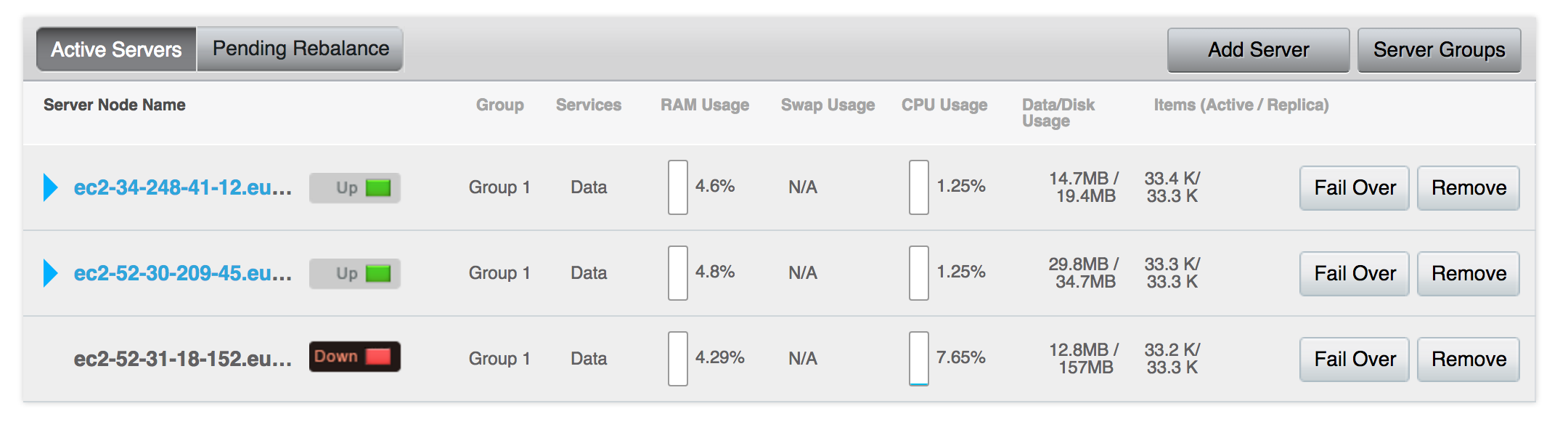
- The node will show up as 'down' in the UI
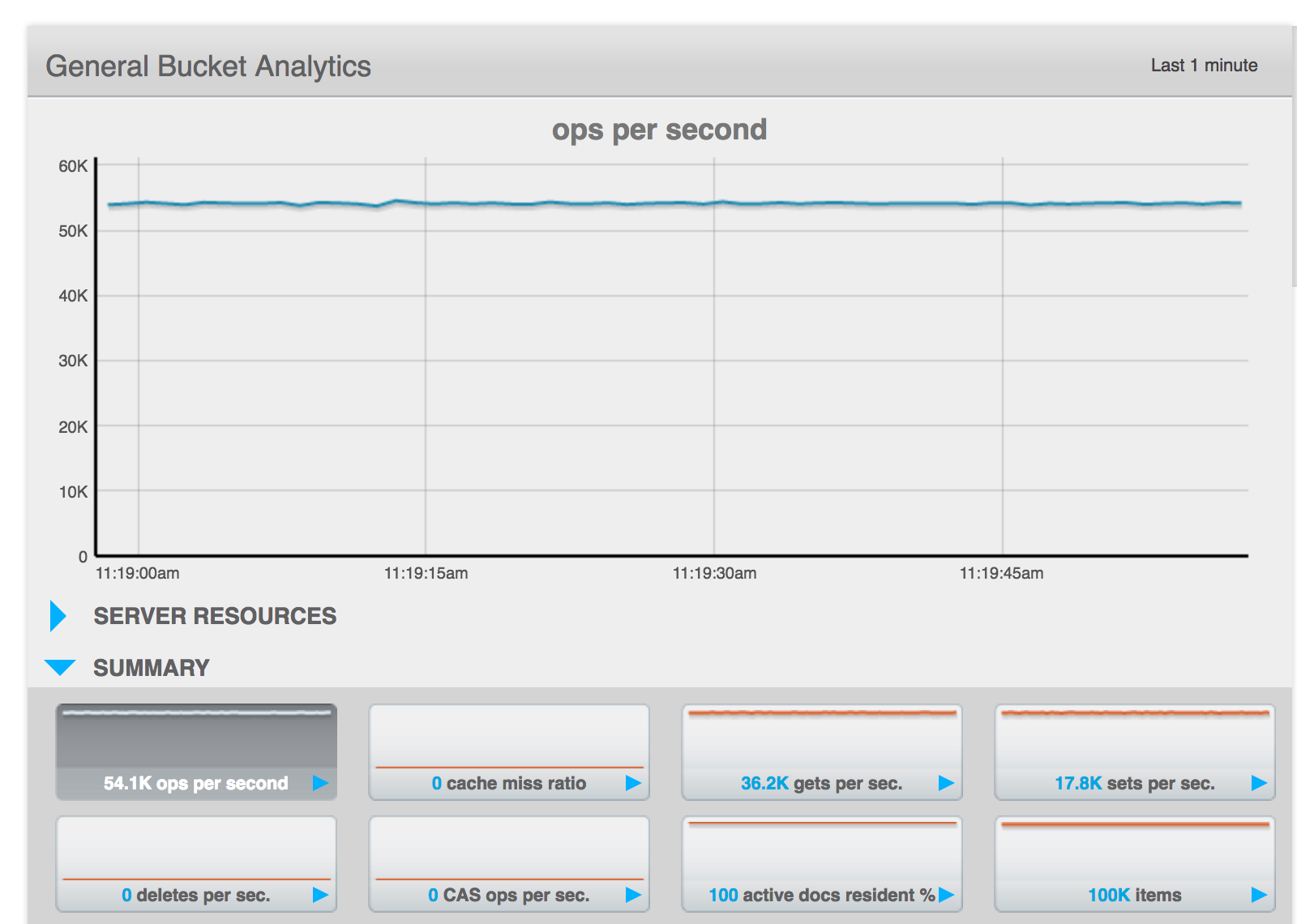
- There are less than 1024 active vbuckets.
- Pillowfight's traffic load will become sporadic due to timeouts (this is expected, I think).
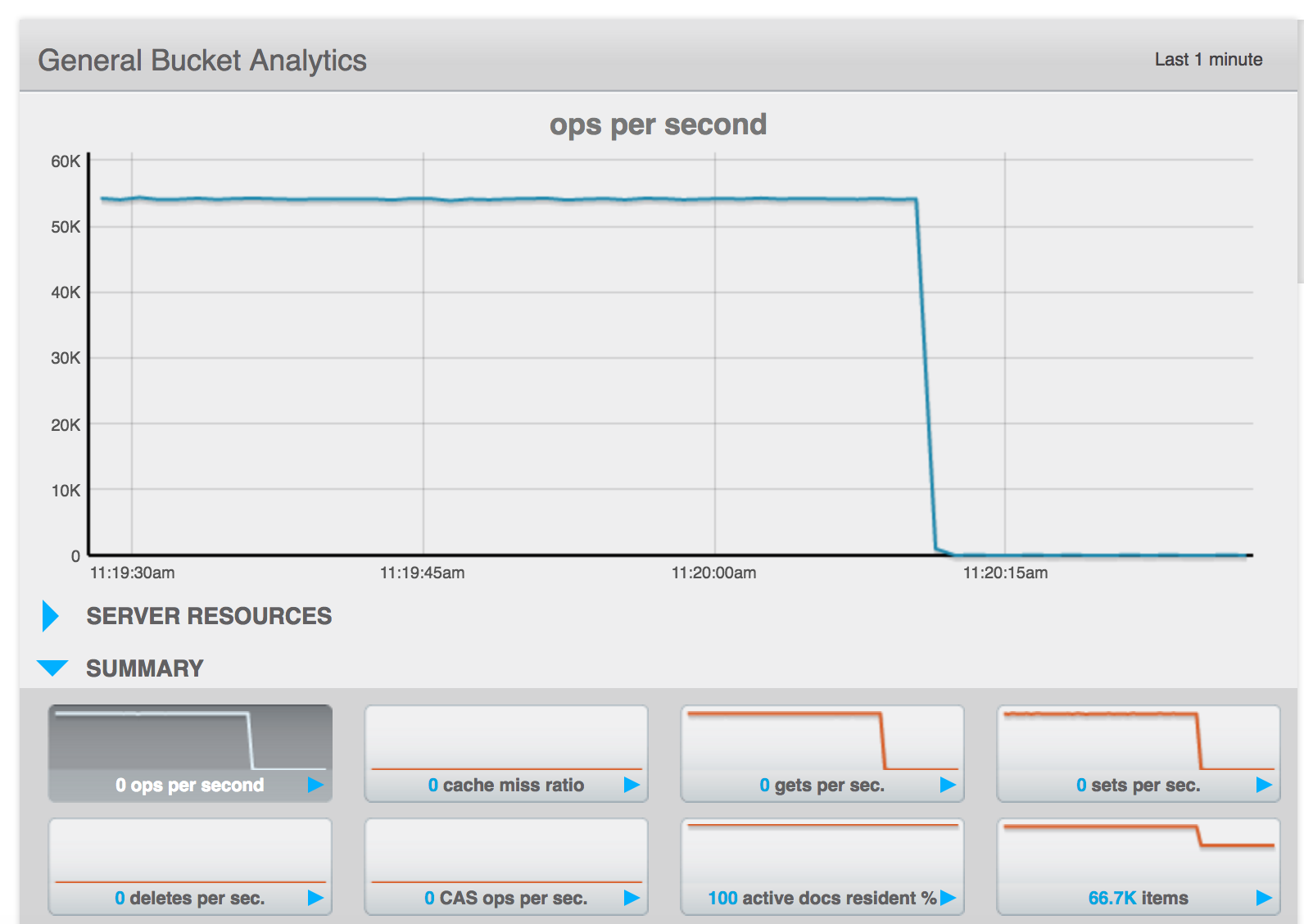
- Trigger a failover from the UI of the down node
- There are now 1024 active vbuckets
- Pillowfight does not recover, traffic remains sporadic.
- ... ...
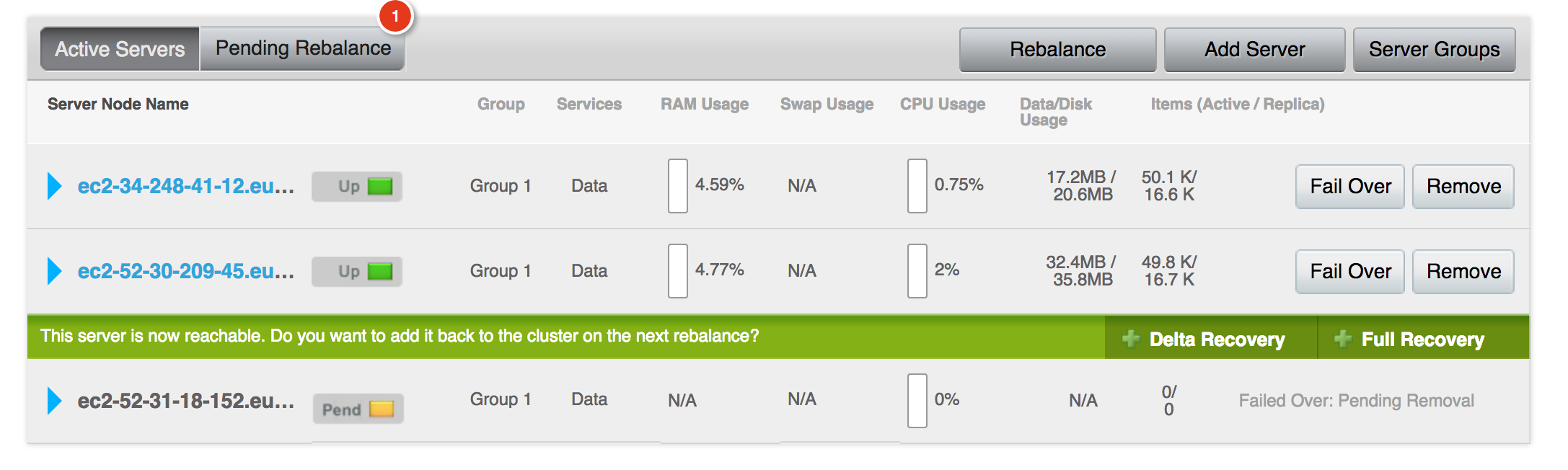
- Start the couchbase node again
- service couchbase-server start
- Add the node back in with 'delta recovery' option.
- Issue rebalance
- As soon as the rebalance is started (and before it is complete!) pillowfight appears to start running full traffic loads again successfully.
Further notes:
- I found same behaviour regardless of whether couchbase was shutdown cleanly or had a 'hard stop'.
- My tests showed that this worked successfully on 2.6.4, I will collect additional logs for this version and attach to ticket.
Attachments:
- pillowfight.log a -vvv log from pillowfight client run during the full process outlined above, with version 2.7.3.
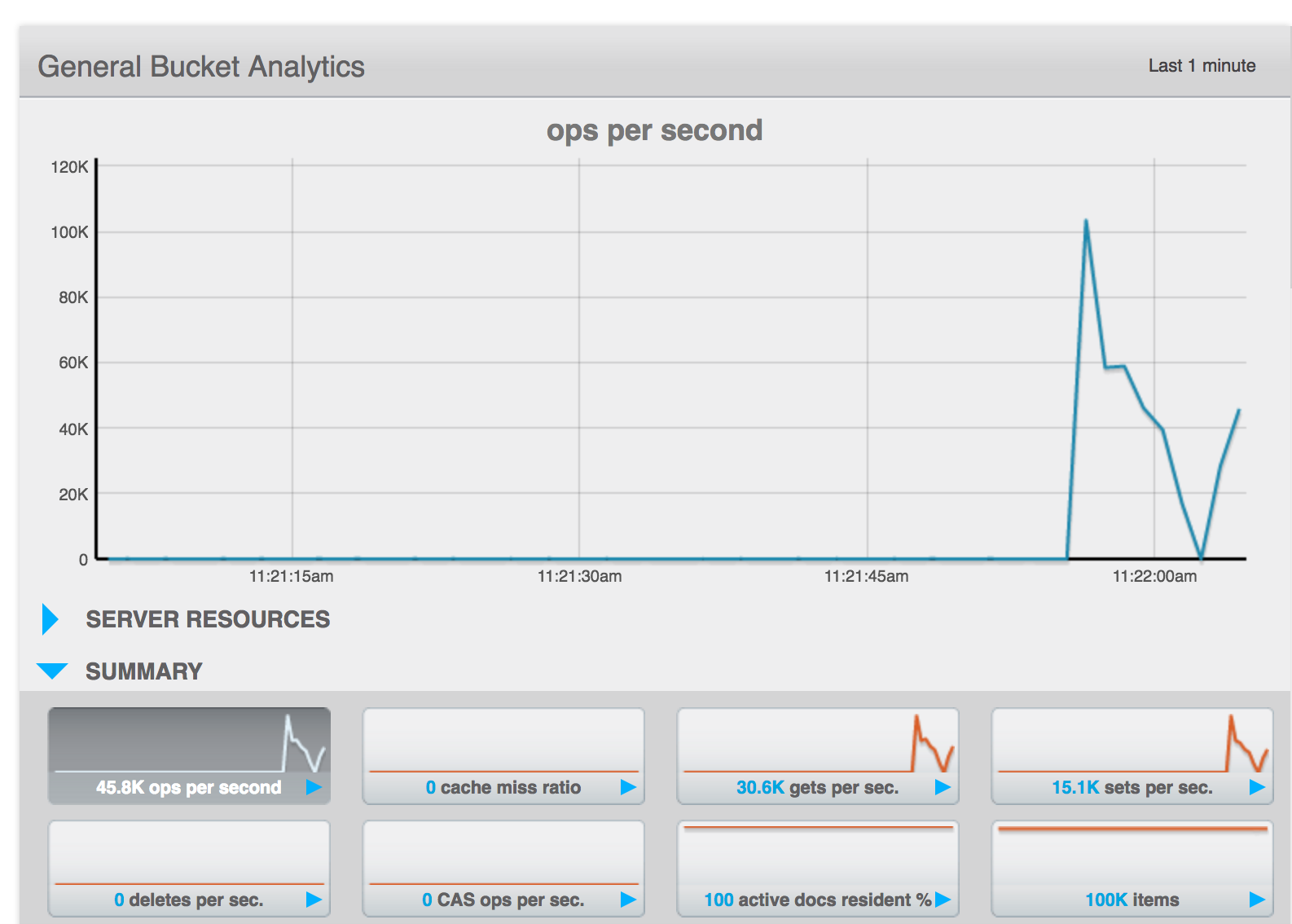
- Screenshots showing the traffic load at different stages (pre node down, during node down/failover, after rebalance started)
Server side logs are available:
https://s3.amazonaws.com/cb-customers/tom/collectinfo-2017-04-01T102252-ns_1%40ec2-34-248-41-12.eu-west-1.compute.amazonaws.com.zip
https://s3.amazonaws.com/cb-customers/tom/collectinfo-2017-04-01T102252-ns_1%40ec2-52-30-209-45.eu-west-1.compute.amazonaws.com.zip
https://s3.amazonaws.com/cb-customers/tom/collectinfo-2017-04-01T102252-ns_1%40ec2-52-31-18-152.eu-west-1.compute.amazonaws.com.zip
Attachments

| For Gerrit Dashboard: CCBC-766 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 76201,4 | CCBC-766: Fix stuck CCCP subsystem. | master | libcouchbase | Status: MERGED | +2 | +1 |