Description
Couchbase Cluster Description
- Set up the cluster as per the required specifications
- Each node is an m5.4xlarge instance. (16 vCPUs and 64GB RAM)
- 6 Data Service, 4 Index Service and Query Service Nodes.
- 10 Buckets (with 1 replica), Full Eviction and Auto-failover set to 5s.
- ~210GB data per bucket → ~2TB data loaded onto cluster.
- 50 Primary Indexes with 1 Replica each. (Total 100 Indexes)
- DeltaRecovery Upgrade to update Couchbase Server from 7.2.5 to 7.6.1
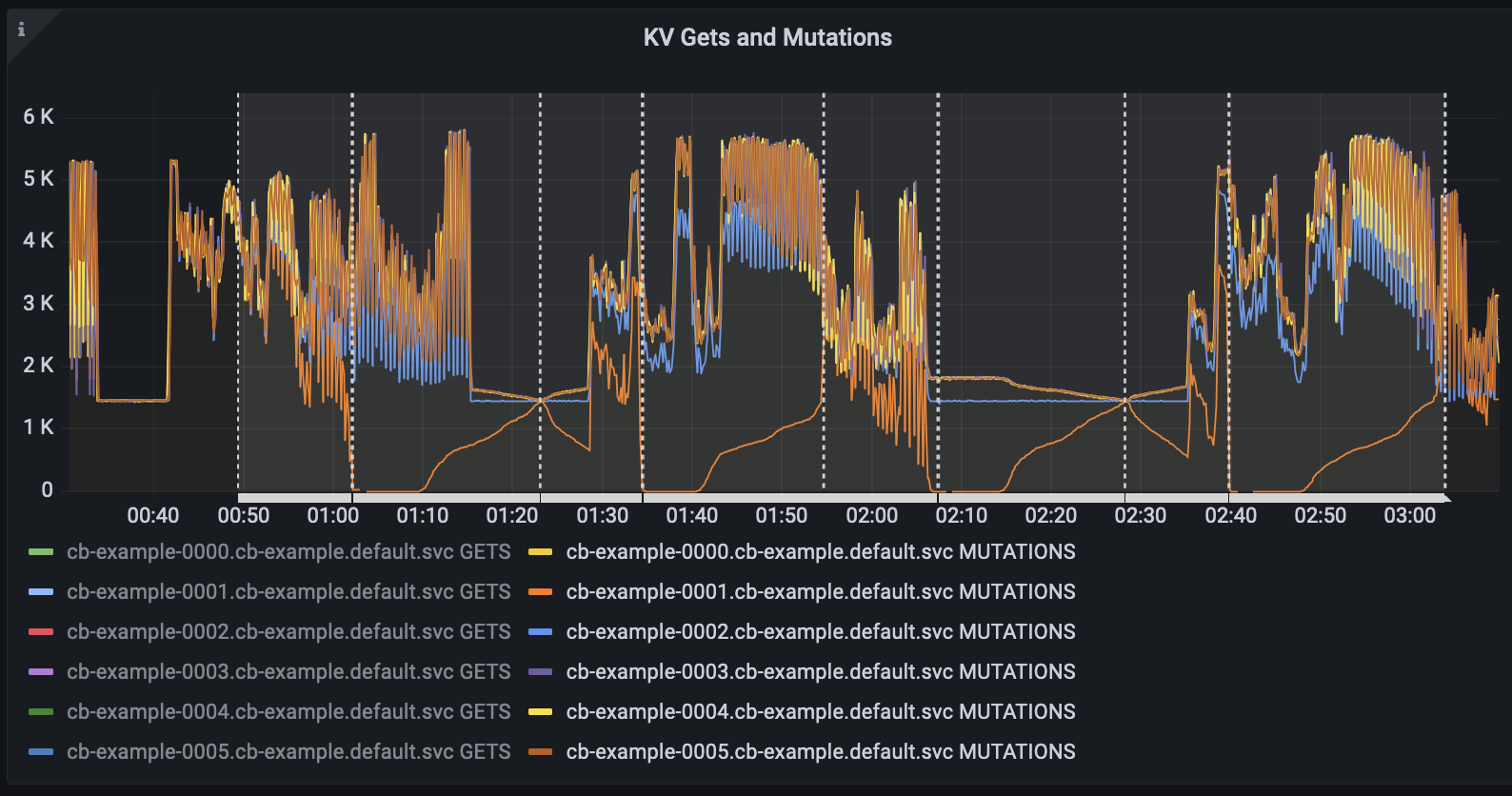
- Continuous data and query workload on all buckets during the update process.
Current:-
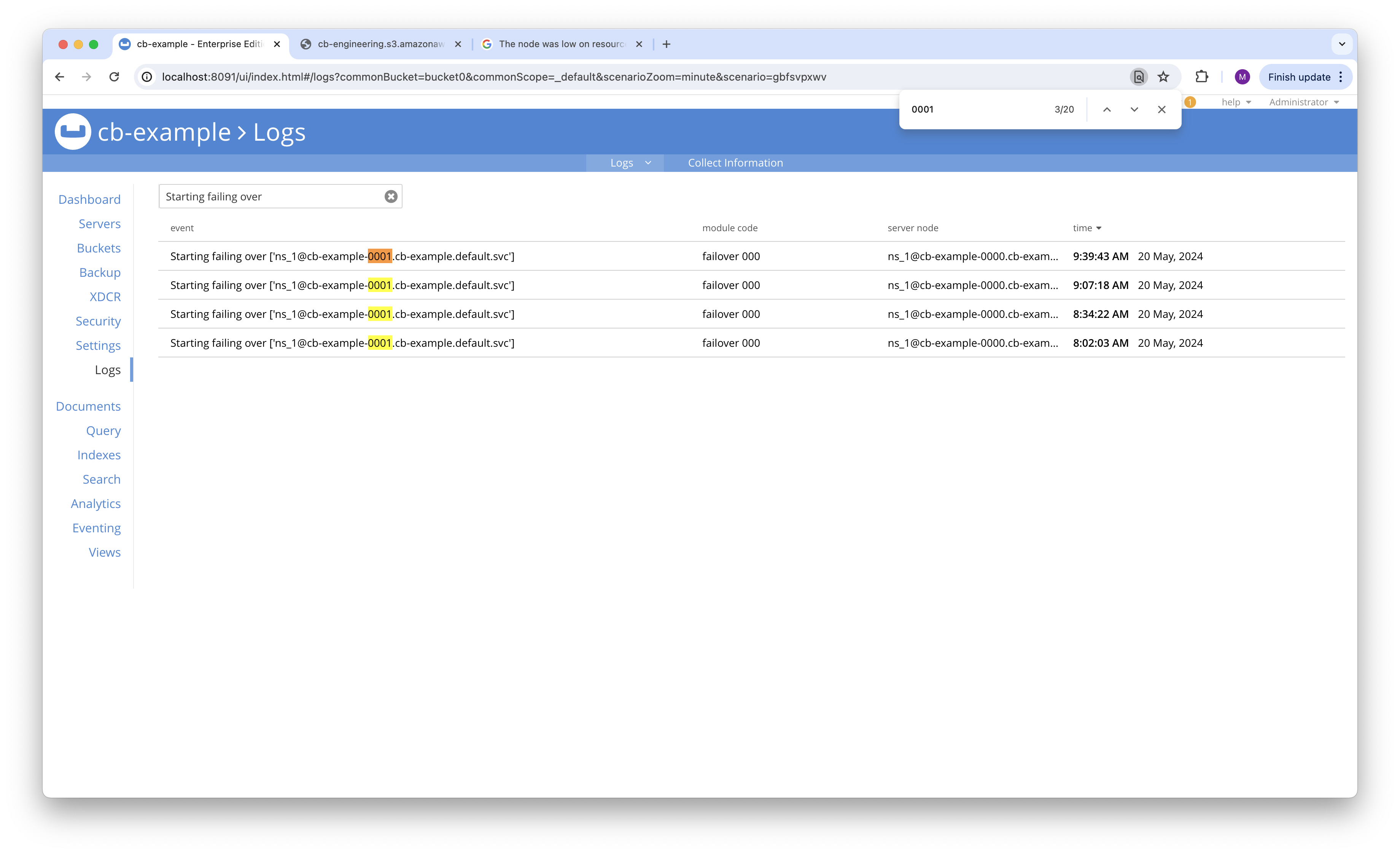
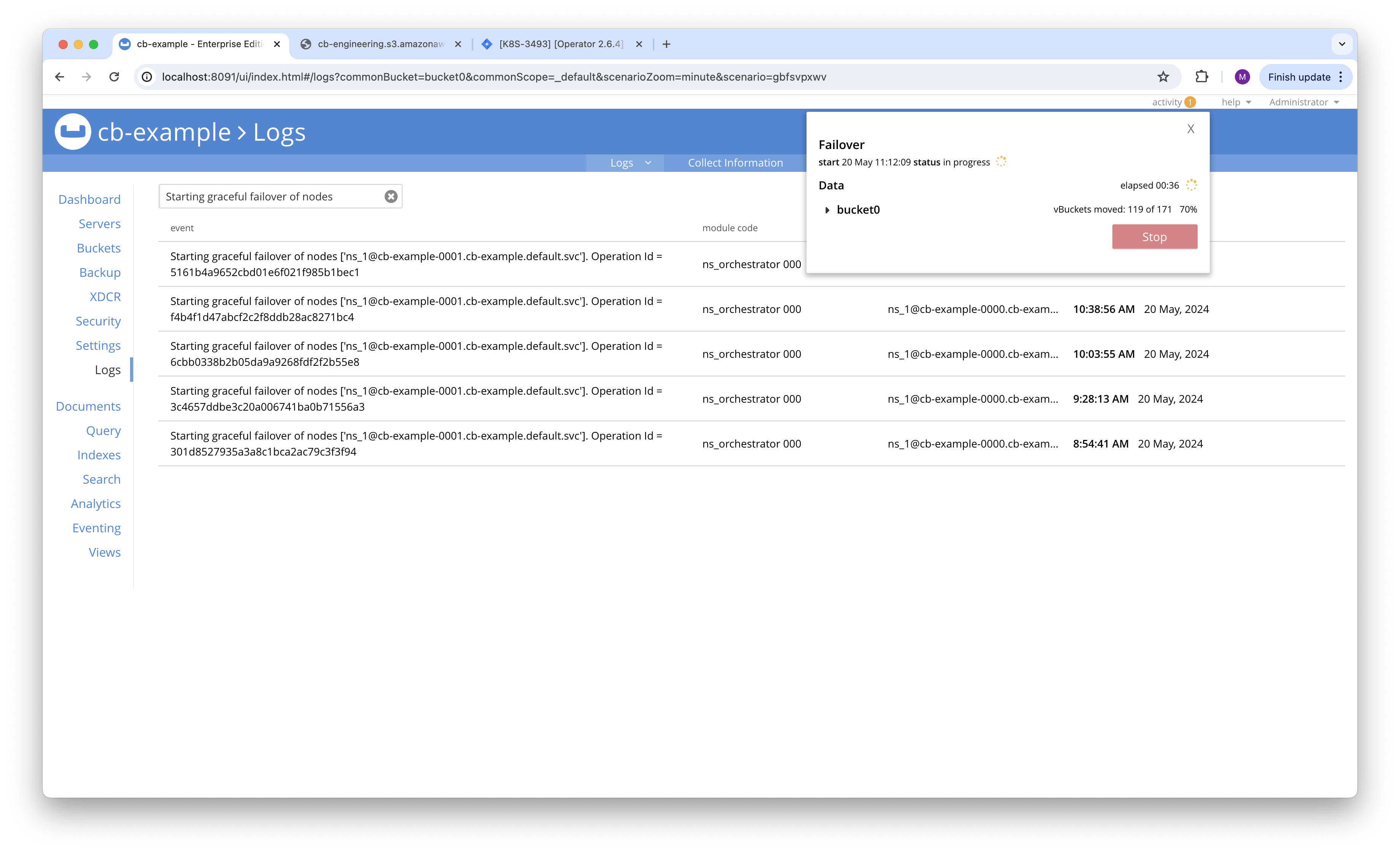
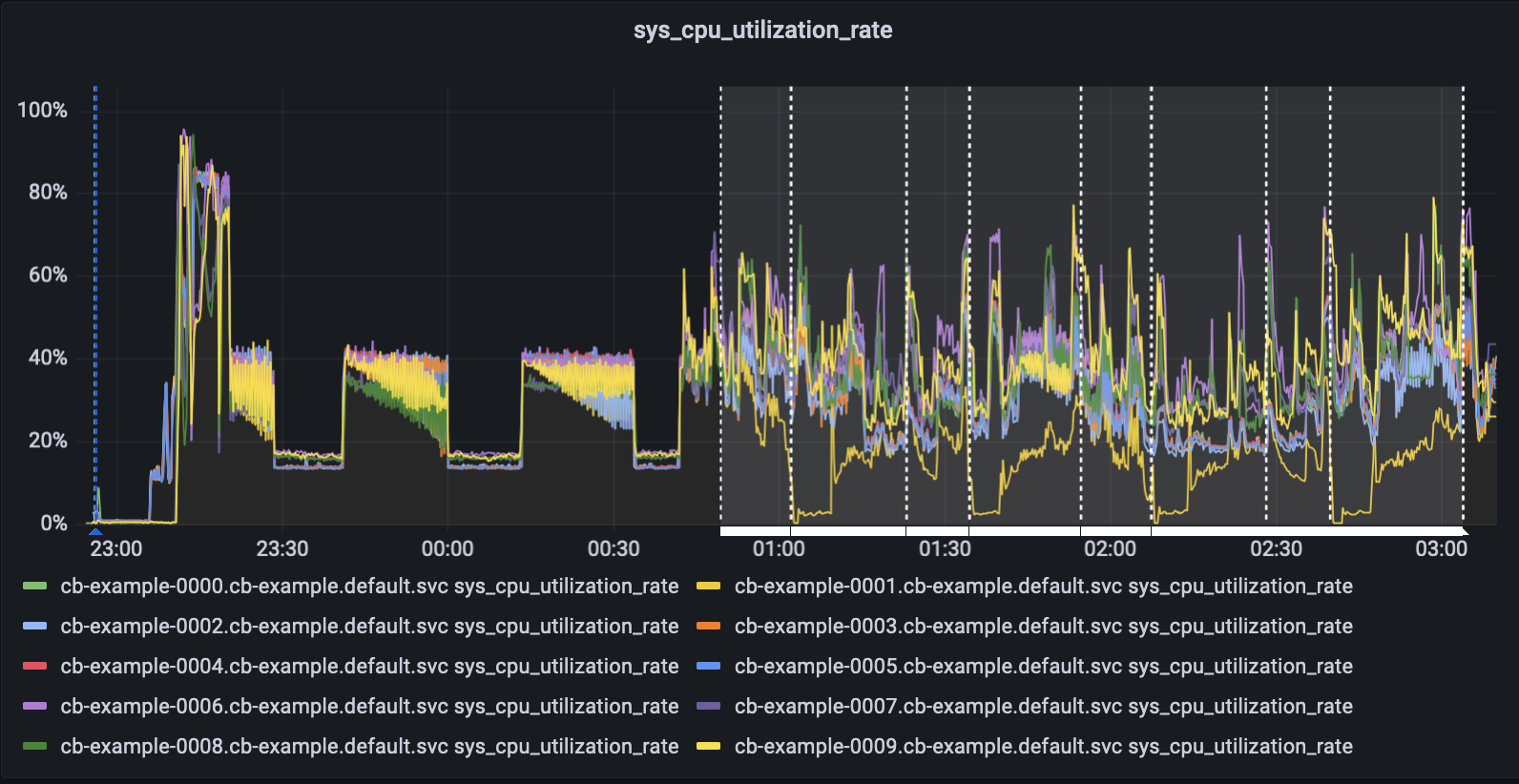
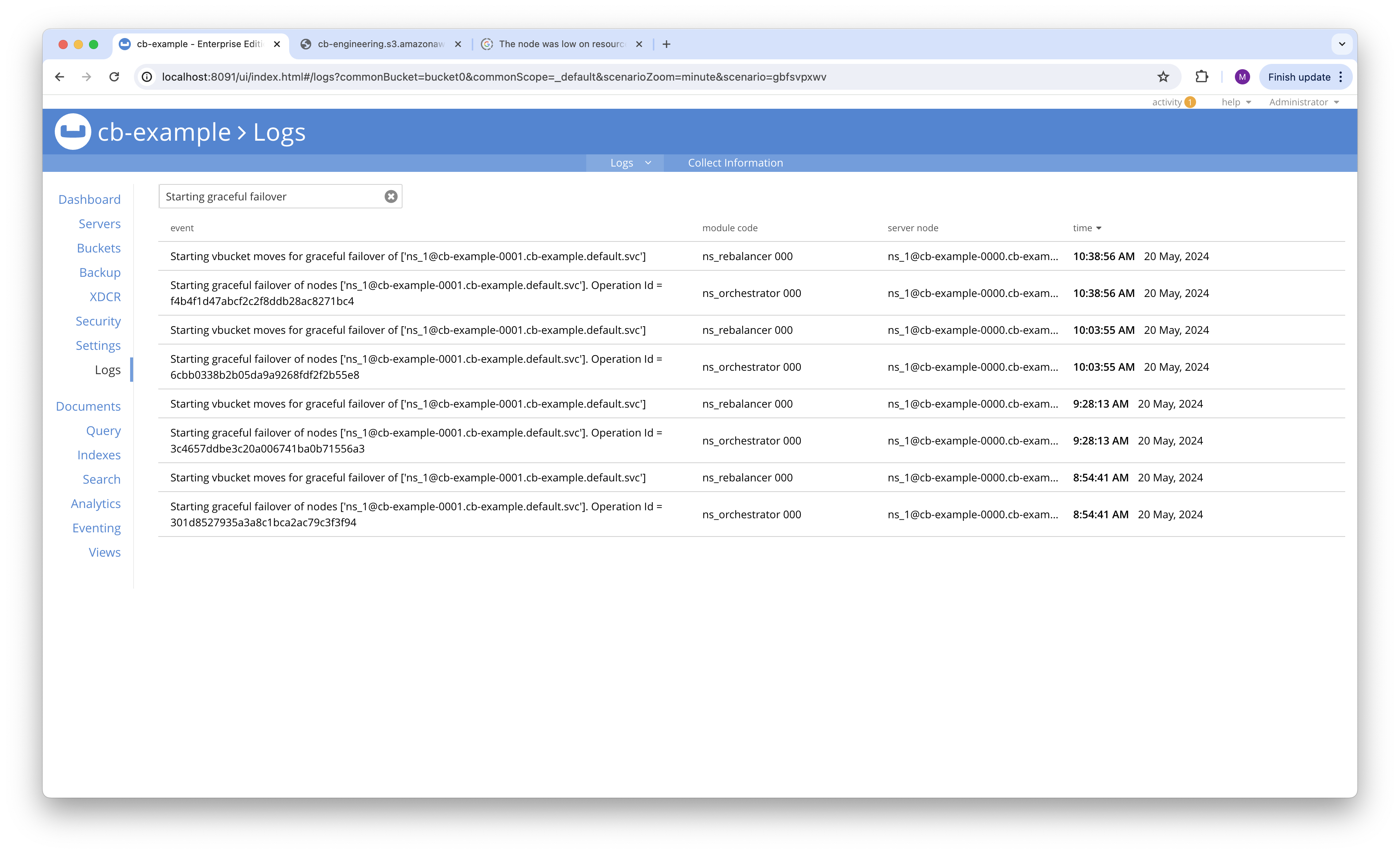
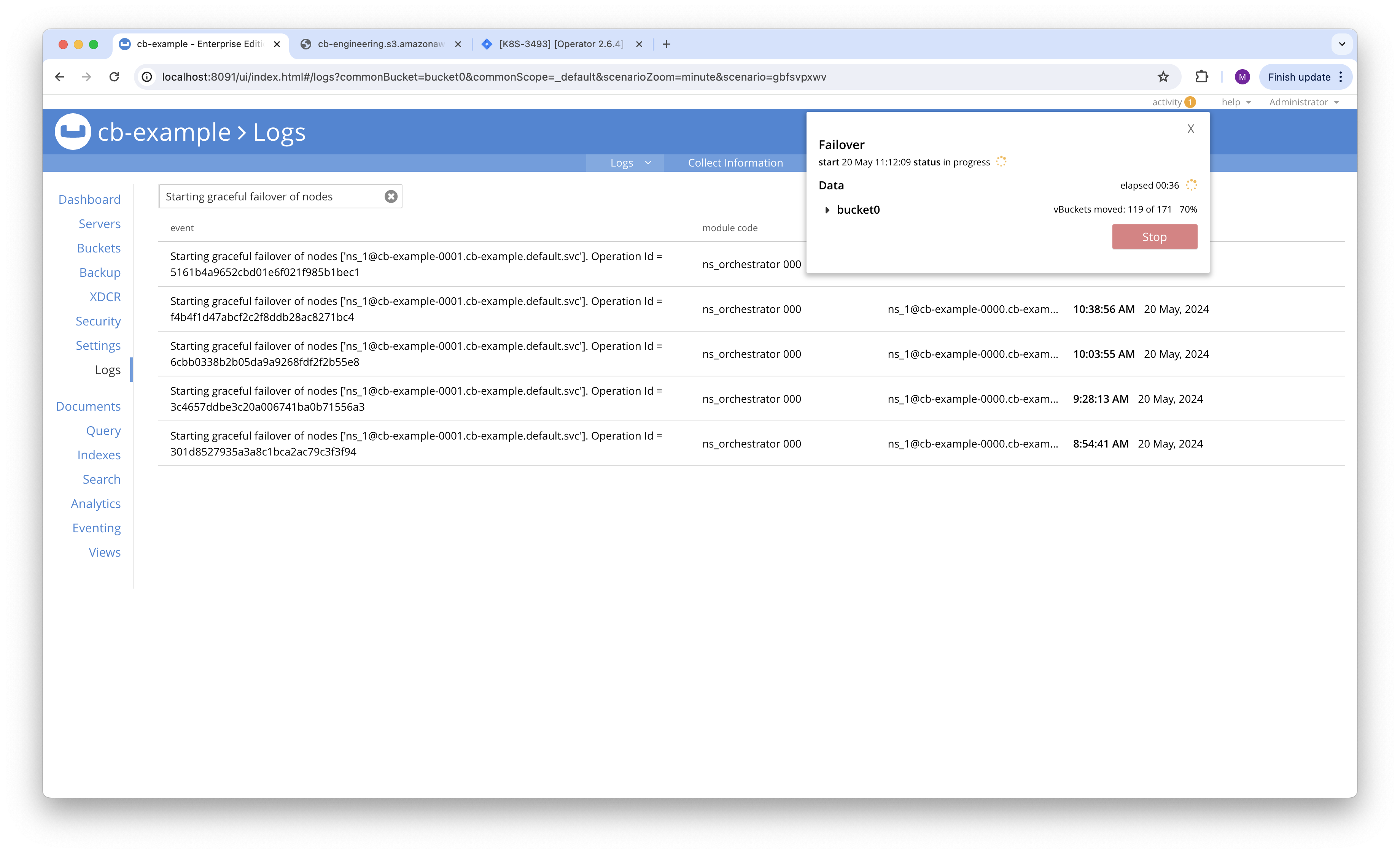
- Node 0001 is graceful failover in loop.
- Node 0001 is still staying at 7.2.5 even after 3-4 graceful failovers.
Expected:-
- Node 0001 should be upgraded to 7.6.1 after successful graceful failover and rebalance.
- Whole Cluster should upgraded to 7.6.1
Follow Ups:-
1. Is there a limit of retrying on which operator will stop upgrade and inform the users ?
#0001 graceful failover : 4
#0001 graceful failover : 5
CB Logs Pre upgrade - http://supportal.couchbase.com/snapshot/eb81ca9e079b0c90bf92068cb8ca76b3::0
CB Logs During Upgrade (stuck) -
supportal Link-http://supportal.couchbase.com/snapshot/eb81ca9e079b0c90bf92068cb8ca76b3::1
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0000.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0001.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0002.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0003.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0004.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0005.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0006.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0007.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0008.cb-example.default.svc.zip
https://cb-engineering.s3.amazonaws.com/K8S-3492-no-progress-in-upgrade/collectinfo-2024-05-20T100447-ns_1%40cb-example-0009.cb-example.default.svc.zip
Operator logs :-
{"level":"info","ts":"2024-05-20T09:28:13Z","logger":"cluster","msg":"Upgrading pods with DeltaRecovery","cluster":"default/cb-example","names":["cb-example-0001"],"target-version":"7.6.1"}
|
|
|
{"level":"error","ts":"2024-05-20T09:33:14Z","logger":"cluster","msg":"Reconciliation failed","cluster":"default/cb-example","error":"timeout: task is currently running","stacktrace":"github.com/couchbase/couchbase-operator/pkg/cluster.(*Cluster).runReconcile\n\tgithub.com/couchbase/couchbase-operator/pkg/cluster/cluster.go:498\ngithub.com/couchbase/couchbase-operator/pkg/cluster.(*Cluster).Update\n\tgithub.com/couchbase/couchbase-operator/pkg/cluster/cluster.go:535\ngithub.com/couchbase/couchbase-operator/pkg/controller.(*CouchbaseClusterReconciler).Reconcile\n\tgithub.com/couchbase/couchbase-operator/pkg/controller/controller.go:90\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Reconcile\n\tsigs.k8s.io/controller-runtime@v0.16.3/pkg/internal/controller/controller.go:119\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler\n\tsigs.k8s.io/controller-runtime@v0.16.3/pkg/internal/controller/controller.go:316\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem\n\tsigs.k8s.io/controller-runtime@v0.16.3/pkg/internal/controller/controller.go:266\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Start.func2.2\n\tsigs.k8s.io/controller-runtime@v0.16.3/pkg/internal/controller/controller.go:227"}
|
|
|
{"level":"info","ts":"2024-05-20T09:33:14Z","logger":"cluster","msg":"Resource updated","cluster":"default/cb-example","diff":"+{v2.ClusterStatus}.Conditions[?->3]:{Type:Error Status:True LastUpdateTime:2024-05-20T09:33:14Z LastTransitionTime:2024-05-20T09:33:14Z Reason:ErrorEncountered Message:timeout: task is currently running}"}
|
Operator Logs :-
cbopinfo-20240520T151320+0530.tar.gz![]()
Attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Issue Links
- is caused by
-
K8S-3492 1.25+7.25 -> 1.25+7.6.1 (delta recovery)
-

- Resolved
-
- relates to
-
K8S-3472 Operator needs more robust way to detect outcome of graceful failover
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
- mentioned in
-
Page Loading...