Details
-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
None
-
Mobile 3.0, Mobile 3.1
-
None
Description
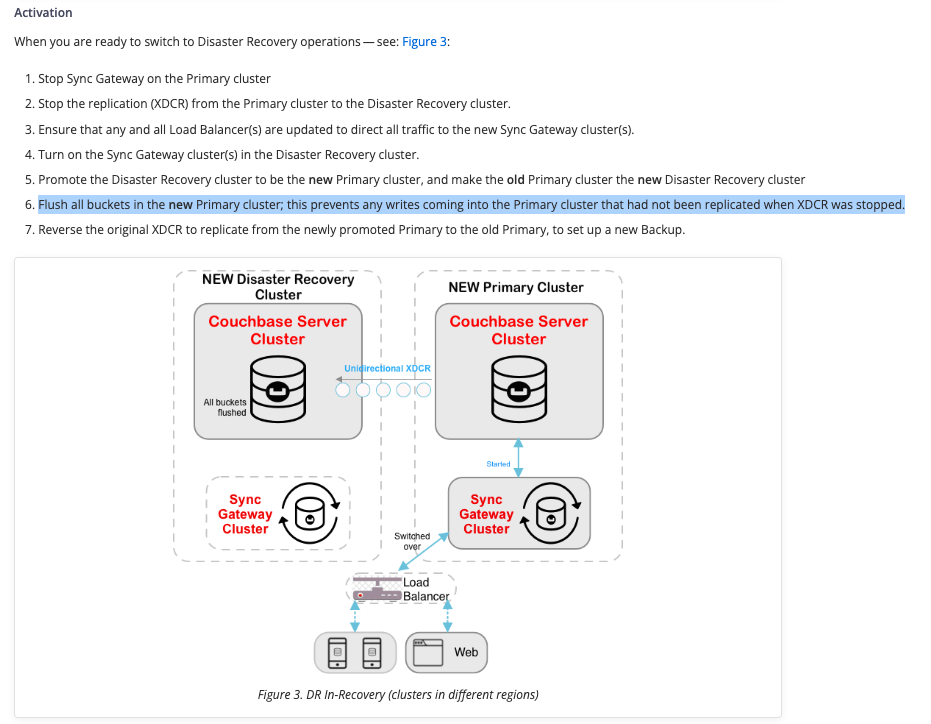
Pages incriminated are Sync Gateway doc pages 3.0 and 3.1:
https://docs.couchbase.com/sync-gateway/3.0/deploy-dr-cluster.html
https://docs.couchbase.com/sync-gateway/3.1/deploy-dr-cluster.html (current doc page)
Problems
Reading this doc page I think there is 2 major issues on line 6 of section Activation:
- FIRST ISSUE: Wrong cluster :
6. Flush all buckets in the new Primary cluster; this prevents any writes coming into the Primary cluster that had not been replicated when XDCR was stopped. |
Beginning of sentence is wrong, it should be “Flush all buckets in the (old) Primary cluster” OR “Flush all buckets in the new Disaster Recovery cluster”
Note that this other (quite similar) doc page https://docs.couchbase.com/sync-gateway/current/setting-up-dr-cluster.html does NOT have this 1st issue. Indeed it is mentioned there:
Flush all replicated buckets in the Primary cluster; as a precaution against any spurious writes coming into the Primary cluster that had not been replicated when XDCR was stopped.
|
2. SECOND ISSUE
The justification of the flush is not OK for me: IF you are relying on XDCR Timestamp resolution conflict strategy, then even if we suppose some data “had not been replicated when XDCR was stopped”, there will be no XDCR syncing issue between the NEW Primary Cluster and the NEW Disaster Recovery cluster.
I cannot see from where spurious writes may come... : any write made in the NEW Primary Cluster are now synced to the NEW Disaster Recovery cluster.
All that to say : does step 6 still apply? I would say NO. So personally I would recommend removing step 6, unless there is a real justification (please provide details) of the need for flushing buckets on the NEW Disaster Recovery cluster.
Also I would like to add that, if a flush is really needed (which I doubt), then :
- re-populating the NEW Disaster Recovery cluster from scratch will take some times (some seconds or minutes in case customer has NOT a lot of data => OK that's acceptable)
- re-creating GSI indexes (not to mention FTS indexes) could take hours if not days.
So it means that, once the 1st DR cluster is used, our customers MUST live without any DR cluster (i.e. the “NEW Disaster Recovery cluster”) ready for hours/days, which seems not acceptable.
Discussion about those 2 issues and my proposal on slack #mobile-support channel:
https://couchbase.slack.com/archives/C0N7DCWM8/p1704382413701649
Thanks.